@Embedding-based Product Retrieval in Taobao Search
淘宝搜索的向量召回特征包括语义特征与个性化特征。
-
语义特征基于query和item title,#card
-
不同的是query侧使用多粒度的文本encoder,同时增加当前query的补充term(历史query,这里可能是历史统计得到的相似query),
-
而item侧语义特征则仍然使用title terms。
-
-
个性化特征#card
-
user/query侧使用实时、短期、长期的用户行为(点击过的商品、店铺等),
-
item侧则直接通过itemId获得商品embedding与语义特征拼接融合。
-
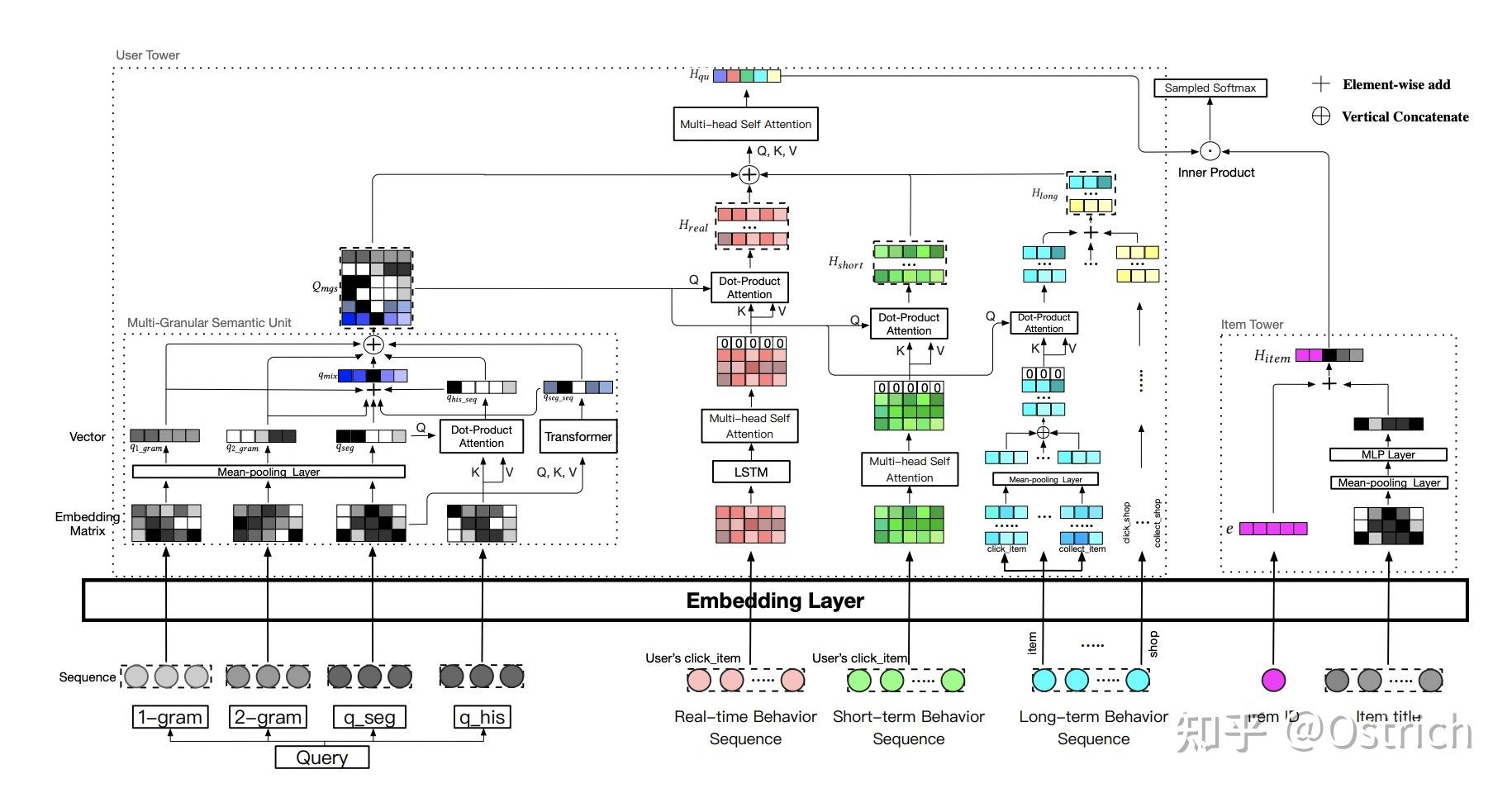
-
模型同样是双塔结构,
-
User tower的向量表示 #card
-
user/query侧一方面使用query多粒度term进行embedding映射,包括 1-gram,2-gram,query terms(q_seg)以及补充的query terms(q_his)。
-
此外,q_his的输入先经过和qseg的attention得到 ,q_seg同样也会通过Transformer得到深度的语义特征 。
-
最后各粒度特征通过加和,concat得到不同粒度的query表示向量矩阵 ,而后 分别和实时,短期,长期的用户行为的特征表示做multi-head attention,最后得到。
-
-
商品的表示比较简单,#card
- 使用itemId embedding和title terms embedding拼接得到。
-
不同于使用hinge loss或者tripe loss,本文使用sampled softmax cross-entropy loss来进行模型训练,#card
-
期望得到全局的正负样本距离度量,以尽可能的实现训练和预测分布的一致性(pair wise loss则更关注局部的正负样本距离度量)。
-
-
-
\hat{y}{\left(i^{+} \mid q_u\right)}=\frac{\exp \left(\mathcal{F}\left(q_u, i{+}\right)\right)}{\sum_{i{\prime} \in I} \exp \left(\mathcal{F}\left(q_u, i^{\prime}\right)\right)}, \
L(\nabla)=-\sum{i \in I} y_i \log \left(\hat{y}_i\right),
\end{gathered}
样本构造 + 训练数据使用点击日志,点击数据为正样本,由于使用了sampled softmax,负样本相当于从商品池中随机采样。#card + 难样本挖掘:人为对负样本加权#card + 对随机负样本query-item pair对进行模型预测(中间模型),取Top-N的内积score的item向量表示集合 I + 正样本 i+,线性相加得到难负样本表示 Imix + alpha 平衡样本的难度 由于引入了个性化特征、记忆性的Id特征,模型不可避免地引入相关性badcase(其实不加个性化特征也免不了)。因此策略上线时还做了一些额外的相关性控制策略#card + 通过核心term(如品牌、颜色、型号等属性)匹配限制,避免模糊匹配带来的语义漂移等问题 
@Embedding-based Product Retrieval in Taobao Search
https://blog.xiang578.com/post/logseq/@Embedding-based Product Retrieval in Taobao Search.html