[[@天涯kk的房产预言到尾声了吗?2022年以后还会重复2015的普遍暴涨吗? - 知乎]]
待分类
调控
政府
经济
政策
税
[[体制内外]]
租房
买房
股市
历史
— 没有整理
[[关于垄断]]
[[民生问题]]
[[房产税的制定原则]]
[[维稳的本质是人民能吃饱饭]]
[[公租房是为体制内服务的]]
[[房产税一定会转嫁给租房人]]
[[巨大的税收消耗也决定了GDP必须快速增长 & 公务员越精减越多]]
[[体制内的住房问题有国家保驾护航]]
[[依靠但又不能完全依靠开发商建公租房]]
[[解决体制外的住房问题:国家垄断,细水长流收租]]
[[普通人买得起「优质商品房」就尽早买把]]
[[商品房和公租房的区别]]
[[提议通过征普税调节贫富差距,不是傻,就是坏]]
[[调控带来的影响]]
[[农产品的价格关系到影响稳定的吃饭问题]]
[[农产品价格的抬头会导致物价全面上涨,但国家不会坐视不管且有能力管]]
[[资金会在优质资产之间流动,而决定优质资产价格的是精英阶层的购买力]]
[[资金流向规律决定了农产品和资产价格总有一个要涨,人为压制,一定会按下葫芦浮起瓢]]
[[资金流向规律决定了洼地不会一直是洼地]]
[[决定房价的因素有很多,具体情况具体分析]]
[[房价暴涨是相对于钱而言的,不是相对于实际购买力而言的]]
[[土地不稀缺,优质土地稀缺]]
[[集中发展大城市是导致优质土地稀缺的原因]]
[[为人民服务是说给人民听的]]
[[历史是一面镜子,不同的国情决定了采取同样的政策结果可能是南辕北辙]]
[[屁股决定脑袋,人民不知厉害关系选房子,政府选农产品]]
[[各个阶层的住房问题都安排的妥妥的]]
[[底层指的是体制外底薪白领]]
[[资金终会流向具有稀缺性的资产]]
[[一二线买房只会越来越难,最终租房会成为主流]]
[[如果房价不涨,那其他产品会怎么涨]]
[[政府如何利用公租房控制租房市场]]
[[城中村不会长期存在]]
[[稀缺房的价格永远涨]]
[[房地产是资本市场还是实体经济?]]
[[房价是否会跌,如果会,会怎么跌]]
[[通货膨胀是减缓灭亡最好的良药]]
[[经济问题是导致清朝灭亡]]
[[房产投资的几点建议]]
[[南宁买房建议]]
[[经济适用房都是内部分配的]]
[[普通人怎么办:尽早买房,努力挣钱抵御通胀]]
[[买房时机的选择(真TM厉害,这竟然是2010年的建议,可恨的是2020年才看到)]]
[[永远不要和白痴争辩,因为他会把你的智商拉到和他同一水平,然后用丰富的经验打败你]]
[[当个农民也要懂政策,要顺政策而为]]
[[利益才是政府行为的指挥棒]]
[[建议一定是建立在严肃考察的基础上]]
[[石家庄]]
[[投资最重要的是稀缺性,买房首选公务员小区]]
[[远离垃圾人]]
[[要用发展的眼光看问题,只要努力,只会越来越好,越来越轻松]]
[[性格决定命运]]
[[2012年不取消调控,还有房价维稳顺利换届考虑]]
[[洼地最终都会被填平,多数城市是早买胜于晚买]]
[[西部]]
[[短期波动属于正常现象,需要关注的是长期趋势]]
[[早买的风险小于晚买]]
[[小开发商的房子能不能买?]]
[[天子脚下:二手老房买得好,拆迁补偿少不了]]
[[君为贵,商人、技工次之,农民为轻,打工人为底]]
[[历史总是惊人的相似]]
[[买卖商品房会逐渐变成富人的游戏]]
[[政府还是更在意农民问题]]
[[治国需要用贪官、反贪官]]
[[二线城市典型代表]]
[[关于商铺和住宅投资]]
[[关于房产调控]]
[[关于房产税]]
[[老公房的拆迁问题]]
[[投资新房还是老公房]]
[[高端盘有房价带动作用]]
[[买房和没买房的差距]]
[[房产交易历史]]
[[契税的历史]]
[[廉租房的历史]]
[[未来房地产市场的发展]]
[[房产到期]]
[[历史的结局]]
[[人口普查]]
[[买房难之回不去的乡 & 拉美人过得比你想象的好]]
[[北京西三旗]]
[[买房争取一步到位]]
[[收入稳定的家庭如何买房]]
[[贷款还是全款]]
[[00后的买房需求从何而来]]
[[意大利的住房模式]]
[[北京远洋山水]]
[[精英的资产]]
[[北京三环塔楼]]
[[普通人买房的未来]]
[[北京房价超香港]]
[[中国的新闻不可信,精英的有钱是你想象不到的]]
[[限贷对精英没用]]
[[外国国籍在中国生活是更好的选择]]
[[读史读的不是故事,还是找历史规律,以古鉴今]]
[[贵阳]]
[[富人越富、穷人越穷]]
[[深圳 & 昆明仇书记 & 通货膨胀体制内高枕无忧、体制外自求多福]]
[[长春]]
[[佛山]]
[[首付提高的逻辑]]
[[四线城市]]
[[苏州工业园]]
[[住房公积金利率]]
[[公务员小区牛逼]]
[[命运之矛]]
[[除非外族入侵或全国大饥荒,否则双轨制决定了房价不会崩盘]]
[[宋代房奴]]
[[什么是社会公平]]
[[还是有很多有钱人]]
[[开发商思维]]
[[郑州有前景]]
[[张献忠屠川]]
[[洪秀全、黄巢、李自成]]
[[朱元璋]]
[[曹参治国]]
[[民营小企业的老板和打工者]]
[[郭解]]
[[2010年的中国房地产]]
[[精英人群的平均收入决定房价]]
[[内地不是香港、海南]]
[[历史是一面镜子]]
[[买房一次性到位比较好]]
[[一线和二线]]
[[小产权房]]
[[商铺和住宅]]
[[体制内外]]
[[买房:物业与房贷]]
[[收紧住房贷款]]
[[买房:物业与房贷]]
[[体制内的28原则]]
[[贾谊]]
[[年轻人要早买房]]
[[不要低估通货膨胀]]
[[二三线城市与重庆]]
[[城区和郊区]]
[[守着金碗要饭吃]]
[[人制的社会,人就是制度]]
[[准公务员的好处]]
[[一线杭州]]
[[转篇文章:一个忽悠了几亿中国人的伪概念:所谓“中国房地产泡沫”]]
[[拆迁补偿]]
[[城市底层]]
[[农村自来水]]
[[袁盎]]
[[二三线城市,选新城还是老城]]
[[在中国,普通人手上闲钱不多的人被剥削]]
[[三分天注定七分靠打拼]]
[[人的前程有的时候不掌握在自己手里]]
[[西安与重庆]]
[[谢国中「空置率」]]
[[打工不如有一技之长的小老板]]
[[讲故事含沙射影ZG之房子不属于市场经济]]
[[西五环内的别墅,是相当稀缺的资源]]
[[调控降房价是刚需的一厢情愿]]
[[房价持续上涨的本质是稀缺性让好房子成为资金最好的去处]]
[[民生问题]]
[[房产税的制定原则]]
[[维稳的本质是人民能吃饱饭]]
[[垄断可以控制价格,维持稳定]]
体制内的住房问题有国家保驾护航 #card
在私企打过工的都知道,毫无归属感可言,老板脑袋一发热,随时让员工卷铺盖卷走人。那是要多没保障有多没保障。原因是社会关系,关键客户,都掌握在老板一个人手里,员工就是打个下手,一不爽了,就换人呗。
统治者可知道不能这么用人的。一个庞大的国家机器要想正常运转,必须得让手下的和自己的利益一致。如果自己吃肉,手下的连汤都没得喝,这个机器就转不动了。
因此,在房价高涨的时代,保障房才成为中央默认的公务员房、垄断企业房。
公租房首要解决的就是手下里面最底层人士的住房问题。
我认为针对于体制内来说,无论是公务员,事业单位,还是国有企业的初级员工,都可以通过所在单位申请公租房,公租房的租金会略低于市场,主要是单位一定会提供补贴。
体制外对公租房的申请就没有那么幸运了。
[[体制内的住房问题不难解决]]
[[农产品价格的抬头会导致物价全面上涨,但国家不会坐视不管且有能力管]]
资金会在优质资产之间流动,而决定优质资产价格的是精英阶层的购买力 #card
- 一线城市仍然沉默,国家队在积极运动。二三线城市的房价上涨的成交量的回升却给了市场一个明确的信号。这是资金运动的规律。国家队对一线城市的布局,迫使资金流向二三线城市。二三线城市相对(与一线城市相比)不高的价位给出了较大上升空间的预期。
全国富人买北京上海,全省富人买省会,房价的合理性已经不能用简单的本地平均收入来衡量。精英阶层的购买力才是关键。
资金流向规律决定了农产品和资产价格总有一个要涨,人为压制,一定会按下葫芦浮起瓢 #card
在资金总量不变的前提下,巨量资金推动农产品价格上涨或者推动房价上涨是一个必须的选择。
今年政府用行政手段严厉打击蒜和绿豆价格的暴炒,基本上没有起到作用,资金有自己的运作规律,光靠拿张悟本出气也不能解决问题。
资金流向规律决定了洼地不会一直是洼地 #card
- 二三线城市的房价的上涨使与一线城市的差价缩小,为一线城市的发力提供了动能。
无论你喜欢还是不喜欢,都不是以人的意志为转移的
房价暴涨是相对于钱而言的,不是相对于实际购买力而言的 #card
。。。。。。暴涨之后。。。。。。
我们不就是第二个日本吗?
供求关系?供求关系,现在是谁在决定?国家!
国家的经济结构决定的。制造业的资金都进入房地产了。能不涨吗?普通人有几个可以够炒房资格的?
日本 当初也是供求关系!~~ 供求关系的根本也不应脱离,国家的经济实力!!
还暴涨?怎么涨?再涨都够去美国买房了!! 你这不扯淡么
kkndme:
中国和日本最大的不同在于日本的货币是开放的,中国的不是,是不能自由兑换的。
暴涨是相对于钱而言的,不是相对于实际购买力而言的。
80年代工资200多块钱一个月的时候,是不能想象90年代末北京城区5000每平米的房价的。那时候万元户已经是富人的代表了。
90年代末工资1000块钱的时候是不能想象现在30000一平米的房价的。90年代的100万绝对是富裕群体。可现在连个中产都算不上。
货币的持续贬值你没有考虑
集中发展大城市是导致优质土地稀缺的原因 #card
- 中国经济发展不平衡,牺牲全国大多数城市和乡村,来保证北上广深及大部分省会城市的繁荣才是造成土地稀缺的愿意。
土地有的是,房子有的是,但好位置的土地和房子并不多。
一方面大量的小县城和乡镇、村庄人口锐减,因为缺乏谋生手段不得不背景离乡外出打工,另一方面超大型城市越来越拥挤,土地资源越来越稀缺。
这就是中国集中发展极少数标杆城市所造成的呀,也是因为如此,才造成了中国金子塔式的收入结构,贫富差距越来越悬殊。
历史是一面镜子,不同的国情决定了采取同样的政策结果可能是南辕北辙 #card
- 博古才能通今,不了解历史无法治理国家,不了解历史也无法对事务有一个清楚的认识。
我们的今天本来就是历史的延续,前人经验和智慧的总结,不是一句话就可以抹杀的。
因为秦以后漫长帝国时代的大一统,才会把中央集权延续到现在。
而西方封建时代延续到地理大发现,诸侯割据王国、公国、侯国林立为现代的西方提供了民主制度的可能。
在制度上完全的不可比性,使向国际接轨成为了笑话。
我们看到的结果就是,物价上涨与西方接轨,甚至堂而皇之的超过西方,体制外的工资则与非洲结果,也算是国际化了。
屁股决定脑袋,人民不知厉害关系选房子,政府选农产品 #card
- 对于渴望拥有一套产权住房的都市小白领对希望房价狂降已经到了歇斯底里的程度,他们赞成农产品价格放开,让资金炒作农产品,而离开房地产市场。理由很简单,一套房子一涨就是几十万甚至上百万,而大米小麦,一斤就算涨到10块,也根本不能影响到自己的生活质量。
如果我国农产品价格是开放的,资金流向大米、小麦、猪肉,并且允许囤积,房地产一定会下跌的,这是毫无疑问的。
但是,我们看到的绝不是10块钱一斤的大米、小麦,而是500块钱、1000块钱一斤的大米、小麦。
我国将会出现大面积的饥荒,几千万甚至上亿的底层人士饿死街头,社会将出现大的动荡。
而产权房屋价格的上涨牺牲的主体只是体制外部分都市白领的利益,换来的不过是网络上没完没了的牢骚和咒骂。
巨量资金必须有地方去,如今面临的房地产和农产品之间的选择,你认为政府会怎么做?
各个阶层的住房问题都安排的妥妥的
体制内中层、高层可以分到多套福利房,低层至少能够分到一套保障房,即使最不重要部门的底层员工,搞到由单位补贴的公租房是没有问题的。
体制外的高层、中层,以他们的资金实力买多套房子都是不成问题的。
农民,分配有宅基地。国家要稳定,首先就是要农民稳定,因此我国只有农民能够分到土地自己盖房子。
军人,会享受到比公务员更好的福利,让军人享受更高标准的福利待遇,国家有深刻的认识。
那么只有体制外的都市中下层群众才是高房价的受害者,可是这个群体的地位真的很微不足道。#card
一二线买房只会越来越难,最终租房会成为主流 #card
- 在北京一个年薪15万的普通家庭仍然买的起房,在五环外,只是你愿不愿意买。
- 但以后一个年薪15-20万的普通家庭买房子,即使是五环外的,也只能是梦想了。
- 租房将成为今后小白领主流的生活方式。
[[如果房价不涨,那其他产品会怎么涨]]
[[城中村不会长期存在]]
[[权利让革族成为苗族的一支]]
房价是否会跌,如果会,会怎么跌
几天没有上来,发现来了很多比较鸡冻的同志。心情可予以理解。
但是鸡冻并不能让日子过的更好。
油价大涨小跌,我们鸡冻了,但是事实并没有改变。
高速费早就收回成本,可是依然雷打不动的收着,我们鸡冻了,可是事实也没有任何改变。
房价就能真如很多人所愿,使劲跌到人人买的起吗?今后的现实将告诉我们答案。
房价会不会跌?
我说在较远的将来一定会跌,但下跌的方式是完全不同的。不可能象大家所期望的由2010年的30000一平跌到2004年的6000一平。
下跌一定是另一种方式:当农产品价格以几年翻10倍甚至几十倍的速度上涨的时候,房产却相对滞涨。这是最有可能的下跌方式。#card
通货膨胀是减缓灭亡最好的良药
最善良的意愿并不能阻止事务向邪恶的方向发展。
我们大家都很清楚却都没关注的一个常识,当我们满怀热情无偿献血的时候,有哪个贫穷的患者在需要输血时,能够因为广大群众的无偿献血而得到医院的优惠吗?
不能,无论你是穷是富,只要你是平头百姓,你都不得不因为需要输血而支付昂贵的医药费。
同样,政府并不会因为拆迁给你补偿的太低,而强迫开发商降低房价卖给群众。压低建设成本,抬高售价,中间的利润由商人和权贵进行分配,这是官商结合的通行做法。自古以来,能够赚大钱的都是红顶商人,而不是普通个体户。
对于很多鸡冻的群众,指着鼻子问我:国家会不管吗?疯狂难道不是导致灭亡吗?
我告诉你,通货膨胀就是减缓灭亡时间的最好良药
被忽悠的群众:
请楼主解释一下
通货膨胀是政府偷偷掠夺人民财富的手段,极少数人暴利,怎是良药???
kkndme:
通货膨胀是政府偷偷掠夺人民财富的手段,极少数人暴利————没错,通货膨胀就是剪老百姓的羊毛,让权贵的财富更集中,中下层群众更贫穷。
但是,从国家的统治与巩固来讲,的确是良药啊(当然有一定限度)。
当大多数资源掌握在少数人手中的时候,占有绝大多数的金字塔下层的群众能够分配到的资源就越少,资源的价格就会越高,少数的金字塔中上层的既得利益者就会越富有。
大家知道,有些资源会变成富人间的游戏(比如现在的古董,字画),完全失去群众基础;而如果与生活密切相关的资源过度集中,一定会爆发极端冲突事件,造成社会动荡。
政府通过不断稀释货币的实际购买能力,并且对粮食等生活必需品实行平准制度,一方面保证了绝大多数人民的基本吃饭问题,另一方面让中下层群众手中的余钱基本消耗在特定的商品上,以至于不得不马不停蹄的劳作,这才能保证社会的稳定和向前发展。而上层精英就可以坐享其成。
让我们回顾一下过去
80年代,那时的人们靠省吃俭用积攒出节余,被消耗在自行车、手表、缝纫机上。通过不断的劳动,才能吃饱饭,才能攒点钱买三大件取媳妇。
80年代末,90年代初,人们的工资提高了,手里的结余增加了,彩电、冰箱的大规模普及又消灭了老百姓手中的流动性。
紧接着电话、空调又接过了彩电、冰箱的大旗。那时安装个电话可要5000大元啊。
随着工业化水平大幅度提高,经济高速增长,货币发行量也迅速增加,彩电、冰箱等工业化大规模产品已经不具备稀缺资源的特性,也无法吸收百姓手中庞大的结余资金。
汽车和商品房的发展成为消灭老百姓手中的流动性的最好工具。
在经济发展的大潮中,一旦对资源的支配权可以换取利益,贫富两极分化是发展的必然。随着贫富分化开始加剧,财富集中在少部分人手中,集中了大量财富的少部分人已经不满足于购买普通的消费品(汽车是工业化的产物,不具备稀缺性),对投资品的追捧造就了2005年房地产的崛起。
房地产具备了投资品和生活必须品的双重属性,即可以让金字塔中上层的精英群体依靠房地产保值增值,又可吸收掉中下层群众的未来若干年的结余资金。
大量印刷的货币还是有一定数量留到勤劳肯干的白领手中的,而这些货币又因为通货膨胀因素消耗在不断上涨的生活必需品上,必需品中商品房占了大头。
于是拥有大量房产的金字塔中上层精英可以坐享其成,享受房产升值带来的收益,而中下层群众不得不为房子打工。
发行大量货币满足经济发展的需要,同时通过通货膨胀来消灭广大群众手中的流动性,是政府稳定社会,发展经济的法宝,适度的通货膨胀当然是缓解社会矛盾的良药
tjOOSAN:
楼主!这段话,我不是很明白。
好像世界上,每个国家都是如此把?谁会不买东西?谁会不买生活必须品?
别忘了,中国发展到现在,百姓也没有能力购买一切生活必须品!当然,随着社会的发展,人民在一点一点的去完善基本生活。
这你却说成。。。精英和国家的阴谋。。。我。。。很难理解。
稳定粮食价格,这对每个国家而言,都是必须的啊!??这最最基本了吧?
房子为什么涨价???国家决策!懂吗?间接取消了经济适用房政策。市场上百分之九十都是商品房!!你告诉我,房价能不涨吗?
房价涨了,受益人是谁???是政府!!不是你嘴里所谓的精英,他们只是傀儡罢了!
kkndme:
不是阴谋,我没提过一句阴谋,是国策
好比美国,以中产阶级利益为代表的美国,一个币值相对稳定的国家,主导借钱消费,这就是国策。
当08年的金融危机,多数中产却尝到了惨痛的教训。而在美国的华人,因为热爱储蓄的原因(这跟美国币值相对稳定、华人储蓄习惯都有关系),生活并没有受到太大影响。#card
房产投资的几点建议
感谢大家的支持,不少朋友还提了一些关于房产投资的问题。
我觉得无论做什么样的投资,自己一定要做足功课。就房产来说,对于区域经济发展,要有深刻的理解,否则就不要轻易出手。
关于房产,我只是从大方向上说了一下自己的判断,并没有对区域的房产升值做过研究,所以没法给大家提供建议,请大家谅解。
不过,关于房产投资的方向,也有几点心得:供大家参考:
一、坚决不能投资自己不熟悉的城市
二、坚决不投资中小城市,一般省会及计划单列以上城市问题都不大,但中小城市即使房价上涨也存在变现困难问题。
三、坚决不投资距离大城市较偏远的旅游城市,比如山东乳山之类的,几乎无法变现。
四、慎重投资大城市的郊区,除非价格绝对低。如果外来人口比较多,政府又有发展规划,且价格与城区相比有较大的价差,才可以考虑 #card
经济适用房都是内部分配的
yjfsam:
看新闻说,在经济适用房里提供一定数量的廉租房,而不是大量廉租房,经济适用房是可以购买的,而且是建在市中心附近,如果是我,我当然是想买经济适用房,而廉租房又不多,这会不会跟楼主的意思有点不一样?
