EGES
[[向量化召回统一建模框架]]
- 如何定义正样本
- 之前介绍的Item2Vec以及Airbnb I2I召回都认为只有被同一个用户在同一个Session内交互过的两个物料才有相似性,才可能成为正样本。EGES认为这个限制太狭隘了。#card
比如一个用户点击过物料A和物料B,另一个用户点击过物料B和物料C。
Item2Vec认为只有AB和BC才存在相似性,但是AC难道就不相似了吗?
EGES应该把这种跨用户、跨Session的相似性考虑进去,这样能够提高模型的扩展性,也能够给那些冷门物料更多的训练机会。
- 之前介绍的Item2Vec以及Airbnb I2I召回都认为只有被同一个用户在同一个Session内交互过的两个物料才有相似性,才可能成为正样本。EGES认为这个限制太狭隘了。#card