另外经济适用房在高价房附近推出,可以打压附近房价?
kkndme:
你认为建在市中心附近的经济适用房是给普通老百姓建的吗?是低收入群众有资格购买的吗?
经济适用房都是内部分配的,但一旦走进市场就可以牟取暴利了。
tjOOSAN:
大哥!!我真服你了。。。。。。
你知道 定向分配吗???就是只有拆迁户才有资格买的房子。不存在收入的问题!!
你纯粹是胡诌啊!我发现
kkndme:
兄弟,你一直比较鸡栋,呵呵
拆迁户的定向房属于另外的问题,作为有产阶级的拆迁户来说,部分是城市扩大化的受益者,而部分又是受害者,不能一概而论。时机不同,城市不同,境遇也不同。
但是有一点可以肯定,拆迁的目的,不是为了拆迁户过得更好更舒服。开发商愿意支付高额的拆迁费(只限于超大型文明的城市,许多城市拆迁户的补偿是很可怜的)而是有更大的利润可图。
政府为主导建设的市中心经济适用房也不仅仅为了拆迁户回迁,拆迁户回迁比例最多占小区总放量的30%,而其余的基本上是权贵房
tjOOSAN:
我可不激动!就是闲的没事,来找事吧!还算是正事!
你说的什么给权贵房,固然存在。但是比例太太少了!!你说的话,根本没有依据!
现在买限价房的和经济适用房的人,都要在报纸上公布姓名和住址。
而且只要不是太穷的,基本都希望拆迁!因为第一,给的钱多。 第二 可以有定向分配。而且还是好地段的房子!!
kkndme:
兄弟你还是去了解一下体制内分福利房的真相吧。
福利房占用的都是经济适用房的指标啊
真正向社会公示的保障房才有多少呢?相对于数量庞大的福利房,可以说凤毛麟角。
不了解真相就没有发言权啊
特别是在二三线城市,房源比一线相对略为宽松,一个有点级别的公务员,通常都是分两三套房,这些房子占用的都是保障房的指标,都是要统计入保障房数据的。
不信你可以问问身边的公务员、银行员工、垄断企业员工。
tjOOSAN:
奥!你说的是,传说中的 国企员工啊!!
可你一开始却说得是 经济适用房!是你搞错了把?
国企员工分配房子的,也要够一定工龄!一定级别!不是谁都有的。好伐?
而且 现在中国地产,很大一部分就是国企投资的。
所以叫内部分配么!!国企分房,在中国的体制内是正常的!
kkndme:
传说中的上海人?
我没有搞错,体制内员工分配的福利房就是经济适用房。
我举个例子,昆明武警干部的福利房叫恒安新邻居,它的官方名称叫什么?
我告诉你,叫做“武警经济适用房小区”
你看到的内部分房,占用的都是经济适用房的指标,也就是占用的是:我们所说的为了解决民生问题的保障房的指标。
tjOOSAN:
kkndme
你认为建在市中心附近的经济适用房是给普通老百姓建的吗?是低收入群众有资格购买的吗?
经济适用房都是内部分配的,但一旦走进市场就可以牟取暴利了。
这可是您自己的原话啊??对吧??
市中心的经适,就是叫做定向分配。就是 在这附近拆迁的人,住的!!
你非要说,有人谋私,我也不反对!但绝对不会多。
kkndme:
我估计是你理解错了,谋私和牟取暴利是两回事。
假设你是某市科级公务员,分到两套房子,以保障房的价格购买,但是却可以按照市场价格出售,只要一转手就可以进账几十万甚至上百万。
这就是分房双轨制给体制内有级别的员工带来的暴力机会。这跟谋私没有关系
tjOOSAN:
我觉得楼主拿经济适用房 做例子。很愚笨。
中国房价高起的根本原因,不就是国企,制造业资金进入地产么。
经济适用,现阶段就是为拆迁户盖得。
kkndme:
晕,也许你们上海是吧,放眼全国肯定不是
jellyoak:
上海今年以前根本没有过经济适用房,恰恰相反,上海是商品房最彻底的城市
给动迁户的叫动迁安置房,绝对都是建在最偏僻的地方的,最近5年基本上没有原拆原回的安置。
那位激动的同志有点多动症的嫌疑,忽略算了。
tjOOSAN:
kkndme:
我估计是你理解错了,谋私和牟取暴利是两回事。
假设你是某市科级公务员,分到两套房子,以保障房的价格购买,但是却可以按照市场价格出售,只要一转手就可以进账几十万甚至上百万。
这就是分房双轨制给体制内有级别的员工带来的暴力机会。这跟谋私没有关系
你。。我不知道你说这个是什么意思?
贪污腐败是少数。这是肯定存在的现象。但我现在讨论的是大众现象!
而且内部分房的们都要够一定级别!就算他们一人分三套,那根本对楼市没有影响的
kkndme:
我说的是房产双轨制,是一种制度,不是说个人的以权谋私。
房屋问题实际上是土地问题,当一少部分人群能够以很低的代价占有更多的土地,市场上的土地就会变得稀缺,价格就会上升。
jellyoak:
可以说上海是最彻底的商品房市场化的城市。
没有小产权,没有福利分配,完全的市场化。
唯一的例外就是动迁户能分配到动迁安置房,虽然都是地处偏远但现在也都价值高昂。
lz说的那种公务员分配的安置房在很多城市是很普遍的。
情况绝非那位偏执狂TX所理解的
事实是庞大臃肿的公务员机构都有机会给这些公务员分配到一套住房,总数量很是惊人。
如果严控贷款的话,现在上海的房价是得不到长久支撑的。
看长期政策如何了。
现在没人相信贷款可以一直这样卡下去。#card
[[普通人怎么办:尽早买房,努力挣钱抵御通胀]]
永远不要和白痴争辩,因为他会把你的智商拉到和他同一水平,然后用丰富的经验打败你
鸡冻先生
能够有资格跟你辩论的一定只有两种人
一种是智商极高,世间罕见的
一种是智商比较低的。
其他人跟你辩论那是自找苦吃 #card
[[当个农民也要懂政策,要顺政策而为]]
利益才是政府行为的指挥棒
北大朱晓阳用了十多年时间跟踪昆明城中村,对刚刚建好5年的宏仁村就要因为商业利益而拆迁已经出离了愤怒,结果这事捅到CCAV曝光了,拆迁的事只好暂停。
利益才是政府行为的指挥棒 #card
建议一定是建立在严肃考察的基础上
爱情就像跳恰恰:
这两天全部看完了,深受触动,楼主是个睿智的人,赞一个~
想说下自己的情况,楼主帮我参谋一下,我在上海,女性,前几年由于一些特殊个人原因,导致一直没有自己的房子,这两年专注于事业,今年发展不错,进帐了260万左右,但是,通过几次看房,我发现 300万以内,已经找不到理想的房源!
我现在是租住的市中心高档住房,每月租金 8500块,100个平米左右,这样的房子大概售价 500万左右,所以,现在的情况是 我想住的房子买不起,买的起的我也不想住~
我本人对买房和租房没有太大感觉,从某种意义上说 我倒更喜欢租房,可以每两年换个区 换套新房住住 比较有新鲜感~但是,我手上也不想持有现金,由于物价上涨,通货膨胀,我觉得持有现金的风险也不小!
不知道楼主对扬州的房产怎么看,我想放弃上海,到扬州购入房产,处于保值或者以后升值空间大后再售出,比如在市中心购入两三套高档小户型,用于出租!扬州由于地理优势,一两年后可能开通上海高铁,这样考虑在扬州安个家也不错,再置入一套生活便利的大点房子,以后可以考虑自住~
kkndme:
你的想法显然是经过深思熟虑的,在扬州买房子自住,花更少的钱过更舒适的生活很好啊,当然前提是你自己喜扬州这个城市。
说到投资,其实没人能够取代你自己的判断。我也没法给你提供究竟有多大升值空间的建议,因为建议一定是建立在严肃考察的基础上的。
我只能说东部地区的城市房产保值还是没问题的,但在哪个城市投资更好,确实需要认真实地考察。
如果从全国范围看,仅对投资而言,我比较看涨西安和重庆。但我个人不会在这两个城市买房子,因为本人不喜欢重庆的酷热和西安的气氛。#card
要用发展的眼光看问题,只要努力,只会越来越好,越来越轻松
要用发展的眼光看问题,只要你还年轻,即使你现在给老板打工只能赚4000块,并不意味着以后多少年都只赚4000块,随着经验和阅历的增长,薪水是会提高的,当然前提是肯学习,肯吃苦,提高能力和才干。#card
性格决定命运
错误角色:
我只买得起4000元内100平的房子!哪怕住小点,住旧点…我也不愿意背着几十年的债度过我最美好的青年和中年时代、我更不愿意每天睁开眼就开始为了还房贷而奋斗。我不想短短的一辈子只是为了一堆只有七十年产权的砖瓦而奋斗。我只是一个平凡普通的人,我只想和老婆有一个快乐安逸的小家…但是“家”这个商品已经成了现在对我来说最昂贵的奢侈品。哈哈!
kkndme:
有一句话叫做怎么样付出就会怎么样的收获,看到许多人买房获利,另一些人坐不住了,心态变得鸡冻了,但是,当初人家咬牙买房的时候,另一些人还在追求所谓的生活品质。性格决定了命运 #card
2012年不取消调控,还有房价维稳顺利换届考虑
政府希望房价维稳,为2012年换届后上涨留出空间,所以调控政策不会轻易取消,但是在高通胀预期的背景下,能不能稳住房价是很考验政府智慧的。
换届后的老板不可能去接一个烂摊子,这是关键的地方 #card
洼地最终都会被填平,多数城市是早买胜于晚买
目前传言与辟谣越来越频繁,如何透过重重的迷雾看到事情背后的真相。
这次调控中央盯的主要还是一线城市,从提高首付比例,直到监管预售款的准备推出,都是为了提高房地产进入门槛,踢出大量小资金投资客,让小开发商民营开发商知难而退,为国家队入场铺路,中央需要稳定一线城市房价,使2012年能够顺利换届,为换届后的上涨留足空间。有了国家队的后盾,中央无需因为调控导致部分小开发商资金链断掉而担心,相反这是中央希望看到的。
当然在政策和市场的博弈中,是否能够达到中央的预期,中央的心理也不一定完全有底,因为资金有他自己内在的规律。在打压房地产的同时,会带来农产品等生活必须品的价格全面上涨,这就需要xy做出一个权衡。因为填饱肚子的问题比房价的问题更重要。
多数二三线城市会在一线城市滞涨期间进行补涨,补足09年行情中远低于一线城市的涨幅。
作为二三线城市的刚需买房者,多数城市的情况都是早买胜于晚买 #card
[[短期波动属于正常现象,需要关注的是长期趋势]]
早买的风险小于晚买
fantabulouski:
楼主给点意见吧,想在上海市内环内买套二手房,现在出手合适嘛?
等等的话可能跌点么?有没有什么风险吗?
多谢! 因为首套房可以贷款七成,多谢!!
kkndme:
如果手头有钱,又是自住,到不一定非要考虑抄在最底部。
因为钱要贬值是毋庸置疑的,房价在一段较长时期上涨的趋势也是毋庸置疑的。
但短期,波段性的抄底和逃顶是很难把握的,尤其是自住,考虑太多实在没有意义。
持币要冒房价持续上涨的风险,买房可能会面临短暂小幅下跌,哪个风险更大,需要自己认真考虑。
一线城市如上海一定会有短期的滞涨甚至小幅的下跌,当新房的价格低于周边二手房价,并且成交量开始逐渐攀升就是买房的时机。
我反复强调,这次调控期却是二三线城市的补涨期,对于一线城市正好可以仔细的挑选好房,这种机会在房价上升期是难以遇到的。
fantabulouski:
楼主再问一个问题,看看这一两天调控的信息满天飞,上海房产税的消息也到处都是,银行在不断的紧缩,感觉这次调控可是不同以往,是外松内紧啊,至少到年底前看不到放松的迹象,还什么情况下才可能会放松呢?难道要等到KQ 接班不成?
kkndme:
可以肯定的是首付款的比例是不会轻易放松的。房产税的推出就没那么容易了。
上海和北京城区的二手房价有点幅度的下跌几乎不可能,很长一段时间都会滞涨或者维持小幅度的上涨。
手里资金多的人全款买房的比例大幅提高,精英阶层的购买力基本能够维持一线城市的正常的成交量(09年下半年的高成交量中央认为是反常的,已经影响了金融秩序,是中央不愿意看到的。)
现在的状况是,中央对调控后一线城市的房价增幅及成交量基本是满意的。#card
小开发商的房子能不能买?
mstsc_XP:
楼主的分析让我明白了很多之前误解的东西,所以自己错过了买房时机也是有一定道理的O(∩_∩)O哈哈~
比如空置率、供求关系、当地房价和当地平均收入关系等的解释,非常感谢
想再请教一下,中央要挤出小开发商的话,到2012年,这些小开发商修的房子会不会烂尾?因为被挤出了,也不好好修了,或者干脆跑了…..因为我买的房子不是华润、中海这些有实力的开发商的楼….
kkndme:
如果不是经济危机,基本不会出现这种情况,当然排除个别不诚信的开发商 #card
天子脚下:二手老房买得好,拆迁补偿少不了
旅行中,上个网是很不容易的事情。
关于拆迁补偿的事,巨大的利益驱使,那真是鲜血淋淋的。所以二手老房买在哪里很重要。银行的房、政府的房、各大部位的房,有上市交易的,买下来肯定不会吃亏。
存在风险的就是弱势群体聚居区。但是北京,毕竟天子脚下,不能搞得太僵,最终该补的还是会补到位,至于外省就很不好说了 #card
[[君为贵,商人、技工次之,农民为轻,打工人为底]]
买卖商品房会逐渐变成富人的游戏
以后,商品房本来就变成了富人间的游戏,普通人将不能卖进参与的门槛。
到多数人真的买不起房时也就安心了,也不用关心房价的涨跌了。
但是现在,房价还没有到那个高度,很多人还觉得有希望,所以对房价的涨跌才会特别关注。这个时期应该就是普通人最后买房的机会。错过了,将不会再有。#card
政府还是更在意农民问题
肖肖19850706:
楼主虽然有很多观点写的很有道理,但是对于历史这块,并不太正确
引用一段楼主的话:
——————
自古以来,民生问题的底线就是不要出现陈胜吴广的极端情况。所以政府更在意的是农民问题。
因为历史的改朝换代都是大饥荒引起的,无论是汉末、唐末、隋末、还是明末。农产品价格上涨的对政府的震动要远远大于房价的上涨。
农民具备最原始的力量,而他们关心的并不是三线以上城市的房价,而是能否填饱肚子。
而关心自己能否拥有一套产权房的都市白领,除了呻吟一下意外,几乎是没有什么有效反抗的可能的。
——————
其实在当今政权建立之前,还有一个政权,叫做中华民国
这个政权是由民主革命带来的
他们所举的旗帜是资产阶级革命,所建立的政权是资本主义社会
为什么会失败?
这是一个值得思考的问题
让一个经历了5000年封建社会的国家经过一次革命就达到资本主义社会的境界
没有工业革命的基础
没有原始的积累
有的只是借鉴西方
想先变制度再进行调整,结果固然是失败
于是“农民起义”卷土重来,我想大家肯定明白“农民”所指的是什么
于是又了现在的这个政权
由工人阶级和资产阶级去推翻帝制
再由农民阶级把土地抢回来,最终回到封建政权来压迫资产阶级
他们最怕的还是农民么?
显然不再是了
他们最怕的正是资产阶级
其次就是你说的那些
“关心自己能否拥有一套产权房,除了呻吟一下意外,几乎是没有什么有效反抗的可能的都市白领”
攻占巴士底狱的不是农民
正是这些“几乎没有什么有效反抗可能的都市白领”
是工人阶级结束了地球上长达上千年的封建统治
而改革开放,市场经济的发展,给了这一切充足的物质基础
社会的转化过程有两种
一种是和平演变
一种就是革命
现在所存在的问题,不是他们更怕谁
而是他们选择面对哪种演变方式
kkndme:
最可怕的不是农民而是失去土地的农民。
为什么说新民主主义革命是工人阶级领导的?
那时的工人阶级是什么?就是失去土地的农民和破产的手工业者,除了体力一无所有,所以他们才具备脑袋掖在裤腰带上,为了抢土地而玩命的动力。解放战争时期,我军的宣传就是:“同志们,国民党要把分给你们的土地抢走,你们说怎么办?”于是广大失去土地的农民兄弟不干了,玩命了。
工农红军一四方面军胜利会师,在选择南下和北上发生了分歧,真的为了北上抗日吗?1935年抗日战争还没有打响,日本人在东北而不是西北。北上抗日的说法实在有些牵强。
我想真正的原因还是群众基础。
近几年多次在西南地区的乡村进行田野调查,发现一个问题:解放前,即使如贵州山区的偏僻乡村,农民自给自足吃饱肚子是完全没有问题的,更别说富庶的四川平原。
那时参加红军要有不要脑袋的玩命精神,对于多数能够填饱肚子的农民来说,主动参加革命显然是不现实的。红军在西南地区完全没有群众基础,战斗中的减员得不到有效的补充,所以人才会越打越少。
而西北地区完全不同,自然条件恶劣,农村耕地很少,存在大量食不果腹,无地可种的农民。李自成起义也是从陕西发起的,可以说具备了随时发动武装暴动的群众基础。所以毛选择了北上的正确路线。而张同志南下凄惨的下场印证了毛的正确判断。
北上延安的另一个重要原因是获得苏联的支持,没有强大的后援是无法取得决定性胜利的。
一旦农民失去了土地,而又没有去处,那是相当可怕的,所以农民工就业问题是中央最为关注的。甚至提出如何让农民工在城镇买房子置业,处理好农民问题,是社会稳定的重中之重。
将来,有地可耕的农民将会成为都市中的底层群众羡慕的对象,农民有地有住宅有粮食。进可以在城市打工,有聪明的甚至通过经商迈进富人阶层,退可以回乡种田,虽然现钱不多,但是吃穿住行都是没有问题的。
而真正一无所有的将是大量在都市中沦为贫困的人群。在打拼挣扎的打工仔,如果没有能力购置房产,也没有得到向上爬的机会,在都市立足将变得困难,而又毫无退路。#card
治国需要用贪官、反贪官
讲个故事,可能这个故事很多人都看过,并且曾经多次被转帖:
宇文泰是北周开国的奠基者。当他模仿曹操,作北魏的丞相而“挟天子令诸侯”之时,遇到了可与诸葛亮和王猛齐名的苏绰。宇文泰向苏绰讨教治国之道,二人密谈 三日三夜。
宇文泰问:“国何以立?”
苏绰答:“具官。”
宇文泰问:“如何具官?”
苏绰答:“用贪官,反贪官。 ”
宇文泰不解的问:“为什么要用贪官?”
苏绰答:“你要想叫别人为你卖命,就必须给人家好处。而你又没有那么多钱给他们,那就给他权,叫他用手中的权去搜刮民脂民膏,他不就得到好处了吗?”
宇文泰问:“贪官用我给的权得到了好处,又会给我带来什么好处?”
苏绰答:“因为他能得到好处是因为你给的权,所以,他为了保住自己的好处就必须维护你的权。那么,你的统治不就牢固了吗。你要知道皇帝人人想坐,如果没有贪官维护你的政权,那么你还怎么巩固统治?”
宇文泰恍然大悟,接着不解的问道:“既然用了贪官,为什么还要反呢?”
苏绰答:“这就是权术的精髓所在。要用贪官,就必须反贪官。只有这样才能欺骗民众,才能巩固政权。”宇文泰闻听此语大惑,兴奋不已的说:“爱卿快说说其中的奥秘。”
苏绰答:“这有两个好处:其一、天下哪有不贪的官?官不怕贪,怕的是不听你的话。以反贪官为名,消除不听你话的贪官,保留听你话的贪官。这样既可以消除异己,巩固你的权力,又可以得到人民对你的拥戴。其二、官吏只要贪墨,他的把柄就在你的手中。他敢背叛你,你就以贪墨为借口灭了他。贪官怕你灭了他,就只有乖乖听你的话。所以,‘反贪官 ’是你用来驾御贪官的法宝。如果你不用贪官,你就失去了‘反贪官’这个法宝,那么你还怎么驾御官吏?如果人人皆是清官,深得人民拥戴,他不听话,你没有借口除掉他;即使硬去除掉,也会引来民情骚动。所以必须用贪官,你才可以清理官僚队伍,使其成为清一色的拥护你的人。”
他又对宇文泰说:“还有呢?”
宇文泰瞪圆了眼问: “还有什么?”
苏绰答:“如果你用贪官而招惹民怨怎么办?”宇文泰一惊,这却没有想到,便问:“ 有何妙计可除此患?”
苏绰答:“祭起反贪大旗,加大宣传力度,证明你心系黎民。让民众误认为你是好的,而不好的是那些官吏,把责任都推到这些他们的身上,千万不要让民众认为你是任用贪官的元凶。你必须叫民众认为,你是好的。社会出现这么多问题,不是你不想搞好,而是下面的官吏不好好执行 #card
二线城市典型代表
klid:
LZ 成都属于您口中的二三线城市么?
那么这次属于补涨阶段?
kkndme:
成都、重庆、西安、昆明、武汉都是二三线城市的典型代表。#card
关于商铺和住宅投资
马甲马甲_马马甲:
请教楼主:
因为种种原因, 错过了很多买房的好时期,现在租房住,( 享受到了朋友提供的体制内的好处, 远低于市场价格租了一套房子)。
手上200万左右的现金, 在上海,想买房子保值增值,
1,有套著名大学附近的二手房子,57平米, 130万左右,估计租金大约是2.5万-3万 之间,
2,在市中心成熟的商业区有个店铺, 124万, 年租金现在是6.4万一年。
2个选择,个人倾向于投资店铺, 因为在上海店铺的涨价远远低于住宅的涨幅,况且店铺的资金回报率也达到了 5% ,不知道楼主是否有更好的建议?
kkndme:
很多人不愿意投资商铺还是在于风险大,好位置熟铺是很少有人愿意拿出来卖的,谁愿意放弃生蛋的母鸡呢?而新开发的商铺要不然位置比较偏,不知道能不能做的起来,要不然就溢价太高,超出了大多数人的承受。好的商铺是市面上很难买到的。
如果经过考察确认商铺没有问题,还是首选商铺,但是一定要经过认真的考察。
而住宅的风险就相对小多了,而且投资不需要很多的经验,更适合一般投资者。#card
关于房产调控
tianxiaobing11:
请问楼主,房价会在年底重新确立上涨趋势吗?如果再不涨,政府的地卖不上好价钱,地方财政就回吃紧,地方政府还会像去年那样出各种政策救市吗
九五二七八:
全国各地 一线二线三线 情况都有不同
楼主预测时点 怕不好预测啊
kkndme:
不但是不同城市情况有区别,同一城市的不同区位情况也有区别。就拿北京来说,过渡爆炒的通州房山等远郊区县,房价一定会有所回调,但是城市中心,特别是学区房是没有下降可能的。
而对于多数二三线城市,均价下降的原因主要还是远郊区的房源投放量增加,城区内的房子不但不降,而且涨得还很厉害。
房产投资最重要的还是位置,当远郊区县的房价远低于城中心的时候,一定会有补涨的要求,但当远郊区县的房价向城中心接近的时候,一定会出现城中心的补涨,当然在调控期也会体现为远郊区县房价的回调。
kkndme:
仔细看一下各地的房价,不要被公布的所谓均价迷惑,只有少部分城市价格下降或者持平,多数城市都在上涨,只不过幅度不大而已。现在成交量属于正常水平,不存在地方政府吃紧的问题,当然不可能象09年那样的疯狂,09年底甚至银行出现无款可贷,太高的成交量会被中央视为危险的信号,是达到危害金融安全的高度的。#card
关于房产税
tianxiaobing11:
还有一问题请教楼主,目前我一共有三套房,一套自己住,一套父母住,一套是投资房,在大连最繁华的地方,租金回报是百分之六点五,请问房产税会很快推出吗?我的那套投资房是卖掉还是持有呢?卖的话能赚白分之五十 #card
- kkndme:
在卖掉之前,你要先问问自己,拿这笔钱打算干什么?如果没的可做,干等着贬值,那你为什么要卖呢?
如果你有更好的投资或者创业渠道,那当然立刻卖掉,不用犹豫。
- 至于房产税,第一:近两年一定不会征收,因为条件还不成熟。第二:房产税只是一项苛捐杂税,目的是补充财政收入,并没有降低房价和租金的功能,并且只能导致租金的上涨。怕房产税的应该是租客,而不是房东。
- 任何税种最终都要转嫁到社会最底层群众身上。丛林法则实际就是大鱼吃小鱼,小鱼吃虾米。
- 上层人士的享受是靠底层群众勒紧裤腰带过日子换来的。
老公房的拆迁问题
wofuleyumin1:
从头至尾,一口气看完了。。赞同之极。。。
也向楼主问些问题。。。
是否老公房都会拆迁?
在成都,一环,二环内还有非常多的老公房,总量比商品房还多,这么多的房子都会拆迁吗?
我在想是否先买套老公房。。因为价格也便宜。新的商品房一般八九千。。老公房才5千多。买了后灯拆迁。
但这么多老公房都会拆迁吗?我觉得可能很多房子是不会拆迁的吧?否则只要现在买这些房子,以后都发财了。
是否拆迁的只是很少部分?
kkndme:
将来多数房都会拆迁,这是中国体制和经济发展模式决定的。在城市拆迁改造升级过程中,大量的老房拆毁,大量的新房拔地而起。而随着拆迁改造的成本的上升,房子也越来越贵。
现在拆迁改造集中建设70-90的小户型,将来会沦为新的城中村,通过二手置换,这类房子会变成新的贫民窟,而将来的拆迁改造建设的一定是追求环境品质的大户型。
因为政府官员任期的限制,决定了官员的短视,决定了城市规划的短视。
但是市中心的房子,即使在将来人口下降的过程中,仍然是稀缺的,房价高不可攀的。如果手有余钱首选的是市中心的大户型。
关于市中心老旧二手房的购买,还是有一定学问的,一定要选择位置好,低密度的矮层住宅楼,因为密度低,便于拆迁。而密度高的塔楼拆迁非常困难,拆迁成本太高,开发商很难有利可图。现在住在市中心高层旧式塔楼的富裕人口,将来一定会二次置业,这些旧式塔楼逐渐会沦为新一代年轻中产阶层的过渡性住房。#card
高端盘有房价带动作用
wofuleyumin1:
楼主。。。又有一个问题
我附近的普通房子大概9000 旁边有个02年的别墅现在13000 现在又有一个新的楼盘开盘了。。是电梯 容积3 十多层的 是中海的高端项目,装修过的 居然卖将近2万。。。离谱吗?旁边容积0.8的老别墅才13000啊
请问中海这个项目是否价格过高? 另外,这个项目对我这附近的房价能拉动多少?
kkndme:
高端房产,开发商都是不急着卖的,而且也从来不乏有钱人慷慨解囊。你说的情况跟昆明的空间俊园完全相同。在市中心徘徊在万元关口的时候,空间俊园直接开出了19000的均价,之后市中心的二手房紧随攀升到15000.而一环二环间的房价在万元关口徘徊。
大盘高端盘对房价的带动作用是显而易见的。
自调控刚刚推出的时候,与一个朋友闲聊,说起调控将是二三线城市大涨的机会,还聊了聊昆明的发展,结果那个朋友头顶调控的大棒,去昆明投了n套房产,当时价格7000多点,时过几个月,现在看房价已经涨到9000.而且他买的位置周边先后有高端大盘推出,预计开盘价格在12000-15000,一旦高端大盘开盘将让他买的房子直接迈上万元的台阶。#card
买房和没买房的差距
汝爱之罪:
新穷三代。。。ORZ
我可不想做穷一代。。。。
房子真的让人抓狂,当跟你同样起点的人早你三年买房的时候,这种感觉尤为明显。
我老公是77年的,他一个女同学2007年底在清河新城买了一套房,一百多平100多万吧,找家里东拼西凑的全款。其实当时我老公也能拿出100w不用借钱的,可是他偏不听我的话,认为清河在五环外,那种地方还要100多万不可思议。结果北京经历了09年的疯狂以后他同学那套房子已经翻倍,借的钱也已经还清。
而我们呢,在犹豫和老公的优柔寡断中错过了时机,终于在2010年3月最疯狂的时候入手了,这时候即使首付160多万,还要背负100多万的贷款,生活质量比他的女同学差的不是一点半点。
这是真实发生的事情,犹豫和无知真的能让人付出很大的代价。
kkndme:
清河新城好像是50年产权吧。反正我对50年产权的都不感冒。
我一朋友06年买的水木天成,买时5000多,现在25000,调控都不带降价的。
汝爱之罪:
清河新城盘子还是很大的,分好几期,有70年也有50年,他们买的是70年的。07年底刚开第一期,相当于股市里的打新股了,基本上没什么风险。#card
房产交易历史
最早的房产交易,出现在一个名字叫“盉”的西周青铜器上。在公元前919年农历三月份,一个叫矩伯的人分两次把一千三百亩土地抵押给一个叫裘卫的人,换来了价值一百串贝壳的几件奢侈品,包括两块玉,一件鹿皮披肩,一条带花的围裙。
周厉王三十二年又发生了一宗土地买卖。这宗土地买卖的交易过程也被刻在青铜器上。
这次记录的是周厉王买地的事,周厉王为扩建王宫,买下一个叫鬲从的人的地,没有立即给钱。鬲从担心周厉王赖账,周厉王派人对鬲从说:“你别怕,我一定会照价付款的,如果我赖账,就让上天罚我被流放好了。”这是个很毒的誓。
周厉王买地花了多少钱,铭文上没写。不过李开周说,有人买地,有人卖地,说明当时除了有土地抵押,还存在土地买卖,房地产市场已经有了雏形。
隋唐时,有个叫窦乂的人,他生在陕西,很小的时候就死了爹娘,无依无靠,跟着舅舅一块儿生活。
他舅舅是个公务员,住在长安城。窦乂先通过卖鞋、卖树等生意赚了一些钱,后来有了80万钱的身家,于是开始向房地产行业进军。
当时长安西市有一个废弃的化粪池,面积不小,有十几亩,闲置七八年了,一直没人买。窦乂把它买了下来,雇人填平,在上面盖了20间店铺,租给波斯胡人做生意,平均每天都收上来几千钱的房租。
再后来,窦乂听说当朝太尉李晟喜欢打马球,于是斥资70万钱买下一块地,又花30万钱把这块地建成一片马球场,送给了李晟。
李晟很高兴,从此跟窦乂结成死党,有求必应。有这种靠山保驾护航,窦乂发得更快了,不到40岁就成了长安首富,人称“窦半城”。
除了像窦乂这样的开发商,古代的业余开发商还有一些是公务员、退休干部等,甚至官府自己就是开发商。
比如在北宋,中央政府下面就有个专门搞开发的机构,叫做“修完京城所”。这个机构本来只能是修筑城墙和宫殿,后来城墙修得差不多了,宫殿也盖得够豪华了,这个机构就开始转型,开始给中央财政搞创收。
怎么搞创收呢?修完京城所向朝廷请示,划拨给他们大片地皮,他们在上面盖住宅盖店铺,盖好了,有的卖给老百姓,有的赁给老百姓,给国库做了很大贡献。
古代是没有专业的开发商的。做开发商最需要的是钱。买地、买建材、雇人、摆平关系,哪个环节都得花钱。尤其买地,流动资金不能少,钱不够,就得找同行拆借,或者找银行贷款。
古代没有银行,但有钱庄,可是钱庄规模一般很小,即使有一些大型的全国连锁的钱庄,他们也不做开发商的生意,都把钱借给别的老板了。
史料上有这样两个办理房地产抵押贷款的例子,一个是南北朝时候的梁朝郡王萧宏,让人家拿着房契去贷款,一张房契最多只贷给几千钱;还有一个是明朝嘉庆年间山阴县的一个富户,名叫求仲,最多的一次才贷给15000文。这点儿钱别说搞开发,吃一顿大餐都不够。
直到民国时期,外国银行纷纷到中国开展业务,开发商们才能贷到大笔的贷款。所以中国的职业开发商直到民国才出现。
古代开发商如果大量囤地得挨板子
以唐朝为例。唐玄宗在位时,土地政策里有这么一条:“应给园宅地者,良口三口以下给一亩,每三口加一亩,贱口五口给一亩,每五口加一亩,……诸买地者不得过本制。”意思就是说,政府给老百姓划拨宅基地,划拨的宅基地大小取决于家庭等级和家庭人口,如果是平民家庭,每三口人给一亩宅基;如果是贱民家庭,每五口人给一亩宅基。另外老百姓也可以购买宅基,但是购买的面积有限,不能超过政府规定的指标。
政府规定的指标是多少呢?平民家庭买地,每三口人,最多只能买一亩宅基;如果是贱民家庭买地,每五口人,才能买一亩宅基。
在唐朝,商人也属于贱民,再有钱的商人也是贱民,贱民老板去买地,即使是上百口人的大家庭,最多也只能购买20亩地,用这20亩地搞开发,一两年就倒腾光了。而如果超标大量买地会怎么样呢?
唐朝法律规定:“诸占田过限者,一亩笞十。”意思是买地超过指标的,得挨板子,每超出一亩指标,挨10大板。
虽然古代开发商没有现如今的开发商这么“牛”,环境和政策对他们都不太有利,但是在拆迁问题上,始终还是开发商们占优势。就比如窦乂,他就知道要搞房地产,首先得朝上有人,于是傍上了当朝太尉。
古代拆迁过程更为暴力,因为普天之下,莫非王土,国家要用哪里就用哪里。
当然,在古代,也不乏一些民主的君主。例如北宋元丰六年(1083年),开封外城向外拓展,规划中的新修城墙要占用120户居民的住宅,宋神宗让开封府制定拆迁补偿计划,开封府写报告说,总共需要补偿款两万零六百贯,平均每户至少能拿到补偿款171贯。#card
契税的历史
关于契税、物业税或者房产税,其实也不是现在的创造或者纯粹的拿来主义。
早在东晋时期,就开始收契税,当时叫“散估”,这也是中国第一个有据可查的契税。其后,几乎所有朝代都有契税。
唐初魏征等人写出了房产税的实质:“其实利在剥削也”——当时“剥削”没有现今这么贬义,与“增加财政收入”是一个意思。
从税率上看,东晋税率为4%,隋唐税率是5%,宋代4%,元明清三朝基本是3%。我们现在的契税大户型也是3%。
万历三十三年,利玛窦在北京宣武门附近买了处房子,他在意大利、葡萄牙、印度都呆过,那些地方并没有“契税”这一说,所以他也没有去有关部门办理手续。
《大明律》规定:“凡典买田宅不税契者,笞五十,仍追田宅一半价钱入官。”好在利玛窦同志上面有人,托了户部官吏,最后交了一笔可观的滞纳金了事。
相比之下,“物业税”这税种兴起较晚,而且断断续续。公元783年,唐德宗向长安城内拥有房产的市民开征物业税,叫作“间架税”,乃是按照房屋的等级和间架计税,上等房屋每年每间缴纳两千文,中等房屋一千,下等房屋五百。
结果民怨载道,当年深秋五万军兵哗变,口号就是“不税汝间架”。迫于压力,784年唐德宗废止了这个税种,也就是说,中国第一个正规的物业税仅仅活跃了半年就夭折了。
到了五代十国,梁唐晋汉周的每一代帝王都曾征收物业税,不过鉴于“间架税”惹过乱子,改叫“屋税”。
北宋物业税不是常设税种。南宋由于军费困难,每年两次向城乡居民征收屋税。元代,不叫间架税或屋税了,改叫“产钱”,按地基面积征稻米若干或折成钱若干。明朝,物业税不常设,江浙地区小范围征收过一段,叫“房廊钱”。清代,物业税也不常设,往往临时征收,比如1676年由于对吴三桂用兵,朝廷财政紧张,康熙下诏“税天下市房”,规定“不论内房多寡,惟计门面间架,每间税银二钱,一年即止。”算下来,是只对门面房征税,二钱税额相当于两斗大米或七斤白糖的价钱,不多。
总而言之,无论是间架税、屋税、地基钱、产钱、房捐,都是不折不扣的物业税。只不过,它们与国际上通行的物业税是不同的——不是为了调节需求,而是单纯地敛财。
然而物业税在中国并不能成为常设税种,因为这个税是纯粹的苛捐杂税,税又比较重,很容易激化矛盾,直接结果是百姓吃不起饭,太容易导致大规模的农民运动,所以很难持续征收。#card
廉租房的历史
言及公房和廉租房系统,最是宋朝搞得好。
宋朝原则上不分房,京官无论大小,一律租房居住,宰相那样的高干都是如此。偶尔有“赐第”,只照顾部级领导和有军功的将军。算起来大家的住房自有率不高。
南宋初年,大量流亡人口涌进杭州,三十平方公里的杭州城一度住了一百万人口,人口密度接近上海浦西。
因人多地少房价高,居民普遍租住公房。除了大规模公房出租,宋朝还有住房救济体制,一是灾年对租住公房的市民减免房租;二是政府建房(福田院、居养院)免费安置流民和赤贫民众;三是修建比公房条件要差的简易房,但是租金更低,堪称“廉租房”。此外,宋朝还有安济坊——慈善医疗,还有漏泽园——安葬无人认领的尸身,比较有人性。
如果是公务员的话,生在元代也还不错。建国开始,就给半数京官和所有地方官分了房,叫“系官房舍”。一般分不到的市民以自主建房为主导,但是盖房不用买地,政府批给一块官地,然后每月交一次租金,时称“地基钱。”
满人刚进北京那会儿,也给领导们分房子。一品官二十间,二品官十五间,三品官十二间,四品官十间,五品官七间,六、七品官四间,八品官三间,不入流小军官每人两间。按照每间十五平方米估算,从一品官的三百平方米、到小军官的三十平方米不等。
廉租房主要由寺观经营。土地由政府划拨,建房资金由民众捐献,房产维护可以从香火钱里冲销,僧尼道士理论上讲不以盈利为目的,再加上信仰需要,正适合执掌这项半慈善业务。大都市的庙宇常有上千间客房,供应试的学生、出门的商旅和遭了天灾的百姓临时居住。
《西厢记》里张生和崔莺莺在山西停留一整月,在那永济县普救寺里,莺莺住西厢,张生住东厢,该故事充分说明:在廉租房里也可能发生爱情。
到了明清两代,又多出个廉租房的来源,便是会馆。在这异乡人建立的聚会场所里,客房租金相当便宜。顺治十八年建于北京的漳州会馆,福建人来租住,只象征性地收取租金:每月三文钱!#card
未来房地产市场的发展
中年不惑吗:
楼主旅行结束呢?
将来房租市场会如何演化?
房租涨的太多,如果大多数租客的收入承担不起该如何?
例如租客的平均工资4000元/月,你让他和别人合租一个小两室要6000元
他们承担不起恐怕就只能离开这个城市了
kkndme:
公租房具有平准作用,政府要敛财,不能定价太低,但也不会高的离谱。有了这个参照物,个人普通房出租应该保持在比公租房稍高水平,当然位置好的高端房精装房也可能租出天价。
中国的房价在未来将成为多数群众遥不可及的梦想,也可以说大多数人都不再关心商品房的房价涨跌。
未来,租房将成为常态,所以房子的位置环境装修的档次不同,房租的差距将会非常明显。但好房子一定只有中等收入以上家庭才租得起。
而买房子是富人阶层的事,中等收入家庭想都不敢想。
中年不惑吗:
呵呵,将来,只要中等收入的家庭2个月的收入能买1平米,他们也会买房子的
难道将来的房价要涨到中等收入家庭半年甚至更长的时间才能买1平米?
kkndme:
除了房价高,贷款也没那么容易。而且除了房子,各方面的花销都会涨得离谱,这是太平盛世后期的普遍规律。
关键还在于体制外的中产,都是逆水行舟,一旦不能前进,就可能沦为赤贫。#card
房产到期
不明真相的草民:
向LZ请教
商品房的土地证年限有多重要?
现在一个二线城市的开发区,中心地段很多小区房子倒是新盖的,但地是90年代初拿的,有40年、50年的,还有30年20年的,大部分房子的土地证从现在算起只有10几年20几年,有的房子土地证已经到期了,但由于位置较好所以房价一点不便宜。按KFS的说法,土地证到期将来再续就是了,没有大的影响。
LZ给分析一下,这样房子将来的风险在哪?如果买来自住又如何?
谢谢!
kkndme:
其实有无土地证都无所谓,无论有没有土地证,最大的风险都在地方政府,人治社会法律文件其实就是一张纸,关键还是政府做得不要太过份。
即使你证件齐全政府想拆一定会拆,即使没有土地证拆的时候也会同样补偿。
这个东西实在没多大意义。
不明真相的草民:
感谢LZ答复。都是新建的高层,应该不会轻易拆迁,这么说自住还好。但如果将来要出手是否就存在困难??
期望LZ继续指明。
Lz似乎没有看到这个问题,再次感谢Lz,望答复。
kkndme:
出手不存在困难。二手房交易国家不会对土地证进行严格限制,关键还是房产证。#card
人口普查
平静的房奴:
看来楼主今天比较空闲,一口气发了这么多帖子。
有个问题想青椒哈楼主,我在武汉,最近武汉在全免清理个人和家庭住房信息,晚上调查人员还上门登记、记录,请问这是何意?是否在为出台房产税做准备。
kkndme:
人口普查。不但武汉,连穷山沟里也在忙这个,穷乡僻壤的支书天天忙得不亦乐乎。这是第六次人口普查,前面查过五次了 #card
买房难之回不去的乡 & 拉美人过得比你想象的好
九五二七八:
楼主说的以后大部分人买不了房的论题
中美在这个方面的差距 怎么这么大呢
现在产业转移 一部分人就业就有回乡的趋势
今后再有一波转移 会不会再离故乡近一些
这样 分散置业 购买难度会不会下降
kkndme:
中美体制不同、文化不同、人口不同。一辆在美国2万美金的汽车,国内要卖几十万人民币。一件made in china的服装美国卖20美金,国内卖900人民币。
不管一线城市、三三线城市都是人满为患的,从一线城市逃离的也会驻扎在二三线城市,绝没有可能大中型城市向小城市回流。
返乡潮指的是家有自留地的农民工,如果工资待遇差不多,与其到沿海地区漂泊不如回乡打工或者种地。比如贵州镇远的油漆工一天工资是150,而在珠三角打工一天工资还不到150,这也是大量农民工返乡的原因。
九五二七八:
最难的怕是现在三四流的大学生和跟着打工父母生活在城里的二代
失去了农村生活本领
在城里也无法立足
楼主
难道拉美化真的不远了
kkndme:
很多人都丑化拉美,但是拉美的生活水平要高过我国。不说远超中国的巴西,即使是法属及荷属圭亚那(苏里南)这样的小国,人民的生活也很富足。
前几年有个援助项目去苏里南等拉美国家,去之前所有的人给我灌输的都是拉美国家如何贫困。但事实上,这些国家与中国完全不同,国穷民富,藏富于民,与中国正好是相反的,只要勤快点的家庭都还比较富裕。当然不排除也有很多穷人(美国也有很多穷人),穷人一般以当地的黑人为主,好吃懒做,整日无所事事。
这些国家的人民不如中国人勤奋,从不攒钱,只图眼前享受,我想主要原因还是由于币值不稳定,通货膨胀比较严重,所以没有人愿意攒钱。在拉美国家是无法炒房地产的,比如苏里南平均25平方公里有一口人,真的是地广人稀。所以才保留了世界上最高的森林覆盖率。
拉美人的懒惰会让中国人瞠目结舌,当地的蔬菜价格昂贵,尽管有大片肥沃的土地,当地却没有人愿意耕种,很多去苏里南种植蔬菜的中国人为此发了大财。
而相反中国人可以说是全世界最勤劳的民族,但是大量勤劳的中国人却过着低水准的生活。这与中国的国富民穷,藏富于国,与民争利的政策是分不开的。
拉美国家尽管有这样那样的问题,但是确实是法制国家与民主国家,私人财产神圣不可侵犯,这是与中国完全没有可比性的。
九五二七八:
一般对“拉美化”的定义是这个吧:贫富悬殊扩大、腐败严重、国有企业效率低下、社会治安恶化、城市人口过多、地下经济泛滥、对外资依赖性强、金融危机频繁和政局不稳定,等等
没去过拉美 不知道真实的拉美
kkndme:
看来拉美妖魔化后,深入人心了。好比在越南旅游,越南人自己说越南官僚太腐败,我笑了,能有中国腐败?
拉美的官僚机构,国企、医院、警察我都见识过。
说到官员的官僚,相比中国我真的觉得那里的官员很亲切。我曾经以一个游客的身份和苏里南的司法部长一起在街边小店喝咖啡。以一个陌生的外国游客身份在财政部长家里做客,逗他家的几个黑小孩玩。
说到治安,我在街边咖啡店坐了一下午,每二十分钟一辆巡逻车从我身边经过。里约热内卢的治安绝对不会差过广州。
国有企业效率低下恐怕是全世界的通病,况且拉美根本没有可能赚钱的行业全部由国企垄断。
政局不稳要看怎么理解,拉美国家是相对民主的国家,国家元首倒是常常因为民众的不满而换届(排除少数经常政变的军政国家)。但人民并没有感觉到不幸福。
拉美国家的经济基本被美国所控制,所以才会对外资依赖严重和金融危机频繁。作为一个主权国家我们看到的是国家财政贫困,但是作为拉美地区的中下层人民群众,生活水平和幸福感是要高于国内的中下层群众的。#card
[[北京西三旗]]
买房争取一步到位
hohowell:
楼主,诚心请教下,从开贴开始就一直在潜水关注,终于坚定了买房的决心
现在在犹豫,一是买个80平米的小户型,开发商一般,房型尚可,这样贷款比较少,基本不影响供车,旅游和以后小孩的开销,不过考虑5到8年左右,这个房子就不能满足居住要求了,回头换,又是一大笔钱,而且城区内的好小区也会越来越小,另外一个就是保利的大户型,开发商物业都靠得住,基本上短期可以不用换,不过贷款至少贷100多万,短期内还会要小孩,压力会比较大,基本手里每个月都没有闲钱了,很容易回到赤贫线,一直犹豫不决,诚心请教楼主解惑,我在南京,一个一线以下二线以上的鬼地方,两处房子都靠地铁,周边商业中心配套齐全,谢谢!
kkndme:
买房子如果有能力还是要争取一步到位。将来改善,除非个人有较大的发展,否则将很难很难。而且买楼首选好位置,大开发商,大盘,升值空间才大。
welldayzwb:
看来楼主分析说购房应该一步到位,我就犯了一个错误,用投资的眼光来选择自住房,后来买的两居室比同小区的三居室性价比高很多,但是居住环境不好,临一条小街,所以现在住起来不是很爽,现在调控着价格先不说了,光是现在限制换房的一些条条框框感觉再置换就很麻烦
另外一套买的外面一点,小区环境非常棒,不过当时是被环境给迷惑了,放租的房子管那么多环境做什么,感觉两套房子操作反了
纠结中啊纠结中,现在唯一能安慰自己的就是,买上房子总比没买强,如果去年年底再犹豫一下或是赌气的话,那就真是悲剧了,一个好三居得活活等成质量差些的两居了 #card
收入稳定的家庭如何买房
黑眼圈钱:
请教楼主,买房子的事情,比较纠结。
1)夫妻两人均在西部某高校任职,一个教师,一个行政人员,年龄都不小了,37和35,两人每月总收入在8000-10000,1年算10万收入,应该会多一点。
- 一个女儿,才两个多月。
3)每年给双方父母1万,双方父母均已60出头,一方父母城里的有退休金及医保。另一方父母农村的,得为他们准备点钱。
4)目前租住单位两室一厅房,就在学校住宅小区内,除了小点,别的都好,房租100。
5)公积金两人很少,约1000元每月,未来1-2年内会有购福利房机会,估计90多平方的旧三室一厅(约需 10万元),可能有120平米的房子,但需要排队看单位建房情况(2000每平米)。
6)两人都有单位医疗保险。
7)孩子可以上学校的幼儿园和小学、初中,就在150米范围内。
8)对于车没有什么想法,每天步行上班用不到车代步。不过会买辆10万左右的。
9)现在没有任何投资和理财。银行存款1-2年期定期存款50万,这个傻了,已经存2年了,平时光顾着干活。
有没有必要买个商品房呢,周围的房价从08年的4500涨到现在8500,容积率还非常高,并且楼间距等等不理想,那种房子我不想住的。
其实在附近买套120平米的房子,首付后也供得起,买房子放那等涨价或者出租? 不想放弃单位的房子,每天睡到自然醒再去上班还是挺惬意的,送孩子上幼儿园上学也方便。
买了房子后经济会紧张些,不像现在自由。财务自由也算一种幸福吧,我太太对于房子没什么要求,所以也不给我什么压力。
kkndme:
对于工作稳定,收入不错的体制内家庭,基本上的情况就是有闲钱就买房。主要还是由于收入稳定不用担心失业,钱放着只有贬值,不如置业。投资型住房与自住型住房在选择方向上有很大不同。
举个例子,昆明打造了个螺丝湾,几乎半个昆明做生意的人都聚集在哪里。如果自住没有人愿意选择在那里买房,实在是不好住。但是投资确是最好的选择,因为可以获取较高的租金的收益,将来升值空间也不会小。
假如在昆明一环附近买一套两居室,月租金一般在1500-1800,而房价在万元左右。而在螺蛳湾附近买一套两居室,月租金都在2000多,而房价在7000多。#card
贷款还是全款
jhjdream:
楼主,请教一下,
也正是8月初看来楼主的帖子,坚定了我此时买房的决心
我在3月份卖了一套小房子,8月底买了套大点的,也是学区房,学校在建
现在考虑一个问题,是全款付清好还是贷款比较好
全款付清,欠亲戚10多万,没有还钱压力,年底可还清,但是手头没有余钱
贷款的话,手头会有20多万余钱,可以装修,或者等年底再攒点钱,投资其他的
所在省会城市房价8000多,偏一点的6000左右。
装修好出租2500左右,贷款月利息2000左右
也就是说我全款还清,一年相当于收益2.4万的利息及3万的租金,房款70万左右,
是否值得?还是贷款35万比较合适?
因为考虑到通货膨胀时期,应该是负债比较划算~~ 谢谢!
kkndme:
肯定是贷款划算,这是毋庸置疑的。当然如果你的余钱实在找不到其他投资渠道,也可以一次性付清。如有可能也可以贷款买两套,而不是买一套。
70万的总房款月租金达到2500,租售比还是很高的,贷款35万,租金抵月供完全没有问题,说明你所在地区的房价具备较大的上涨空间。#card
00后的买房需求从何而来
和风中的树叶:
看了那么多 有点意思
不过在下有一事想不明白:
因中国的计划生育政策 往近了说 人口红利会在这几年消失 往远了说 80后基本都是独生子女 父辈在城市里都是有房子的 这些房子作为遗产 按理说 在未来应该使00后没有买房的需求。
LZ如何解释在这种情况下在未来房子仍然看涨?
kkndme:
前面已经说过了,你往前翻。
和风中的树叶:
LZ能不能再贴一次?或者说明一下在第几页?谢谢哈~
kkndme:
回去找了一下,居然被删了。
大意基本是讲中国经济未来的发展模式,城市升级与拆迁改造的关系,没想到这样也不允许说。实在懒得再长篇大论说一遍。
关键的意思就是一方面是富裕阶层对更高端产品,更大面积的追求,一方面是城市升级带来的大规模拆迁改造。下层群众将被挤出城市核心区。许多住房都会被拆迁置换。#card
意大利的住房模式
我本人对意大利的住房模式还是比较赞同的。
有去过米兰的朋友可能很清楚,米兰城区的房屋居住的大多数是富豪显贵,一旦出了城区,则是大片大片鳞次栉比的公租房供普通工薪族居住。
以后的中国有可能学习这个模式,原市中心的居民被拆迁安置到郊区,城区居住的都是达官贵人。郊区将形成拆迁安置房、中产阶级商品房、公租房、廉租房混居的模式。#card
北京远洋山水
tianxiaobing11:
不知楼主了解远洋山水吗?在西四环外,我舅舅想在那买房,去年一万七没买,今年最高到过三万,现在两万六左右,能买吗?还有升值空间吗?诚心请教。
kkndme:
别提了,08年的那次调控,开盘才1万1,这是个让人悔得肠子都青了的楼盘。
北京的楼市前景,在未来的两三年,北四环西四环东四环达到5万,北五环西五环外到达3万应该不是什么难事,南面可能相对低一点。远洋山水的位置2万6不能算便宜,但将来只有更贵。#card
精英的资产
5万一平的房子对于中国的精英阶层真算不上什么。500、600万一套的房子一次性付清的人群在北京大把的存在着。这是很多工薪阶层一辈子都觉得不可能挣到的财富,但对于另外一些人却可以轻而易举的拿出来。平均工资的概念在中国是完全没有用处的。#card
普通人买房的未来
baiyang11112010:
直白说,我刚毕业一年,完全靠着父母资助,要完全靠自己根本买不起房,我一些同学在北京两人的话年薪也就15万左右吧,现在好歹还能惦念着买房,要是像您所说,“北四环西四环东四环达到5万,北五环西五环外到达3万应该不是什么难事”,那他们根本就没有盼头了,这是很可怕的事啊
kkndme:
将来年薪20万的中产阶层一定连北京6环内的房子都买不起。这一天,不会很远。#card
北京房价超香港
tianxiaobing11:
金岩石说未来五年房价还得翻一翻,北京核心区域得到二十万一平,真会那样吗?请楼主说说
kkndme:
北京北四环,东三环,西三环,南二环内区域的房子,价格一定会超过香港。
tianxiaobing11:
香港怎么也得几十万一平吧,还是得早买房,早买早心安
kkndme:
香港都是按尺算的。富翁住的千尺豪宅相当于我们的大约100平米。现在香港的房价换算成平米大概是十五、六万一平吧。#card
中国的新闻不可信,精英的有钱是你想象不到的
bluesyang2010:
搂主分析一下,现在的新闻都说房屋成交量的上升是因为kfs打折才上升的,但这个很不成立,为什么新闻这么懵老百姓.是不是政策上还有可能收得更紧?
kkndme:
中国的新闻最不可信,为了抓眼球不惜胡编乱造,不惜前后自相矛盾。我倒觉得这个成交量放大的背后的意义更值得深入研究。
在二套房首付50%,三套房首付更是严格控制的前提下,成交量大幅提升,中国的货币到底泛滥到何种程度,中国的精英阶层的绝对数量多么庞大,手里多么有钱。中国的贫富差距很可能已经达到了一般人不敢想象的程度。
这是一个坏的预兆。#card
限贷对精英没用
tianxiaobing11:
楼主,我也是不明白,现在成交量确实上来了,按说现在贷款控制的这么严,第三套房都贷不到款,是谁在买房,难道都是第一套房的刚需吗
kkndme:
民币发行泛滥,有钱人绝对数量庞大。在北京上海等城市,手中拥有千万现金的人不在少数,都是全国的精英阶层啊。精英阶层的财富积累已经逐步完成,提高首付,严控贷款只能抑制小白领保值的需求,但对于精英阶层是没有任何作用的。
如果将来推出房产税就更好笑了。精英阶层谈笑风声,小白领神情紧张,最终结果是全部转嫁租房客。
bluesyang2010:
我认为,这个跟kfs和政府之间的博弈有很大关系,投资人前段时间一直在观望或者投入到农产品等领域,我不记得是7月还是8月,突然听到热钱大量涌入国内房地产市场的传闻,之后成交量就上来了,这些信息之间有很大的关系,但我捋不清.
请楼主评评
kkndme::
你说的很有道理,当资金泛滥无处可去,一定会找到一个出口。资金如洪水在于疏而不在于堵,资金一旦冲破调控所筑的堤坝,将一发不可收拾。所以屡次调控屡次暴涨。如果不能有效开渠,将注定调控政策的失败。
tianxiaobing11::
我现在就被抑制住了,现在是认房不认贷,我也不能贷款了,可现在动不动就得百万以上才能买房,真是力不从心啊,房贷新政看来是堵塞了中低收入的房产投资渠道了,对精英阶层反而是利好,这调控就搞笑了
bluesyang2010::
政府倒是想调控精英层呢,但政府本身就是精英的组成部分,所以政府只能借砍掉投机者之名,开拓自身,抢占市场,特别是楼主说的租赁这个大市场,所以特别佩服楼主之前说的:政府找到了吃租赁这块蛋糕的最好时机,明着是抑制房价,其果却是让很大部分老百姓租着政府的房,政府的钱就更多了,到时候想拆哪儿拆哪儿,精英更精英,百姓更百姓….可悲呀
kkndme::
估计给政府出这主意的幕僚熟读过宋史,宋代官府就是靠出租房给群众敛财的。#card
外国国籍在中国生活是更好的选择
理财的猫咪:
我有段动过移民的念头,但现在基本放弃了。不知自己的选择正确与否,想听听楼主高见。
kkndme:
移民不见得能够适应,毕竟文化差异太大,但是如果拥有一个外国国籍,在中国生活,是一个比较好的选择,至少,你的财产是受到保护的。#card
读史读的不是故事,还是找历史规律,以古鉴今
读史读的不是故事,还是找历史规律,以古鉴今,毛就是这方面的天才。
读史难在古人常常作假,事件往往扑朔迷离,必须象破案一样,从重重的迷雾中寻找真相,这也是读史的乐趣所在啊。
好比喜欢三国的度魏延,总认为此人天生反骨。事实上,魏延作为仅次于关张马黄(没有赵云,赵云的才能和级别都不能和魏延相比)的第五员上将,在关张马黄死后,成为了西蜀的军方顶梁柱,不但有极高的军事天赋,而且忠心耿耿,不足的是政治头脑不大灵光,结果诸葛亮刚死,就被小人杨仪给黑了,不但掉了脑袋,还被按上了背主的罪名。
汝爱之罪:
《三国演义》里这一段完全是黑魏延来着。
我心里还想,其实魏延还是比较大度的,马谡刚愎自用的时候,诸葛亮很不爽,但是魏延还一个劲的替马谡说好话,我就觉得魏延一直忠心耿耿,怎么可能晚节不保呢?
唉,看来正史和演义,还是有很大区别啊
kkndme:
正史里很多信息都是极其可疑的,就更别说演义了,呵呵。
每次听评书赤壁大战一段,诸葛亮给关张布置任务就觉得好笑,赤壁大战时诸葛亮官拜军师中郎将,官职远不如关张,关张不可能直接听诸葛亮的将令。当时,诸葛亮顶多给刘备出出主意,调兵遣将还应该是刘备的事。演义一夸张诸葛亮,,就没刘备什么事了。#card
贵阳
努力看透:
楼主,谢谢你对贵州的关注!
我是贵阳的,想听听你对贵阳的看法,我07年在小河区2400买了120平方的新房子,今年八月初买了套市里的二手房,93年的,65平方,学区房,总价43万,送家具家电!
非常想听听你对贵阳房市的看法,还有金阳新区的看法,感觉金阳就是房地产撑起的,如果地产有个风吹草动,金阳会是最容易受打击的,不知对否?
另外93年的老房子以后卖时不好贷款,是不是会影响成交价格?
谢谢
kkndme:
刚从贵阳回来没多久,呵呵。
贵阳投资房产有一定的风险,主要是城市比较小,不好变现。如果我在贵阳投资,即使再贵也会选择喷水池附近市中心的楼盘,稀缺性较强,变现相对容易。
贵阳是一个城区尚未开始升级改造的城市,政府大力打造金阳花溪等外围区域,但是将来一定会遇到较大的交通瓶颈,城区的升级改造早晚都要启动。
关于金阳实际上就是政府的造城运动,因为市政府的搬迁对房价有一定的支撑力,但是随着人口的大量入住,从金阳到主城的交通可能出现瘫痪状态,谁又能保证政府不进行二次搬迁呢?
贵阳的美女确实很多啊,是这个城市最靓丽的风景,令人留恋。
努力看透:
贵阳小了,为什么房子不容易变现呢?毕竟全省只有贵阳繁华点,地方小,人多,更应该容易变现啊!我指的是市区房,不含郊区
kkndme:
市中心中高档房屋变现是没问题的,但市中心老房变现也不是很容易。贵阳的城中心改造升级还没有启动,市区存在大量的老公房,而贵阳最需要的是改善型中高端住房。现在政府全力打造金阳等外延区域,大片的新楼盘拔地而起,二手房交易的活跃度远不如其他省会城市。
贵阳与成都、昆明这些西部城市略有区别,昆明、成都有大量的外地人口,这些外地人口构成了买房刚需,因此市区位置的稀缺性就显得尤为重要。
但是贵阳的外地人口相较昆明、成都要少,以本地改善型需求为主,所以城区楼盘的档次尤为重要。
作为相邻的省会城市,重庆的吸引力要大于贵阳,贵州许多地州的资金可能会被重庆分流。#card
深圳 & 昆明仇书记 & 通货膨胀体制内高枕无忧、体制外自求多福
sprina0321:
楼主真是高人啊,追了两天,终于看完了。也想向楼主请教下房事
不知楼主对深圳了解吗,我们来深圳七年了,结婚也好几年了,可是最近才去布吉买了首套,布吉的可园,二手,单价一万四。现在深圳关内10年的二手都一万六,好一点的两万,关内基本没新房了,有的都3万左右了。大量的新房都在关外,基本2万吧。我们本来也想买关内,可是想着同样的价格在关外可以买好点的,就买了关外,不知这个决定是否正确?按楼主的意思,还是要买市中心,可是市中心的话,只能牺牲面积,房子也旧,这样住着也不舒服啊。
另外,我父母就在昆明,他们本来在一环上有套房改房,挺方便的,就像楼主说的,可恨的仇书记要制造需求,现在他们的房子说是要拆了,他们现在想买,可是一环外的都8000多,他们觉得有点贵,买了以后,手上的钱就都用完了,又想干脆等回迁。楼主觉得要不要买呢?
我父母就我一个孩子,他们在深圳买过一套房子,就是市中心的塔楼,等我们不住了,这套房子要不要卖掉,还是留着出租好?
kkndme:
深圳不太了解,不过宁肯牺牲点品质也要选择市中心,这是无数人经过从市中心搬到郊区大户型再搬回市中心老房子而取得的宝贵经验,当然如果你在关外上班就另当别论了。
往历史人物上套,qh应该算作集酷吏与奸佞于一身,横施暴()政早晚落到身败名裂的下场,不是不报时候未到。等拆迁主要是在昆明风险比较大,几年不知道能建起来,志远综合体就是很好的例子,如果有能力不妨先买一套。
至于说房子卖不卖关键你是否需要用钱,如果不需要,又没有更好的投资,不妨先留着。
sprina0321:
我有时候想,像QH这样的人应该不得好死,断子绝孙,老天还真是不长眼。
请楼主明示 志远综合体是怎么回事
我父母家就在东站,董家湾中间那里,原来厂里也在,现在厂子搬到开发区了,家里的房子也逃脱不了被拆迁的命运了。
现在家里在一环出去点看中一个房子,房子挺不错的,大社区,新房,算下来9000多,不便宜啊。一环内的估计我们买不起,家里人年纪大了,想住电梯房。
楼主对昆明现在的房价怎么看呢,会不会回调,感觉今年涨很多。
现在9000,难道以后涨到2万,和深圳现在价格一样?我和老公也工作很多年了,现在年收入30多万,我们都买不起2万的,我们去看过万科在深圳的新盘,房子没得说,带精装修,2万多一平,一套要300万,虽然很心动,也只能放弃,怎么现在昆明人这么有钱了?
按照通货膨胀来说,如果以后昆明的房子卖2万,那深圳的岂不是要卖4万,那我们的收入也会涨到60多万吗?哈哈,实在算不过来了。通货膨胀对我们的收入有影响吗
kkndme:
一环外9000多的新盘,昆明还真没几个,滨江俊圆9000多,但容积率太高,又有大量的回迁户,个人很不看好。翡翠湾达到了12000,云上城、翠园等要开的楼盘估计开盘价也要上万了。呵呵
昆明的房价,我预计市中心将达到2万,一环二环间15000,滇池板块将达到12000,北市区及世博板块将达到1万。东市和西市在8000-9000。螺丝湾板块最不确定,但未来不会低于9000。
志远综合体早在几年前完成了莲花池片区的拆迁,但迟迟不动工盖房,时隔几年一点动静都没有,拆迁户没有买房的现在还在租房住。
关于通货膨胀问题,体制内的职工工资一定会与时俱进的。体制外人员的薪水不取决于通货膨胀,而是取决于行业的利润率,企业的利润和个人的能力运气。对于多数竞争激烈,产能过剩行业内的民营企业一般员工,工资增长是很难抵御通胀的,而且由于通胀导致生产成本的价格上涨,减薪甚至裁员的可能反而更大。#card
长春
wkzjx2008:
楼主你好,请帮我分析一下,谢谢
我在长春
长春的市政府在前几年的时候搬到了城市的南部,南部因为是空地,所以盖的都是新盘,价钱现在7000多,而我工作的所在的位置是原来的一个商业区,这里原来都是学校,医院和一些机关单位,好企业的家属楼,因为原来的购买力强所以居民楼的一楼都变成了小店铺,所以形成了这个城市的一个没有大商场的一片繁华商业区,但现在随着原住民的逐渐迁走,这里租房的人多。但这里有一个优势是离市里最好的小学和高中都很近,这也是这里房价坚挺的原因。现在这里的二手房如果是大户型在5000左右每平米,小户型6000左右,基本都是八九十年代的房子,2000年以后的次新房很少,距离这个区域较近的一个新盘是商住两用的卖到9000多每平
孩子现在在这上幼儿园,堵车太厉害了,为了孩子我在这租的房子
我现在手里有20万现金,请问这片区域值得购买么,买大的还是小的,我已经贷过一次公积金贷款,现在已经结清
现在这个城市很远的地方新开的楼盘也要4000多一平米
请楼主赐教,不胜感激
kkndme:
政府所在地区域又是学区房,这样的房子优势还是很大的,但是由于有大体量的老房子存在,将来有可能大规模拆迁,而拆迁补偿却决于政府是否铁腕,如果遇到铁腕领导,补偿额一定不会太高。这是购房的风险。对于非一线城市,新盘的风险肯定小于老房。#card
佛山
爱佛僧傲瞪詹牧师:
lz高人!
不知道来过佛山没有?佛山紧邻广州,两地的地铁即将贯通接轨,房价应该会快速飙升,但是另一方面,佛山是个制造业城市,村镇工业高度发达,外来打工的比较多,流动性很大,lz所说的,今后买房只是有钱人游戏,房租会高涨,这点对佛山这样的小城市不知道成不成立?村镇里还是有很多便宜的出租屋的,高端点的打工者,如果房租太贵,应该会嫌贵干脆回家发展,最后只能留下低端制造业产业工人吧?这样房租应该还是很难上涨。
kkndme:
佛山还真没去过,只去过东莞和中山,呵呵。
对于广州一带房价相对偏低的原因是广州并非全省唯一的大型繁华城市,而是广东省内形成了大片的都市群,使得城市的经济得到了均衡的发展。这是最健康的城市发展模式,但也制约了房价的上升空间。随着地铁的贯通接轨,佛山的房价将呈稳步上涨态势。#card
首付提高的逻辑
tianxiaobing11:
请教楼主,最近有银行提高了首付,这是为什么?政府真要让中低层租房子吗?政府吃租赁的大蛋糕吗?
kkndme:
主要还是防范金融风险,政府调控的目的从来也不可能是解决穷人的买房问题。恰恰相反,金融风险来自于让穷人买房,所以提高首套房首付比例,杜绝穷人买房,才是防范金融风险的有效手段。同时可以推升租金上涨,政府推出的公租房才有市场,有钱可赚。#card
苏州工业园
夏天来了我也来:
我是昨天才看到LZ这个帖子的,一口气读完了,眼睛虽然有些累,但心里却是收获颇丰,今年四月中央刚开始严厉调控的时候,我可是抱了一百分的信任,心想我们老百姓的好日子终于来了,终于可以用较低的价格买套属于自己的房子了,可现在都九月了,看着周围一直慢慢望上爬的房价,真的是失望极了!
我九月三号的时候刚定了一套二手房,是我们的第一套房子,不知道LZ是否了解苏州工业园区的发展前景和房价,我们这套房子在园区的中心位置,也相当于市区吧,位置还不错,可就是这个房子属于政府修高速路时的拆迁安置房,房龄有十年了,原来房东的两证上写的土地性质是“出让”,不知道这样的房子以后是否有升值空间?因为在苏州园区同样的地段,同样旧的拆迁房价格基本都快一万了(我们定的这个房子因为离马路有些近,而且在顶楼,户型是小户带阁楼,上下两层复式结构的那种,所以便宜一些,只有八、九千),附近的高档商品房价格也要一万五左右!苏州和上海离的这么近,如你所说,江苏的有钱人都跑到上海买房了,苏州的房价是不是很难涨呢,同时也担心以后房价再继续上涨,中央会出重拳打击楼市,真到那个时候,房价是不是要暴跌呢?
kkndme:
土地性质“出让”没有问题,“划拨”才有问题。
政府初重拳打击的结果往往取得相反的效果,因为政府如果希望继续执政是绝不可能让房地产崩盘的,房地产的崩盘将同时埋葬现有体制,社会“和谐”将不复存在。如何让房地产持续稳定与gdP同步上涨是政府最大的难题,完全取决于领导的智慧,但是以现在的水平来看,是很难做到的。
苏州工业园区房地产不是很了解,但是一个工厂及仓储所在地,缺乏高科技与文化历史底蕴的支持,房价一定会涨,但涨幅一定有限。#card
命运之矛
荣金根团长的挂掉会不会跟命运之矛有关呢。
1189年,神圣罗马帝国皇帝红胡子腓特烈一世在与教皇和解后,与狮心王理查一世、腓力二世·奥古斯都开始了第三次十字军东征。然而,红胡子腓特烈一世在小亚细亚渡过萨列法河时竟然意外溺死。原因是他突然丢失了传说中的命运之矛。
命运之矛也叫郎基努斯之枪。
正是一个叫郎基努斯的罗马士兵用这杆抢刺入了十字架上耶稣的身体,这只枪因沾有圣血成为圣物。
传说持有命运之矛的人可以主宰世界的命运,但失去的人会即时毙命,神圣罗马帝国的皇帝红胡子腓特烈一世就拥有这只命运之矛。
二战时期,希特勒从维也纳博物馆夺取了命运之矛,差不多占领了整个欧洲。但是在1945年4月30日下午2点10分,命运之矛又被美军夺走了,不到2小时,希特勒便吞枪自杀而亡,死时是下午3点30分,这难道仅仅是巧合?
荣金根是否也拥有过这只命运之矛?
我以为我们每个人都有一把属于自己的命运之矛,当你得到它的时候,你的事业、家庭、健康、财富都相当不错,但是当你失去它的时候,你的生命也将完结。
每个人对生命之矛都有自己的理解,希望我们都能够找到它。#card
除非外族入侵或全国大饥荒,否则双轨制决定了房价不会崩盘
戈者:
不要枪,不要炮,我只要选票,有了票,谁不让老百姓好过,就让谁滚蛋
kkndme:
我们连依法治国都办不到,何谈选票。
我们是实行双轨制国家,在经济全球一体化的今天,内部并不与外部接轨。这个好比是互联网,我们重要部门的内网是绝不会跟外网联结的。
改变只有两个前提,一是外族入侵,二是出现全国性的大饥荒。否则期望房价崩盘重建一个新世界是没有可能的。#card
什么是社会公平
古今中外,任何一次武装革命,无论最终成功还是失败,上位者因为野心的极度膨胀,都变得更加专制。陈胜、李自成、朱元璋、罗伯斯皮尔、斯大林、 ,都是一个个鲜活的例子。
真正公平的社会并不是均贫富、等贵贱的乌托邦,也不是贵族享有领地少女初夜权的强权社会,而是法制社会,大家在一个完善的法律制度下,享有人身和财产自由,知道什么该做什么不该做,法典之下对于任何人都是平等的,无论是平民还是权贵。
作为爱好和平,小富即安的我等小民,最愿意看到的是社会的稳定而不是动乱。#card
还是有很多有钱人
说起空空们们不买房是因为没钱,我还真不相信。
在某二线城市,调控重拳刚出的时候,我赶紧去买房,碰见一个大姐。
那个大姐很有意思,说从08年底看房,一直觉得房价高,所以坚决不买,结果等到了2010年,一直盼着降,但是调控政策刚一出就心慌了,害怕后面是大暴涨,赶紧把房买了,这位大姐买房是一次性付款。到现在房价涨了30%。#card
开发商思维
鼻使豆豆:
高房价不可怕,可怕的是没有辩别是非的能力,明明是老百姓,却有开发商的意识,可悲
kkndme:
其实这个道理是很浅显的,你不买房并不能代表房价不涨,而你买了房不但可以住的舒适,还可以获利。反而是有开发商的思维才能有好日子过。
这个道理跟炒股票是相同的。大家知道,股票与房地产不同,并不能创造财富,只是财富再分配的工具,但是财富再分配,是庄家分配散户的钱,而不是散户分配庄家的钱。所以炒股要有庄家的思维才能挣钱。
道理都是一样的。#card
郑州有前景
larryzs:
最喜欢看楼主评说历史了
呵呵,看来历史要重新好好读一下了
不知道楼主对河南郑州的房价了解吗?
希望楼主对郑州将来的发展分析一下。
现在郑州的房价均价也差不多快到6000了,郑东新区的一万以上。
市政府也在大力修建地铁,个人认为还是有发展前景的。
kkndme:
郑州的交通区位决定了经济发展的空间,同意你的说法,很有前景 #card
张献忠屠川
关于张献忠屠四川,尽管学术上存在争议,但大致是不差的,虽不见于正史,但《蜀碧》及《求幸福斋随笔》都有记录。很多学者也做了大量的考证。
张献忠此人曾经读过书,做过政府最基层公务员——捕快,但是被开除了。人格比较扭曲,不但好色,且好杀成性,是典型的流氓无产者。大明的苦难子民指望这样的有严重心理疾病的杀人狂拯救,那是毫无指望的。
张献忠每攻城略地特别喜欢把当地的妇女同志送进军营当营妓,并且乐此不疲,军队没粮了,就把美丽的少女切成块做成腊肉。把儿童成群的围起来用火烧,谁往外跑就用刀刺,也是张大义军领袖最喜欢的游戏。
对于张的行为,我们只能用有严重的心理疾病来解释。
一个仇视社会的愤青,掌握了军队,破坏力是相当可怕的,是人民的灾难。
张攻陷四川建立大西国政权,与柬埔寨的红色高棉政权简直是异曲同工。以至于清军进入四川受到了百姓的欢迎而不是抵抗。这跟越南入侵柬埔寨,越南军受到了柬埔寨人民的欢迎是多么相似啊。
人民的眼睛是雪亮的,违反人性的,即使打着爱国的旗号,也终将被人民抛弃。#card
洪秀全、黄巢、李自成
洪秀全同志,人生比较悲剧,人家好歹是个落地秀才。洪教主考了20多年,连个秀才都没考上,相当于小学都没毕业。
洪教主考试不行,搞邪教确是个高手,夜里做梦居然梦见上帝(形象大概是个白胡子老道)说洪教主是他的二儿子。这个梦确实不太靠谱。很可能是洪教主有意编的。
洪教主的拜上帝教应该算是白莲教的一支或者说是余孽。
洪教主搞革命,对解放劳苦大众却一点不感冒,最感兴趣的是一夫多妻制,娶了88个后妃。好像历史上的农民军领袖对妇女同志都有出奇好感,大概是小时候性压抑的结果。
太平天国攻下南京得了半壁江山,洪教主从41岁开始,直到11年后自杀,竟然没出南京城一步。大概是收罗的漂亮的妇女同志太多了,实在没有时间干别的。
比起张大义军领袖的变态,洪教主还是比较有人性。好色,人之天性。
不过洪教主进南京,并没有因为女性的爱情滋润,而让他变得温柔。虽然没有张大领袖变态,实行的也是三光政策:杀光、烧光、抢光。
“凡掳之人,每视其人之手,如掌心红润,十指无重茧者,恒指为妖,或一见即杀,或问答后杀,或不胜刑掠自承为妖杀,或竞捶楚以死。”大意是手上没长茧子的就是妖人,就要统统杀掉。
农民起义带来的不是均田地等贵贱的乌托邦,而是血腥恐怖
说起洪教主玩弄的美女确实让人流口水,除了88个妃子外,女官侍婢不计其数,算下来用了11年时间玩了2300名妇女。
有一本《江南春梦笔记》:王后娘娘下辖爱娘、嬉娘、妙女、姣女等16个名位共208人;24个王妃名下辖姹女、元女等七个名位共960人,两者共计1169人。以上都属嫔妃,都是要和洪秀全同床共枕的。天王府不设太监,所以另外还有许多服役的“女官”。以二品掌率60人各辖女司20人计算,合计为1200人。各项人数加起来,总计有2300多名妇女在天王府陪侍洪秀全一个人。
一个农民当了教主,就有这样的眼福。换做了傻空当教主,会怎么做?
黄巢比洪教主学问要高一些,但是屡试不第,当了私盐贩子。
从起义的第一天开始,黄巢的脑子里也从来没有过百姓该如何如何的。
他是一个彻头彻尾的投机分子,说是义军,不如说是强盗。
新唐书中说,贼军所过州县,老百姓皆烧杀殆尽。黄巢的兵可并不懂三大纪律八项注意,那是能抢救抢,抢不了就烧就杀。
无论是旧唐书、新唐书、还是资治通鉴,从头到尾,就没有出现过黄巢的一句好话。
黄巢攻陷广州,至少屠杀了十二万人,把皇帝气晕了。
皇帝还知道体恤子民呢,而黄巢就是彻头彻尾的强盗外加杀人犯。
黄巢攻进长安当了天子,充分显现了流氓无产者的本质,穷奢极欲,挥霍无度,治理国家的事彷佛就跟他没有一点关系。不搞建设就只能做吃山空,结果长安的粮食都被糟蹋完了。
长安没有余粮,黄巢就把长安老百姓抓来,煮着吃,十万大军靠吃老百姓过日子。
幸好老天开眼,官军打进了长安,结果是老百姓对官军夹道欢迎。
农民军真是义军吗?
不但中国的农民军领袖都是杀人魔鬼的化身,就是法国资产阶级大革命领袖罗伯斯皮尔,同样也是法西斯暴政的先驱者。最后被人民送上了断头台。
只有一个真正的法制化国家,人民在法律的制约下,享有人身与财产自由,才能够安居乐业。
李自成在军队纪律上,是要比张献忠高明一点的,所以李自成打进了北京。李自成到北京后,拷贝了黄巢进长安的淫乐经验,对美女极尽淫乱之能事,对百姓烧杀抢劫做的也很出色。
历代农民军对妇女的态度与《水浒传》中梁山好汉完全相反。
施耐庵笔下的梁山好汉们似乎对妇女有天生的仇视,动不动就把女同志劈死,李逵甚至终生不尽女色,就凭这一点,我们只能说梁山好汉是农民军中的异类。
但是梁山好汉不是为了起义,而是为了招安。一群由小公务员和渔民组成的社会最底层群众梦想通过拉山头再跳槽的方式走进金字塔的中层,但是这个梦想破灭了。
古代历史上,能够治理天下的穷苦人,只有一个:朱元璋。#card
朱元璋
为什么朱元璋可以,而别人不可以。
经过仔细研究发现,朱元璋的人生际遇不像黄巢、张献忠和李自成,他有点像刘邦,但又有很大区别。
朱元璋是一个到处要饭吃的和尚,但是喜欢思考,见世面,交朋友,并且找到了自己的宗教信仰——明教(也叫摩尼教、白莲教)。
朱元璋走投无路投奔起义军的时候,娶了起义军濠州大帅郭子兴的义女当老婆,就是那个著名的马皇后。郭子兴并不是一个农民,而是一个大地主,所以朱元璋加入的这个新家族,思想完全不同一个扛着扁担造反的农民。
郭子兴作为农民军的统帅,却在逛街的路上,被其他的农民军兄弟(真正的农民)绑了票,大概是因为农民对地主阶级比较仇恨。最后被朱元璋救了出来。
郭子兴看见朱元璋比自己强,反而起了憎恨之心,一心想把朱元璋弄死。
朱元璋在丰富的人生经历中看到了农民起义军领袖们的鼠目寸光,要想成大事,必须有远大的理想和抱负,而这些是黄巢、张献忠、李自成、洪秀全都没有的。
朱元璋与那些个农民军领袖最大的不同在于,他熟读历史,因此他把汉高祖刘邦作为榜样。目标是建立一个基业长青的强大统一的国家。
朱元璋就懂得无论是得到天下,还是治理天下,就必须有能力的人来辅佐。嫉贤妒能的人只能被历史的车轮碾碎。#card
曹参治国
人们最希望的,就是在一个良好的社会环境下,安居乐业,自食其力。政府的职责就是健全法制,维护一个良好的环境,剩下的事,交给民间去做。三天两头出政策,过度插手百姓如何过日子,甚至朝令夕改,就会让百姓的正常生产生活无所适从。
早在汉朝初期,曹参已经参悟了这个道理。
曹参是刘邦当亭长时的领导,也是刘邦最亲密的战友。萧何是文官,曹参则是武将,曾经在韩信麾下效力,除了披坚执锐外,最重要的工作就是监视韩信,防止韩大军事家谋反。
这样一个万夫难敌的勇将,却在革命胜利后被分配给齐王刘肥(刘邦的私生子)当相国,主抓齐国的政务。
曹参是一介武夫,只懂得军事,并不懂治理地方,就用厚礼聘请了精通黄老之术的盖公。盖公认为:治理国家很简单,只要按照律法办事,给老百姓提供一个安全的稳定的环境,其他的都不用管,官府千万不要好大喜功,追求政绩,过多插手百姓的事物,顺其自然就好了。
曹参很赏识盖公,并且按照盖公的话去做,九年的时间,齐国变得非常繁荣。
这时候,传来噩耗,萧何挂了,皇帝刘盈聘请曹参出任相国。曹参上任以后,几乎罢免了所有办事效率高、口才好,有追求有抱负的能吏,提拔了一群只知道按部就班,照章办事的老实巴交的官员,然后就彻底大松心,成天喝酒吃肉听小曲。
很多人对曹参不满就给皇帝刘盈打小报告,刘盈的表现是很愤怒。
曹参就问刘盈:是陛下你牛呢,还是先皇刘邦牛呢?
刘盈:当然是先皇牛
曹参又问:那我跟萧何比,谁牛呢?
刘盈愤怒的说:你比萧何差远了。
曹参做了个总结:您讲的太对了,先皇和萧相国拟定的法令已经非常清楚了,只要贯彻执行下去就好,我只要按照他们的法令办,不就行了吗?
刘盈虽然不事朝政,但应该算是比较聪明的君主,一听就懂:对于已经定下的治国方针大略,只要执行下去,一定会使人民休养生息,国家富足。如果大搞政绩工程,对于先皇刚死,吕后掌权时期风雨飘摇的大汉来说,将是灾难性的。
民间把成天喝酒吃肉听小曲的曹参称为贤相。司马迁在史记中也给了曹参极高的评价。
假设一个工程队要盖楼房,起初设计人员设计了20层,刚盖了两层,队长换人了,非要盖成30层,工人于是绞尽脑汁费劲办法改造。等盖到25层的时候,又换队长了,新队长说还是改成两层的别墅吧。刚把楼房都拆掉,别墅建了一半,又来了一个队长,说要建成比迪拜塔还高的大塔楼。这个楼建了n年也没建起来。
建房子跟治国的道理是一样的,我国汉代的相国曹参就已经明白了这个道理。#card
[[晁错]]
民营小企业的老板和打工者
糊涂人即使把道理说的再浅显,他也听不明白,呵呵。
现在我国已经进入高通胀期,但是地方巨额债务与人民币的升值又封杀了加息的空间,经济形式有可能恶化,民营小企业的老板和打工者只能自求多福了。
汝爱之罪:
刚查了一下央行的数据,8月份的M2是68.75万亿,我没记错的话,7月份的M2控制的很好,基本没怎么涨,但是到了8月份,没想到有那么猛的涨幅,看来不到12月,我国的M2就要到70万亿了。2007年1月份,我国的货币供应量是35万亿。
今早去小摊买早点,原来一块五的加鸡蛋灌饼现在卖两块。如果涨工资,只会把通胀越推越高,如果不涨工资,P民就要忍受通胀的剥削。真是无语了 #card
郭解
从古到今,小老百姓遇到不公,受了委屈,幻想最多的就是跳出一个大侠,劫富济贫,为自己伸张正义。所以金庸的小说广为流传,被称为成年人的童话。
我国古代,真有大侠,不过古代的大侠并不是会降龙十八掌的郭靖,也不是小李飞刀,而是黑帮的老大,相当于西方的教父。
最有名的大侠叫郭解,汉朝时有极高的威望,不然也不会写进史记。
郭解的爸爸是个职业杀手,非常有名,用古龙的话说,最厉害的杀手是没有名字的,郭解的老爸名声太大,注定活不长。有个米商请郭解的老爸到监狱里救出犯了法的儿子,郭老爸看在钱的份上去了,就再也没能回来。
郭解跟他老爸学过功夫,很有两下子,于是干起了抢劫和盗墓的这份很有前途的职业。因为功夫高,谁只要说句话让他不爱听,必然遭遇一顿暴打。本着流氓会武术谁也挡不住的精神,到了三十岁,郭解已经钱多的数不过来了。男怕入错行,女怕嫁错郎,看来抢劫和盗墓的职业选择对了。
30岁以后,郭解为了从强盗升级为教父,开始积累自己的名声,并且学习战国四公子,开始蓄养门客,但凡是哪个人有难,有求必应。俨然形成了一个严密的黑社会组织。在民间的声望,甚至超过了皇帝。
皇帝的权威是不容冒犯的,一个地方黑社会头子怎么能够这么嚣张呢?就把郭解抓了起来,虽然有大量的证据证明郭解作奸犯科草菅人命,但都是汉武帝大赦前的事情,没有办法定罪。汉武帝一筹莫展,人抓了不能定罪,又不能放掉,该怎么办呢?
这时,正好有个书生,骂郭解不遵纪守法。正巧被郭解的门客听到了,就把那个书生给杀了。
汉武帝听了哈哈大笑,正巧找这个理由把郭解灭族。
侠客的黄金时代,从此结束
剑侠情侣,快意江湖,听着是一个充满了浪漫的世界,而事实是完全不可取,一个没有法制的社会,奉行者赤裸裸的丛林法则,什么是对?什么又是错?理由就永远站在强者一边,强者可以随自己的意愿决定弱者的生死。
这个社会是可怕的。
郭解,就让他永远埋葬吧 #card
2010年的中国房地产
汝爱之罪:
今天跟家里人打电话,姨妈说了下近一年来老家云南东北方向一个地级市曲靖的变化。
主要就是:好些有资金的外地大佬大手笔拿地,开发酒店和商品房。都是市区的黄金地段。
其实房地产开发在中国的任何一个城市每天都在发生,不过令人感慨的是这样的“四线”城市也如此火爆,购买力之强令人感慨,她说最近几天曲靖正在举行房交会,人头攒动。
现在老百姓有钱都向往好的房子和户型了,已经不满足90年代的老旧房子了,而且通货膨胀也逼得大家不得不置业保值。
再回头看看北京,简直找不到跌的理由。那么多地铁要修,那么多优质生源每年涌向北京高校,那么多人口,每天要造就那么多富人。。。。
kkndme:
钱太多了,流动性泛滥,老百姓恐慌了。这次调控暂时抑制了一线城市房价的上涨势头,但是却直接导致了全国性房价的上涨,不光二三线城市,连四级以下城市都是如此。这就是领导水平。#card
精英人群的平均收入决定房价
skysurfer2208:
想请教一下楼主,对于很多的二线城市,比如武汉,市区房子的均价一万左右了,但当地的平均收入一般也就3000左右吧,难倒你不认为现在的房价里面有泡沫吗?特别是现在正处在调控期,对于我们这些近年打算买房的来说,是在等等看呢还是在在这个时期出手?多谢楼主
kkndme:
你所说的平均收入是什么概念?是人人都挣3000块,还是有人挣2000块,有人挣1万块。武汉的房价,要看湖北省包括各地市的人口,家庭收入上万的人有多少,如果你认为很少,几乎没有,那房价肯定存在泡沫。如果湖北省有20%的人口家庭月收入超过万元,那么武汉市区的房价就没有泡沫。#card
内地不是香港、海南
johny__:
那香港97年的时候还不是一样跌了一大截,按LZ的说法,1)土地资源很稀缺;2)作为消费群体的白领收入也能买房;3)作为世界城市,更是汇聚了世界级精英的购买力,仿佛现在上海。最后,不是一样大跌??中产都成了负资产了。就连林百欣的儿子林建岳97年以69亿港元高价购入中环富丽华,还不是赔得一塌糊涂。
楼价涨高了就要跌,哪都不例外,这个才是规律。什么通涨,精英购买力决定房价,都是涨了之后在找理由。
kkndme:
这就是体制上的不同啊,所以我们无法重复香港和日本。97年的金融风暴,还是中国以国家之力对抗索罗斯的量子基金,保住了香港,这种行为在西方国家是难以想象的。一个国家动用全国人民的外汇储备与美国的民间资本打一场战争,这是令全世界震惊的。索罗斯因为不了解中国的体制,悻悻而归。
人民币不能在世界流通,依照我国实行的货币制度,货币只不过是一种符号。如果有一天我们的人民币能够自由兑换,香港发生的事也一定会发生在我们身上,但你认为我们的人民币能够自由兑换吗?
johny__:
那92年的海南崩盘有从何说起?从7000多掉到了几百元,这难道是海南体制?发币行是海南银行?同样是国内,同样的外汇管理制度,不是日本也不是香港,是中国海南。
–据《中国房地产市场年鉴(1996)》统计,1988年,海南商品房平均价格为1350元/平方米,1991年为1400元/平方米,1992年猛涨至5000元/平方米,1993年达到7500元/平方米的顶峰。短短三年,增长超过4倍。
–海峡对岸的北海,沉淀资金甚至高达200亿元,烂尾楼面积超过了三亚,被称为中国的“泡沫经济博物馆”。
[经验交流]92年海南房地产泡沫始自于“击鼓传花”(转载)
http://www.tianya.cn/publicforum/content/house/1/163988.shtml
kkndme:
全国的资金去炒海南、北海,炒的纯粹是概念,没有实体的支撑,就是一种博傻游戏。今年年初海南房地产的爆炒,同样积聚了巨大的风险。买房并不是全无风险,好比通州、燕郊,经历疯狂的炒作一定会理性的回归。但是如果指望北京四环内房价下跌,也只是痴心妄想。
房产投资也不是随便买套房就只涨不跌,比如说山东乳山的房子,开发商疯狂炒作旅游地产概念,但如果真的想投资升值,那就成了天大的笑话,因为根本无法变现。
什么样的房产适合投资,投资者不是傻子,都会有理性的判断。
90年代初的强硬调控让海南和北海的经济崩盘,对全国来说不可怕,毕竟只是一隅之地,但是如果用粗暴手段搞崩了全国,政府一定会好好掂量的。#card
历史是一面镜子
如果以为本帖讲的历史故事,那就完全理解错了。
本帖讲得不是历史,而是总结前人的经验,讲得是故事背后的道理。
如果毛不是熟读历史,也不可能取得胜利。毛在进京的时候,说过一句话:我们不学李自成。
只有认真总结过李自成失败的教训,才能够做出正确的选择。#card
买房一次性到位比较好
包容会通:
我老婆是长春人,岳父母退休,都有退休金.我和我老婆现在都在国外,准备3年以后回长春工作,我们现在有40万的现金,放在银行也没什么用,也担心3年以后,长春的房价还要涨.
因此,现在准备用其中的20万作首付买套70平的小户型的,让岳父母住(岳父母有住房,但很快就要拆迁了).等3年以后回长春,把这套小的卖了换成大的.不知这样的计划是否可行?贷款如何弄?
谢谢兄弟.
kkndme:
既然是自住型需求,何不买套大点的,70平(建筑面积)的房子无论是自住、父母住还是合住,都比较拥挤。既然有40万的闲钱,还是一次到位比较好,3年后长春的房价一定要比现在高的多。
只是贷款比较麻烦,你的父母是无法贷款的,除非你们夫妻能够回国,这种事用别人的名字办肯定是不行的,房价上涨后就有可能会陷入扯皮甚至打官司的境地。#card
一线和二线
yamazaki28:
楼主好,小弟有问题请教,本人所在二线省会城市,存款40w,近来看中本市CBD区域高端住住宅一套,各方面条件十分优越,面积100左右,均价18000。但通过观察,又看中觉得北京五环附近的待建地铁房,均价16000,想贷款弄小户型60左右,不知哪个升值潜力大,本人已有房一套。谢楼主指点。
kkndme:
短期来看,二三线城市的房产升值速度要高于北京,这是这次调控造成的结果,从长期来看,北京房产的升值速度要高于二三线城市。五环附近地铁房,还是很有优势的。#card
商铺和住宅
deeplp:
kkndme 兄,你好。
从这个帖子一开始就一只跟着,每天必看。受益良多。
你对广州感觉如何?请教一个问题,不知你对商铺是否有研究?你觉得眼下投资商铺好呢,还是继续投资房产。
本人已有2套房产,都在广州市区且近地铁但不带很好学位。现有如下两个想法,
- 分散投资,投资一个商铺,目前看中一个广州北京路拐弯处二楼商铺一个,靠近地铁。
- 继续房产,买一个130以上大户型且带学位房,方便以后小孩读书。(计划明年要小孩,现在就做打算是怕以后买不起阿。)
麻烦兄台给些意见。十分感谢。
kkndme:
找到合适的商铺是很难的,因为商铺投资风险大,所以非常考验个人的眼光,属于高风险高回报,找对了,将财源滚滚,找错了很可能血本无归。
如果你有眼光,首选商铺。如果不具备这方面的能力投资住宅比较保险。#card
[[买房:物业与房贷]]
体制内的28原则
facetowall:
有人说,高校里20%的人掌握着80%的资源和财源,本人深有同感。所以经常想怎样才能成为20%里面的人。每天也很努力工作着,科研教学也可以,但是总看不到希望。
kkndme:
从一个小吏变成中高级干部,是需要深入研究中国古代政治斗争史的。否则就变成了宋江,企图另立山头通过跳槽达到目的,最终的结果只能是失败。宋江是一个政治上的白痴。
还有一个白痴叫贾谊,我们所熟知的“过秦论”的作者,才高八斗,政治却很白痴。被文帝做了棋子。如果贾谊同志知道晁错的下场,是无论如何不会仗着有才胡说八道,口无遮拦的 #card
贾谊
贾谊的粉墨登场,是有很深的政治大背景的。
首先要从吕雉死翘翘,以陈平、周勃为首的功臣集团铲出了吕氏一党说起。
吕氏一党灰飞烟灭,小皇帝是个吕雉制造出来的傀儡,甚至跟高祖刘邦都没有任何血缘关系。
难题是让谁当皇帝呢?
于是中国历史上最为搞笑的一幕发生了,在高祖刘邦的子孙中要搞最弱外戚选举。
大概是被吕雉专权搞怕了,大家推举皇帝,专门看哪个皇子的外戚弱。于是众人的目光投向了刘邦的第四个儿子,代王刘恒。原因是刘恒的母亲薄氏出身低微,为人又很低调,堪当最弱外戚之名望。
提起薄氏,野史里记载的很香艳,很可以拍三级片
野史里说,楚汉争霸时期,高祖刘邦大败。
薄氏还是个姑娘的时候叫薄姬,逃难的时候占领了一个无人居住的民宅。忽然有一天看见一个浑身是血,穿着盔甲拿着兵器的男人闯进了自己的屋子,这个人就是刘邦。
薄姬听到后面有追兵,就把刘邦的盔甲和兵器藏了起来。然后放了一大桶洗澡水,把自己和刘邦脱光光,洗起了鸳鸯浴。追兵闯了进来,惊奇的看了一通三级片,然后走人。
这个只是野史,可信度不高,但是说明了薄氏的低微出身。
不管怎麽说,有着最弱外戚称号,并且做事很低调的刘恒当了皇帝。但是对于刘恒来说,陈平、周勃等功臣集团有着很高的声望,齐王刘襄是高祖长孙并且在铲除吕党是很有功劳,声望也很高,受到了很多人的支持,而刘恒却毫无功劳,因为功臣集团平衡关系,天上掉下了皇帝的帽子,砸在自己脑袋上。
所以刘恒必须提拔自己人,这个人不能有很高的功劳,也不能有结党的嫌疑,最好比较有本事能治理国家,于是大才子贾谊粉墨登场了
贾谊同志很有口才,一腔热血,要到现在来说最适合搞传销或者卖保险。
贾谊同志激愤起来甚至说:自己完全可以带兵打仗,灭了匈奴,把匈奴王象狗一样牵回来。”刘恒很贤德,但也很老谋深算,当然认为贾谊同志满嘴喷粪,所以一笑置之。
贾谊同志的胆子不是一般的大,向皇帝刘恒提供了一个深的帝心的建议:让所有的诸侯王滚回自己的封地。
为什么说这是深得帝心的建议?因为朝里功劳大的人太多,居功自傲,而自己却没有什么威望和功绩,如果功臣集团和齐王、淮南王联合起来造反怎么办?
所以,最好的办法就是让诸侯王滚回封地。汉代的诸侯王可跟周朝不同,周朝的诸侯王是有实权的,有自己的军队。而汉代的诸侯王只能收收领地的税,军政事务全说了不算。
这个事,从贾谊嘴里说出来最好不过。
汉代的京城是最繁华的,有全国最好的教育、医疗、商业,有钱人的天堂,大臣们都可以花天酒地。让诸侯王回到封地,大家都不干了,回封地有什么好?房价又低,又没什么娱乐,漂亮姑娘也不好找,偏远的地方气候还不好,梅雨一来全身都要发霉。
首先带头反对的是功臣集团的领袖周勃(陈平已经死翘翘了)。在历朝历代,多数皇帝并不是想干什么就干什么的。既然所有大臣都反对,那就先暂且作罢。
但是贾谊,已经为刘恒种下了希望的种子,给自己埋下了祸根。
贾谊注定了只能是一颗棋子。
贾谊的建议没有被采纳,估计很郁闷,成天滔滔不绝的演讲,甚至建议刘恒削藩,要是贾谊知道晁错的下场,一定不敢这么建议。
这时候,贾谊已经得罪光了朝中几乎所有的大臣。于是大家的不满全部转移到贾谊的身上。
刘恒要的就是这个效果。
随着政权的逐渐稳固,刘恒把矛头指向了周勃。给予周勃最高的赏赐,却经常在治理国家方面,询问一些周勃不可能知道的问题。让周勃很尴尬。
周勃有个门客,就对周勃说:“皇帝经常给你很多赏赐,您就安心的接受,这很危险。皇帝给你的赏赐越多,说明皇帝对您越不放心啊。”
功高震主,弄不好会有杀身之祸,周勃不是傻子,立刻明白了这个道理。所以周勃才能称的上除曹参外,最有政治头脑的武将,最后得了善终。
于是周勃就上表辞职,表示年老体病干不动了。周勃还期望皇帝能挽留一下,但皇帝一点挽留的意思都没有,立刻同意了。
刘恒让周勃起个带头作用,回到自己的封地去吧。并且赐予了大把的金银。其他诸侯王看周勃都走了,也扛不住了,只好都回到了封地,这叫射人先射马,擒贼先擒王。
刘恒为了安抚大家,把遭人恨的贾谊明升暗降,贬到了长沙,从此离开了政治中心。
后来有一天,刘恒想起了贾谊,找他来中央谈话。贾谊一见皇帝立刻滔滔不绝,把皇帝立马侃晕了。
刘恒想:我靠,这厮死不悔改,留着没用,有多远滚多远吧。
再次把贾谊贬到了梁国。
贾谊不多久就死了。
关于魏豹和薄姬是否有一腿,也不好就肯定,也是个悬疑。因为记载薄姬的版本太多,我国古代人也比较八卦,呵呵。#card
不要低估通货膨胀
someway2010:
跟楼主请教一下:
楼主怎么看知春里小区的房子?那边连着双榆树小区,有大片的老房子,都是6层的板楼,都是上世纪8、90年代建的。环境看起来有点乱,以前的老公房,原单位早就没了,物业基本等于没有。将来拆迁的可能性有多大?值得买不?
kkndme::
只要是4环内保值升值不会有问题,那个位置还是可以。关键是看投资还是自住,如果是自住,我就觉得那边有点乱糟糟的,不舒服。挨着中关村其实住着都不舒服,但不耽误升值。
someway2010:
多谢楼主,是自住因为老公在中关村上班,想离公司近些,所以就挑了那里是挺乱的,唉~
希望以后等我们有钱了能换个别的地方的大房子,不过按照楼主的分析这个是极有可能实现不了了。。。5555~~~~~~
再问一个,现在市场上卖200w的房子,十年后大概会涨到多少钱?麻烦楼主
kkndme::
80年代你想象不出以后一瓶茅台会卖1000块
现在你同样想象不出十年后你的房子能卖多少钱。
那时也许人民币都是1000块一张的 #card
二三线城市与重庆
dali_05:
浏览了楼主观点,和我之前的货币推动楼市的看法完全一致
但由于无法像楼主那样掌握一些基础数据,对一些楼市的演变细节还有几个疑问
,还请lz指点
(1)二三线城市在这轮调控中的增长不出意料,但是二三线城市的房价增长,我始终认为存在一个最终谁接盘的问题。我是重庆人,以重庆为例,这个城市代表了典型的二三线城市。外来人口少,特别是外来的普通白领阶层。据我了解的数据,2008年之前,重庆的具备房子购买力的人群任然是净流出。到08年后才得以改观。但是流入任然缓慢,这也就是意味着重庆的楼市将没有长期稳定的接盘群体。而本地人,没有房子的是非常少的。在没有外来人群接盘的情况下,本地人在有房的情况下,任然投资囤积房产,最终,这些房产将如何变现。
一句话,房价要持续的上涨,还得有没房者接盘,而且这些人还得要有购买力。多次购房者无法稳定的解决这个问题。那么我就有理由对这样的二三线城市的房产前景表示担忧。
kkndme:
重庆房价的上涨得益于中央的战略规划,打造中国的大后方,把重庆的经济发展提升到了政治的高度。因为如果发生战争,重庆将变成第二首都,是中国最安全的大后方,蒋同志就很有眼光的选择过重庆。
重庆并不是以城中心为核心向外辐射的城市,繁华区域相对比较分散,所以房价很难快速上涨。这也就是过去重庆长期滞涨的原因。
重庆房价的崛起可以说完全是中央规划概念推动的,至于日后是否会吸引大量的精英和富人来重庆发展,我想一定可以。作为上升到国家政治高度的发展计划,就算是代价再大,也一定会搞得起来。
dali_05:
(2)高端房产还是普通住宅?
看了lz的观点,认为高端房产,由于其稀缺性,更具价值。
但我认为,房产和古玩还是存在差别的。古玩最大的价值在于收藏把玩,只要有钱,买再多古玩来玩都无所谓。但是房产不一样,房产的价值除了和古玩一样的投资外,真正的功能在于居住。但是目前的二三线城市,精英阶层的数量是非常有限的,他们谁没个3,5套别墅,在没有外来精英加入购买的前提下,这些高端的房产也就是在精英圈子中流转,这样封闭的流转,如何实现价值的增长呢?
要知道,在2,3线城市,普通白领阶层能跳出自己的阶层而具备购买高端房产能力的概率是非常小的,不具有代表性。那这些每个富人,有权人都有很多的高端房产有什么价值可言?
而普通住宅由于有普通白领的接盘,是否投资价值更大?
kkndme:
二三线城市房价的支撑,要因城市而异的,大体上二三线城市的核心区域与高端住宅区都不会有问题。毕竟一线城市的体量,不可能满足全国中产以上群体定居,而且一线城市随着竞争的日益激烈,钱也不是那么好赚的。有很大比例的富裕人群仍会选择二三线城市生活。
中国的二三线城市的富裕人口,要比大家想象的多的多,特别是二三线城市,有相当比例的人口都有较高的隐性收入,权力寻租现象更为严重。
dali_05:
(3)长期持有房产的变数
中国房产只有70年,甚至50年的使用权,如果长期持有,随着时间推移,房产价值是否会受到影响。因为我在重庆,这个问题尤其严重,重庆只有50年。
如果我只是持有,出租。那我的租金将是较低的(相对房价而言),因为政府不会允许房租像房价那样疯涨,原因和粮食问题一样,基本需求嘛。那有可能50年到了,我的房租收益实际上还抵不上房款的综合支出。而那时房子早就是危房了,强拆将是完全可能的情况。那做为普通人,怎么可能和政府在赔偿上博弈。这个风险lz是怎么理解的??
我的理解是,房子不能长期持有,必须在5年左右变现,否则将存在贬值和变现难度加大的风险,请lz指点
kkndme:
关于中国的房产能够持有多少年的问题,这要持续观察政府的动向。对于现在的80后来说,如果在有生之年能够平安度过,不经历大的动乱,已经是很值得庆幸了。
如果有动乱发生,即使你没有买房,你手中的现金也将变成废纸。
dali_05:
(4)天津现象(或者即将出现的重庆现象)
天津房价在二线城市中增长是惊人的,但收入水平并没有达到那样的高度。这种依靠所谓开发区吸引资金推动房价的模式,是否具备可持续性??
我认为真正的天津常住精英阶层的资金实力是无法支撑这样的价格的,只能理解是外来游资的介入,推高了价格。
我想问的是,这些游资有可能退去吗,一旦退去,面临的风险是否很大。
据我的理解,中国真正成功的开发区,都是由于本身的条件好,而非开发区本身的作用。
比如深圳,享受的是经济转型的首发政策优势。上海浦东是由于本身就实力雄厚。而所谓的滨海新区,重庆两江新区,本身实力就不过如此,即使要真正实力上来,那也将是非常漫长的过程。那这些进入房地产的游资,将在概念炒作一遍之后,获得一定收益后撤出,一旦撤出,这些地区的房价将会是怎样的趋势?
放眼中国,房价高的地方无不是富人集中,或周边富人多的区域。天津重庆这样的地方,一旦外地资金撤出,将何去何从?
(5)新兴城区和老核心城区
新兴城区环境好,轨道交通也使得原本偏远的新兴城区变得方便起来。那老核心城区的房产是否不如这样的新兴城区有价值。这个问题一直很困惑。因为我是重庆人,这个问题尤其明显。现在重庆房价最高的是以前的郊区,江北,渝北。而传统的渝中,房价反而排着中等水平。这和北京的一二环贵,上海的黄埔徐汇贵完全不同。这样的状况具备可持续性吗,还是仅仅是阶段性的。但是感觉现在政府的规划更倾向于向外发展,避免主城区拆迁的高成本,这会否导致传统主城区的边缘化
先问这几个问题,困惑很久了,期待lz的高论 #card
城区和郊区
hey-hey:
楼主 我在上海, 小白领一枚。最近想买房。稍微好点的区均价已经至少2万5+了, 现在考虑在其他价格洼地的区买套新房,看中了均价1万7左右,买90送30,到手面积120左右。此楼盘开发建造定位2万/米以上,因政策调控,故现1万7。好处是小区规划不错,属大型国企房产公司,2012年交房。附近有超大型公园,地铁明年开通(升值利好),附近有医院,学校,路上看到的在建建筑较多(百废待兴)。不好处是离上班开车要1个小时,属工业区(在另外一个方向),路上集卡较多,有传空气质量不好。
另外一个选择是在市中心或其他比较好的区买个小房子,大概5、60平方米左右,预算也是180万左右。 好处是地段好,租金回报可能较高。如果自住相对比较方便。
单身,买房投资愿望大于自住愿望。 请楼主给分析分析。谢谢
kkndme:
多数人买房子都是郊区买个大的,后来上班实在不方便,再想办法城里买套小的。住郊区牺牲时间,住城里牺牲面积。总得来说,还是住城里更方便些。
关于房价升值,一定是郊区和城区版块轮动的。当郊区房价较低时,资金就会关注价值洼地,当郊区房价炒起来以后,城区的房价跟着上涨,但总的来说,城区的房价涨幅一定高于郊区,且比郊区更抗跌。
hey-hey:
谢谢楼主。真是纠结阿。一样的钱想买个新点的。而且周边的觉着还有这样那样的优势,比如公园,比如现在的性价比。比如大了一倍。比如该区未来发展空间和前途。如路建好了地铁修好了,城市辐射发展的面扩展了。
市区现在虽然完善,但未来没什么发展空间,该发展的都饱和了该配套的都配好了。升值的空间是否相对就小了。
还请楼主再给说说。
kkndme:
你说的其实还是性价比的问题,比如郊区(前提是配套能发展的起来)1万7,城区2万5,那肯定是选择城区,毕竟相差不大。如果郊区1万7,城区3万以上,那肯定选择郊区。
好比北京的通州,城区2万的时候,通州8000,肯定选择通州,升值会快。但城区3万,通州2万5的时候,肯定会选城区。#card
人制的社会,人就是制度
让李荣融来讲垄断巨头的功劳,这个事很有意思。
西汉时期,功臣集团和他们的后人势力比较大,大街上瞎晃的黑社会头子比较多,皇帝提倡以法治国,靠法律来制约功臣集团,先是重用了皇宫守大门出身的张释之大法官。
张法官完全按法律办事,该杀头的绝不会流放,但是该流放的也绝不会杀头。张大法官实现了我国历代百姓追求的天下无冤民的梦想。
史书上记录:汉文帝车驾过中渭桥,一个人从桥底下突然钻出来把皇帝的御马惊了,刘恒很生气,让张法官治他的罪。张法官审讯后发现是个意外,属于民事事件,打算罚点钱放掉。刘恒不干了,那可是惊了圣驾呀。罪该杀头。张法官却认为:律条上没有说因意外惊了圣驾就必须杀头,按律条就应该罚钱放人。要不然陛下你就不要把这个人交给我审,直接杀掉算了。既然陛下让我审,就必须按法律办事。刘恒只好按照张法官的审判结果,放掉了那个人。
其实,遵守法律,按照法律办事的不仅仅是张法官,而是刘恒自己。刘恒为了保证社会安定、基业长青,就必须限制特权阶层,限制特权阶层就必须依法治国。
但是文景之后,武帝就不满足于完全依法办事的张释之法官这样的人了,而是开始重用酷吏,张汤、义纵、宁成这些新一代法官登上了历史舞台。法律是什么?法律就是张汤,张汤就是法律,犯了法的要往死理打,没犯法的也要往死里打。
唐朝武则天时期,出现了一个史无前例的酷吏:来俊臣。
来俊臣法官不管法律专搞冤狱,专门养了一大群打手无赖,凡是武则天不喜欢的人,还有他自己不喜欢的人,一律刑讯逼供,屈打成招。发明的酷刑比张汤有过之而无不及。
古代,法律是什么?是皇帝?是张释之?是张汤? 是来俊臣?其实,法律什么都不是。#card
准公务员的好处
一线杭州
转篇文章:一个忽悠了几亿中国人的伪概念:所谓“中国房地产泡沫”
中年不惑吗:
一个忽悠了几亿中国人的伪概念-所谓“中国房地产泡沫”
作者:罗伯特卡帕
中国大陆大家目前最为关心,讨论最为热烈的一个问题就是中国的房地产泡沫问题。从政府到民间,从经济专家到普通百姓,大家都在关注这个问题。以前,我也觉得中国存在一个叫“中国房地产泡沫”的所谓概念,但今天我忽然感悟,原来多少年来包括我在内的几亿中国人都被蒙骗了,中国根本就不存在所谓“房地产泡沫”的问题,“房地产泡沫”这个概念本身就是一个伪概念。
如同市场经济一样,房地产泡沫也是一个外来事物,它是市场经济的产物。但问题是,中国是市场经济吗?显然不是,否则为什么大多数西方国家都不承认中国是一个市场经济国家。尤其是中国大陆的房地产市场,更不是市场经济,而是计划经济与市场经济相结合的一个怪物,政府操纵着房地产行业,政府对房地产有着绝对的掌控能力。
房地产泡沫是市场经济的产物,既然是泡沫,那么这个泡沫也会遵循市场经济的规律,即当泡沫足够大的时候,会破裂。因为日本与美国的经济是市场经济,所以当日本与美国的房地产产生泡沫的时候,就会破裂。
目前包括中国在内的几乎所有世界经济学家都以为,当年日本与美国的房地产泡沫破裂了,中国的房地产泡沫比日美大几倍,当然也会破裂。事实却是,中国的房地产泡沫在几年年前的膨胀程度就超过了当年日本与美国的房地产泡沫,中国的泡沫几年来虽然翻倍,但却没有破裂,这是何故?显然,经济学家们犯了一个错误,那就是把中国的房地产乃至中国经济当成了市场经济来看待,而事实是中国的房地产市场根本不是市场经济。所以,西方市场经济国家所有的房地产泡沫,在中国也根本不存在,所谓的“中国房地产泡沫”根本就是一个伪概念。
当然,我说到这里时,肯定有很多人不服气,中国的房地产明明几年之内翻了很多倍,远远超过了普通人的收入水平,这不是泡沫这是什么?我的回答是,中国的房地产价格确实虚高,远远超过普通人的收入水平,这是事实,但这不是“房地产泡沫”,因为泡沫会破,而中国的这个被大家称为“泡沫”的东西却不会破,因为它的真实名字其实不叫泡沫,应该叫“变相的税收”或者“房地产垄断价格”。
中国的房地产业本质上已经不是一种行业,像中国大陆的税收与垄断行业的垄断价格一样,成了少数人剥夺多数人财富的一种工具。在这个工具上,寄生着很多食利者。这个食物链的最上层为地方政府,地方政府通过卖地与房地产税收,养着一大批高薪的公务员及满足他们的奢侈需求。食物链的第二层为与官员勾结的房地产商以及受贿吃回扣的官员,第三层是炒房者,炒房者相当部分为拥有大量现金的官员及家属。
市场经济的泡沫会破裂的,但中国的房地产不是市场经济,房地产价格也不是“泡沫”,所以它也不会破裂。中国的房地产价格被政府严格操控着,不说是操控自如,也是有绝对的控制力。因为政府掌控着土地银行汇率等房地产的关键要素。中国的高税收是泡沫吗?中国的垄断行业的高垄断价格如水价电价油价是泡沫吗?当然不是,他们是转移财富的手段。中国的房地产价格也是一种变相的“税收与垄断价格”,其“税率”与“垄断价格”是政府控制的。这也解释了为何中国几年来房价如此之高,却不下跌,所谓“泡沫”却不破裂的原因。
中国房地产的所谓“泡沫”会“破裂”吗?会,只要政府愿意。中国的房地产的“泡沫”会不破裂吗?会,只要政府愿意。
其实,中国所有的问题都是政治问题,而不是经济问题,离开政治谈经济,永远找不到问题的答案。#card
城市底层
游泳横渡马六甲:
经常有人说收入是决定因素,其实人均收入没有意义。北京姑娘去外企做前台一个月2000,和公司外地姑娘拿这么多,和做公务员的外地姑娘拿这些,生活成本天差地远。不是说有10万个月入2000的外来人口,四环内就有一万处他们能承受的住房。而个体的外来人口的支出,会随着生活成本调整。开始很难理解月入两三千的白领在北京市如何生活,毕竟他们不可能像楼下卖蔬菜水果的大叔那样,炖点猪肉粉条就算开荤,穿特价五块的汗衫就算工作服。一样的月入,白领的幸福起点高得多。后来知道他们原先偶尔用兰蔻改成一直用大宝,早餐不再喝豆浆,住单位附近的搬到五环外,有人在燕郊买了房……突然想起小时候学新概念英语,说起蓝领工资比白领高,但还有人为了能西装革履宁可减薪做白领。
对80后而言,最恐怖的绝不是房价,而是养老。这也不是计生的问题,一个社会的生活资源是有限的,老龄化早晚会到来,为了改变老龄化呼吁多生育,那是饮鸩止渴。等多生出来这部分老了,再这么循环?而福利社会如英国是50多岁的人最幸福,有稳定养老金,二三十岁最痛苦,看不到未来依靠。家底不厚的像希腊,透支做社会福利,后果还不如不做。中国则是取不足以奉有余,竭全民之力供特权阶层挥霍,没有哪个年龄段享受过全民福利,还得共同面对养老难题。房子,真不算此生最纠结的事
kkndme:
正是如此,以后城市的底层吃饭都是问题,政府最喜欢拿房子说事转移矛盾 #card
农村自来水
说起农村建自来水更搞笑,亲眼目睹要不然真不敢相信。
贵州有个村子,以前,自来水是村子集体出钱买的管子,然后全村出劳力从山上接下来(用的山泉水),要是水管坏了,大家再摊钱摊劳动力修。
结果政府不愿意了,说他们修的不规范,政府给重新修,还是从山泉引水下来,政府包给工程队换了一下管子,然后每户给按了水表,安好了以后,要按照2块钱一吨收费,全村都炸了窝了,集体抗议,现在还没有结果。#card
袁盎
丛林社会就是要承认人与人之间的差别,性格决定命运。
我要讲一个奇人,这个人叫袁盎。故事的出处是《史记·袁盎晁错列传》,如果鸡冻同志认为我瞎编,可以自己去看原文。
袁盎同志的神奇是一般人都无法想象的,这个奇人在吴国当相国的时候,他手下的一个小公务员跟老袁同志的爱妾乱搞,经常背着老袁嘿咻嘿咻。老袁知道了这个事就装聋作哑。
有人跟那个小公务员说:坏了,你跟袁领导的二奶私通的事让袁领导知道了,你死定了。
小公务员一听吓坏了,骑了马就跑,公务员这份全世界最令人羡慕的工作也不要了。
小公务员一跑,袁领导就使劲追,小公务员就更拼命跑,袁领导就更拼命追。袁领导的马要好一点,跑的快,终于把小公务员追上了。小公务员只好下马等死。
袁领导急了,对小公务员说:你跑什么呀?我正打算把我的二奶送给你。兄弟如手足,妻子如衣服。大概就是这个意思。
小公务员感激涕零,抱着袁领导的二奶继续嘿咻。
所以说老袁这人最仗义,人缘最好。上下都买他的帐。
老袁也有个把敌人。老袁在皇宫里当小跟班的时候,得罪了汉文帝宠爱的一个太监叫赵谈的,所以特别害怕,怕赵太监哪天找茬把自己给黑了。
老袁征求了侄子的意见,认为自己应该先下手为强,应该当众侮辱一下赵太监,这样如果赵太监再黑自己,就没人信了,别人都以为是公报私仇。老袁的政治手腕还是相当高的。
一天,文帝刘恒跟找太监坐在一辆车子里外出,老袁上前拦住车子,大义凛然的说:能够跟天子共乘一车的,都是天下豪杰,天子怎么能跟一个没小鸡鸡的人坐一辆车呢?
赵太监当场就气哭了,还不能说什么。以后赵太监要黑老袁,也没那么容易了,因为大家都知道老袁义正言辞,充满正义的得罪了赵太监,如果赵太监再说老袁坏话,就是公报私仇。
老袁的人缘是公认的好,但是在朝里有一个最大的敌人,就是大名鼎鼎的晁错。
晁错这个人学的是商鞅之术,法家的代表人物。为人冷酷,不讲人情,人缘特别差。老袁和晁错关系不好,可能跟两个人的性格很有关系。
晁错跟贾谊很有一拼,特别喜欢喷,口才也特别好,跟贾谊同志喷的内容也差不多,一会儿说打匈奴其实很简单啦,一会儿说必须削藩啦。刘恒听晁错喷的很有水平,很欣赏,但是刘恒不是傻子。
打匈奴?那得是国力强大以后的事,现在必须让老百姓修养生息。
削藩?我也想削藩,但是总得有合适时机才行啊,现在削藩不是逼人造反吗?
刘恒对晁错这种人的态度就是,你建议你的,我听听就可以了,不能当真。
晁错同志懂得要想发达,必须选择一个有前途的职业,所以凭着他气死保险推销员的口才,当上太子的老师。这个太子就是汉景帝刘启。
晁错的时代终于来了,原因是刘恒挂掉了。
刘启生下来就是锦衣玉食,可没他老子那两下子,也不怎么懂帝王之术,晁错说什么就是什么。
晁错于是抖起来了,不知姓什么了,仗着是皇帝的老师,飞扬跋扈,人缘极差。晁老师最爱追求政绩,立刻提出削藩。
削藩的结果就是吴楚七国反了。
这个故事跟明代朱允文同志的削藩如出一辙。明朝朱允文同志削藩的结果就是朱棣反了,当了皇帝。朱允文被迫流浪,泡吉普赛美眉去了。
吴王不是朱棣,性格有点象袁绍,生性多疑,手下有人才不会用,所以没能成大事,被周亚夫跟干掉了。如果吴王能有朱棣的本事,汉朝的历史就会改写。
吴王一反,老袁就着急了。老袁给吴国当过相国,吴王造了反,晁错必然要借机宰了老袁,老袁觉得自己冤枉啊,吴王造反不是你晁错逼的吗?
晁错果然趁机对老袁打击报复,安排了两个手下去弹劾老袁。但是晁错的人缘实在太差了,老袁的人缘实在太好了,那两个手下竟然不同意弹劾老袁。而且还劝晁错,大意是:现在七国兵马造反了,形式很危急,我们还搞内斗就不好了。老袁这个人是不可能参与谋反的。
晁错也着急叛乱的事,就把老袁放一边了。政治斗争,不是你死就是我活。
晁错错了,赔进了自己的老命。
窦婴同学也曾经在吴国当过相国,立刻跟老袁站在了一条战线上,准备给晁错来个致命一击。
晁错这个人的死,完全是他自己性格造成的,对人苛刻,政治上又是白痴。吴楚七国打着“诛晁错,清君侧”的名义造反,皇帝问晁错应该怎么办?
晁错的白痴精神充分发挥了出来,“陛下您御驾亲征,臣留守长安,做好看家的工作。”
皇帝估计当时心里要多愤怒有多愤怒。你自己惹的祸,你一个当臣子的在家躲起来,让我当天子的上去当炮灰,你是何居心? 不过刘启涵养好,没说出来。
这时候老袁跑了进来,说有平乱之计,要单独跟皇帝说。刘启很不客气的就把晁老师请了出去。
老袁立刻献计,既然反叛打着清君侧的名义,就先把晁老师宰了,叛军就出师无名了,就得不到老百姓的响应,事情就好办了。
刘启一听挺高兴,正恨晁老师让自己当炮灰的事呢,立刻同意,腰斩晁错。
晁错的下场要比贾谊惨多了。
不过老袁的下场也并不好。皇帝的老妈想让皇帝的弟弟梁王在刘启驾崩后继承皇帝这份工作,但是老袁不同意,坚决表示反对,得罪了梁王。
梁王不是一般的高级公务员,最喜欢搞黑社会,找了杀手把老袁干掉了。
这个故事又告诉我们,即使人缘再好,在政治斗争中活下来也是不容易的。
welldayzwb:
最好把历史故事表达的直白的意思讲出来,不排除观众里像我这么愚钝的人不少
kkndme:
我说的不是袁盎也不是晁错,说的是削藩,皇帝削藩怎么样?看看朱允文的下场,晁错几乎独揽了大权,削藩的下场是什么?腰斩。清查空置率,政府不参与一级开发,不是扯淡吗?#card
在中国,普通人手上闲钱不多的人被剥削
抽着雪茄喝着绿茶:
兰州,我近来盛干人民币的贬值力度之强烈
现在手上还有十万的盈余
做什么好呢
咬紧牙关供一套房?买黄金?还是买车呢?
总之不能空放着,
这样通货膨胀下去,汽车的价格也会涨吗?
kkndme:
买车是消费,不是投资,如果追求享受,可以买车,但不能保值增值。汽车属于工业品,通过扩大生产规模可以使边际成本下降,所以汽车会因为档次的不同有涨有跌。
黄金可以适当配置,但由于黄金的定价权不在国内,所以买黄金有一定的风险。
十几万买房子估计不够首付,除非特别小的城市。但小城市的房产变现起来比较麻烦。
至于古玩字画茅台酒之类的,真假难辨,不是专家很难参与投资,且一般人变现还是很困难的。
所以资金越小,资金实现保值增值越困难。我国实行的高通胀低利率政策,是对手中闲钱不多的普通群众赤裸裸的剥削。而手中闲钱较多的中产阶层,相对好一点,可以投资住宅商铺进行保值增值。#card
人的前程有的时候不掌握在自己手里
某城市从外省调来个姓q的一把手。该一把手一上任就把该市原来的骨干公务员全部晾到一边,一概不用,名义上对外宣称的是:领导干部年轻化。提拔了一批没有工作经验刚毕业的博士生当处级干部,大多数30岁还不到。这些人一点工作经验没有,以至于外界都很惊讶,甚至惊动了日本友人。
该一把手正是要用这些毫无工作经验的白纸,第一:人是自己一手提拔的,他能不感激涕零吗?第二:这些人啥也不懂,自己想怎么干就怎么干,这些人听话就行。不这样做,怎么能一手遮天呢?
一批期望往上爬的老公务员就这样牺牲掉了,而一批新丁就此崛起。人生的前程往往不掌握在自己手里。#card
西安与重庆
ttan12345:
用了一整天的时间拜读了楼主的精彩文章,很是佩服!
印象最深刻的就是北周宇文式和苏的关于贪官的对答,古人真有高人啊!
感觉楼主知识面相当的宽广,尤其对世界历史比较精通,许多观点非常符合世界发展的规律
关于房产的问题,我也一直认为,最终不是我们小老百姓可以玩的东子,所以能买就
尽早买。看了楼主不止一次给大家推荐去投资西安和重庆的地产,楼主问什么看好西安
和重庆这两个地方,现在各个省会城市哪个不是大兴土木呢?为何西安和重庆会进入你
的法眼?
kkndme:
重庆我就不多说,论述的比较多了,发展重庆是国家战略性的,这是政治任务。
西安是西北地区唯一的大城市(乌市比较特殊,不讨论乌市),教育资源丰富,且房价基数较低,所以说后续发展潜力很大,未来该城市的发展一定会纳入中央的视野 #card
谢国中「空置率」
林语边的鸽子:
谢国中:”一是加息预期;二是政府对房地产的政策调控力度不改;三是市场对人民币升值的预期减弱;四是参考了实际的供应量,“到2012年,房地产的空置率会非常高,全中国13亿老百姓要有的房子都有了。”
谢国忠预测,“接下来可能会看到交易量一直在增长,而房价却不死不活地拖几年,房地产没有第二场戏了
请问楼主对谢国中的说法怎么看?
谢谢
kkndme:
谢是油价和中国房地产的长期唱空者,从04年开始唱空中国房产。谢的有些话还是很有道理的,但有些预测就另有目的了,毕竟屁股决定脑袋。
今年谢一直呼吁的是加息,兼带唱空房地产,唱空房地产的主要依据是空置率。
谢自己也说中国的房地产最大受益的是政府,但却用空置率给出了一个下跌的结论。
人民币升值,呼吁加息,唱空房地产,摩根史丹利的喉舌作用显而易见的 #card
打工不如有一技之长的小老板
中年不惑吗:
现在他们已经比一般的小白领强了
人力成本只会越来越高
现在去读个技校,当个技工
肯定比一般大学出来强多了
还有一个问题:
一般企业的工资10年没有变
10年前某个职位是5000,
10年后这个职位也是5000;
而在10年间,民工工资可能从1000涨到了3000,
房价更是涨了10倍;
菜价生活用品也翻了数倍
高房价问题其实就是分配问题
如果某个从事的职位10年前和10年后是一样的
那也就相当于这个职位的薪水降了相当多
kkndme:
进不了体制内的,无论是不是大学毕业,凡是有头脑的、懂做生意的,会一技之长的,只要不懒,活的肯定比无特长一般在公司打工的小白领强。
古代也是这样的,街面上卖爆肚的肯定比大户人家厨房里负责切葱的日子过的稳当。卖爆肚的小本生意很累很辛苦,但是有个手艺就不会饿肚子。大户人家切葱的上班期间日子过的比较轻松,甚至收入比卖爆肚的还强点,在大户人家也体面些。但一旦大户人家不要切葱的了,裁员了,这个切葱的出来还真没办法养活自己。
大学文凭顶多算个秀才资格,有这个资格才有机会举士,但是举不了士的,就必须学点技术,否则收入远远赶不上瓦工、电工。
过去的穷秀才,饭都吃不饱,但是社会地位却不差,一旦中了恩科,就是宰相根苗。现在有点不同,进不了体制内,又没点技术,那肯定沦为社会的最底层,不要说买房子了,能不能解决吃饭问题都不一定。#card
讲故事含沙射影ZG之房子不属于市场经济
不说历史了,讲个故事吧。这个故事纯属虚构,如有雷同,纯属巧合。讲故事麽,就不要和谐了。
传说王安石变法失败,后人小王跑到了海外,发现了大西洲。大西洲正处于混乱阶段,军阀割据,外族入侵。小王是个政治军事天才,煽动农民起义,统一了大西洲政权,建立了大西国。
小王继承了王安石变法的理想,建立了一个中央高度集权,百姓与百姓之间完全消灭差别的理想国家。农场、工厂、商场全部由国家统一经营,老百姓只需要在国家的农场、工厂、商场里快乐打工就行了。老百姓穿一样的,吃一样的,连结婚都是国家给安排。
大西国里有的知识分子认为这样治理国家太机器化了,有违人性。小王同志对这些知识分子很生气。
遥远的东方,有一个白鹿洞书院,书院的院长是个伟大的导师,这个人叫朱熹,此人提出了存天理、灭人欲的理论,给了小王同志治理国家理论上的支持。
于是小王同志大搞禁欲主义,凡是学习过陆九渊、王阳明心学理论的都抓起来改造。
不久,大西国经营的农场、工厂、商场就出了问题。效率特别低,老百姓出工不出力,胡干蛮干的比比皆是,后来出现了大饥荒,饿死了不少人。小王同志干不下去,被人赶走了。
新领导上台后,先把农场划分给农民,提高农民的积极性,先解决粮食问题。但是工厂、商场就比较不好办。
新领导认为,工厂、商场效益低,赔钱是因为负担太重了,城市里的老百姓生老病死都是由国家的工厂、商场负责,国家哪里管的起呢?
于是新领导就提出给国家的企业减负,给点优惠政策,拿出胡萝卜,让胆子大愿意自己单干的同志们主动离开国家企业。对于很多死活不肯走的同志,新领导强令这些人卷铺盖,国家不再负担这些人的生老病死了。大家自己解决吧,国家不管了。
新领导把还留在国家企业的自己人,定义为内部人员。离开国家企业的,就是外人,定义为社会闲杂人等。
社会闲杂人等,有人欢喜有人忧。有人利用内部人员的关系,大把赚钱,有人跑去给外国人当洋买办赚的也不少,还有的知识分子凭着有点文化,给人打工生活的也不错,反正这些人都挺高兴,比在内部受穷强。当然也有没本事的,就比较惨,生活的比较困难。
新领导看见内部都是自己人了,闲杂人等都清理掉了,于是着手内部改革,凡是稀缺的,与老百姓生产生活密切相关的行业,都由内部来经营,不需要动脑子搞创新,只要定个价,老百姓就必须得接受。
而需要创新动脑子的产业,不具备稀缺性必须充分竞争的产业,不是跟老百姓生产生活密切相关的产业都交给社会闲杂人等去自由竞争。
相当于把肉都留给了内部自己,把骨头扔给了外部闲杂人员。
这样做还有个好处:新领导喜欢内部自己人直接跟外国人做生意,但是只要跟外国人做生意就赔钱,赔的还不是一点半点。赔的钱从哪里补呢?
只要通过内部自己人经营的企业,抬高定价,将赔掉的钱转嫁给社会闲杂人等就可以了。
于是,当初离开内部的社会闲杂人等发现,钱也难赚了,生活成本也越来越高了,日子过得变得越来越艰难了。
这时有个傻空跳出来说:我就不信了,市场经济没有只涨不跌的商品。房价肯定会跌。
有个明白人告诉他:市场经济是分品种的。外部社会闲杂人等经营的电脑、电视是市场经济。但是内部人经营的石油、房地产不是市场经济。不能拿市场经济来解释。
这个傻空不信,本来在大西国能买房的,结果一直没买,后来买不起了,只好一直租房住。但是房租老涨价,吃饭越来越困难,一年难得吃两回肉。#card
保钓事件之死要面子活受罪
保钓事件,既定对策就是争取更多小国穷国的舆论支持,减免他国债务,加大对外经济援助。钱的来源,要靠底层国民勒紧裤腰带。
自古以来,泱泱大国,威仪四海,对外“恩”显示国力强大,对内“威”显示权力强大,恩威并施,千古国策。
朱棣的恩泽海外,死要面子,是做的比较极致的。结果是国库空虚,人民吃饭一下成了问题。所以才有后来坚定的禁海。
如果开通海外贸易,不是为了皇帝的面子,而是为了充实国库和老百姓的腰包,明代的官僚就不会坚持禁海,中国的历史就会改写。
郑和下西洋,反而堵塞了中国通向大海的道路。
tjOOSAN
我只能说,楼主不懂政治,就触及了。钓鱼岛就算所有您所谓的“小国”都支持。也没用啊。神经病 就是神经病
kkndme
这个做法不新鲜,从周恩来时期,我们的外交政策就是拉拢第三世界国家的选票,远到非洲拉美,近到越南缅甸柬埔寨,支援铁路基建,捐钱捐物,自认第三世界国家的带头人。但是第三世界国家基本有奶就是娘。比如拉美的苏里南,我国刚捐了钱物,米国给了点好处,马上又投向米国。
tjOOSAN
建议您看看nhk的中国力量。真实偷拍的中国在非洲都做了什么。
1、资源。铁矿石 2、建立国家通信网 3、人力。
呵呵。援助是拉拢,但是有条件的。
越南最新的高铁,由日本公司建设。中国从来没援建过越南。
唉。。。。你把中国当傻子了。
kkndme
周时代,越南的生产工具、军火、粮食,都是中国无偿援助。无知不可怕,无知还满嘴喷粪最可怕
tjOOSAN
呵呵!
援建越南??!哪了?给我证据?!?
关于非洲,我给你们穿了视频!自己看就知道了
中年不惑吗
还非洲的力量
当年红太阳把大米鸡蛋东方红拖拉机运到阿尔及利亚
换来的是“中国人民是我们最好的朋友”和对中国各种口头的声援
这和kkndme兄说的难道不一致吗
现在不给钱给物了
你还能听到“中国人民是我们最好的朋友”的说法吗?
拉拢非洲小兄弟,是具有政治意义的
你英国是一票,人家再穷的小国也是一票
kkndme
你理解力看来真有问题,你哪只眼睛看到争取小国穷国的舆论支持里面,包括越南。
这个事是温总定的调子,挂在搜狐首页
tjOOSAN
中年!kk!!
你们这两个同学啊!一看就跟成天上网的学生,没两样。争来争去。
哎呀,非要你赢他输。
唉。。。你说的怎么就对呢??!证据!!明白吗??
光你自己打嘴炮。没用啊!
呵呵 我得出去玩会了
你们继续网络吧!~~ 两个宅男
kkndme
tjOOSAN你去图书馆查查当年的报纸,什么都清楚了。
典型的愚民政策教育出来的傻蛋。#card

































































































































































 {:height 198, :width 509}
{:height 198, :width 509}
 {:height 115, :width 608}
{:height 115, :width 608}





















































 {:height 810, :width 840}
{:height 810, :width 840}


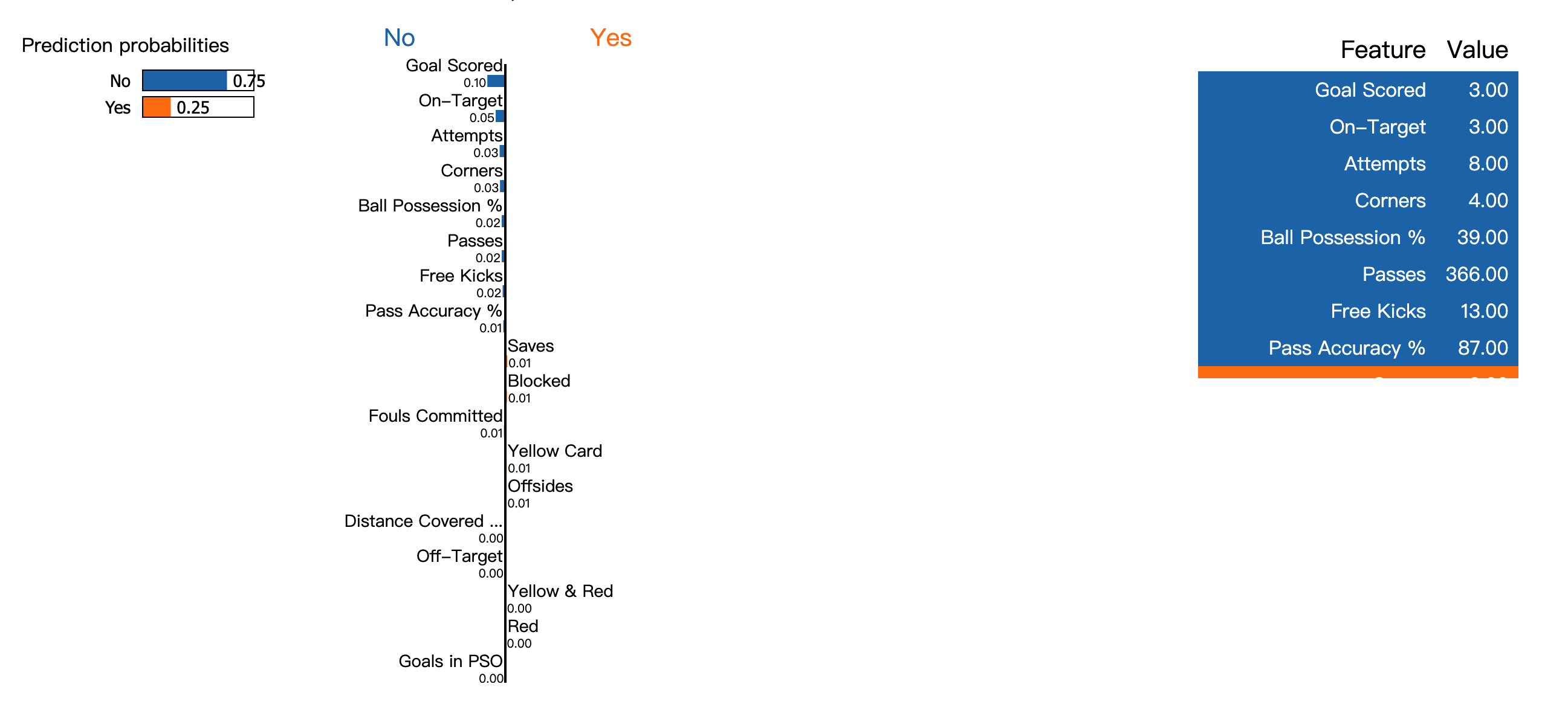
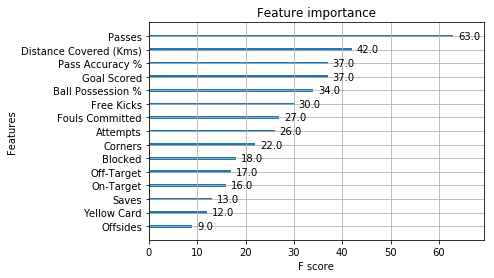

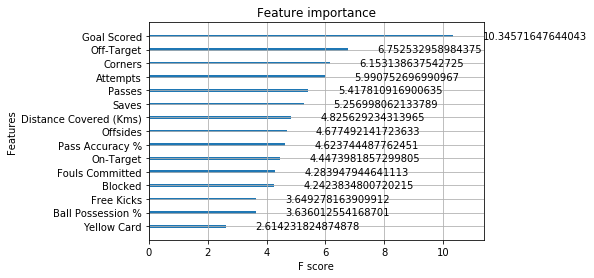
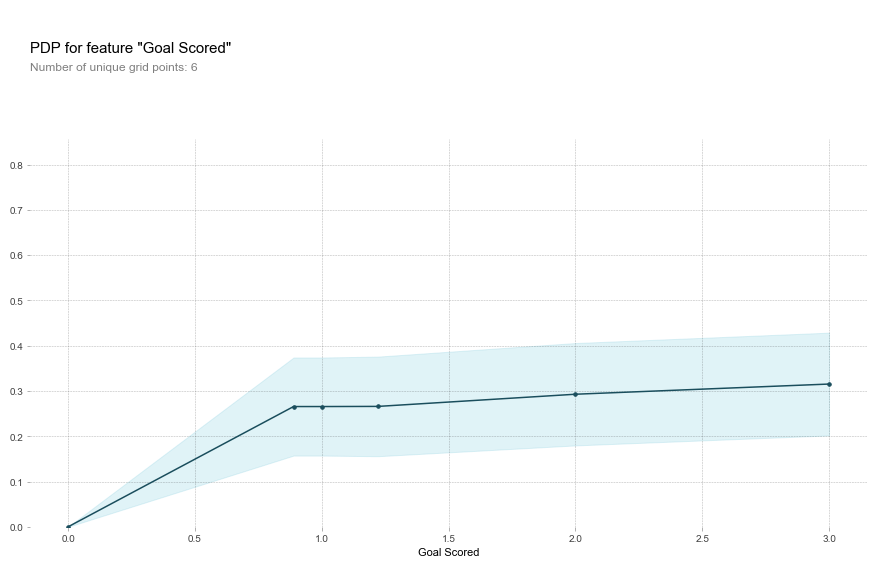

 #card
#card #card
#card















 {:height 648, :width 1229}
{:height 648, :width 1229}








 #card
#card #card
#card








































 {:height 215, :width 338}
{:height 215, :width 338}































 {:height 503, :width 717}
{:height 503, :width 717}
















 {:height 223, :width 448}
{:height 223, :width 448} {:height 115, :width 667}
{:height 115, :width 667}









































































































 {:height 415, :width 716}
{:height 415, :width 716}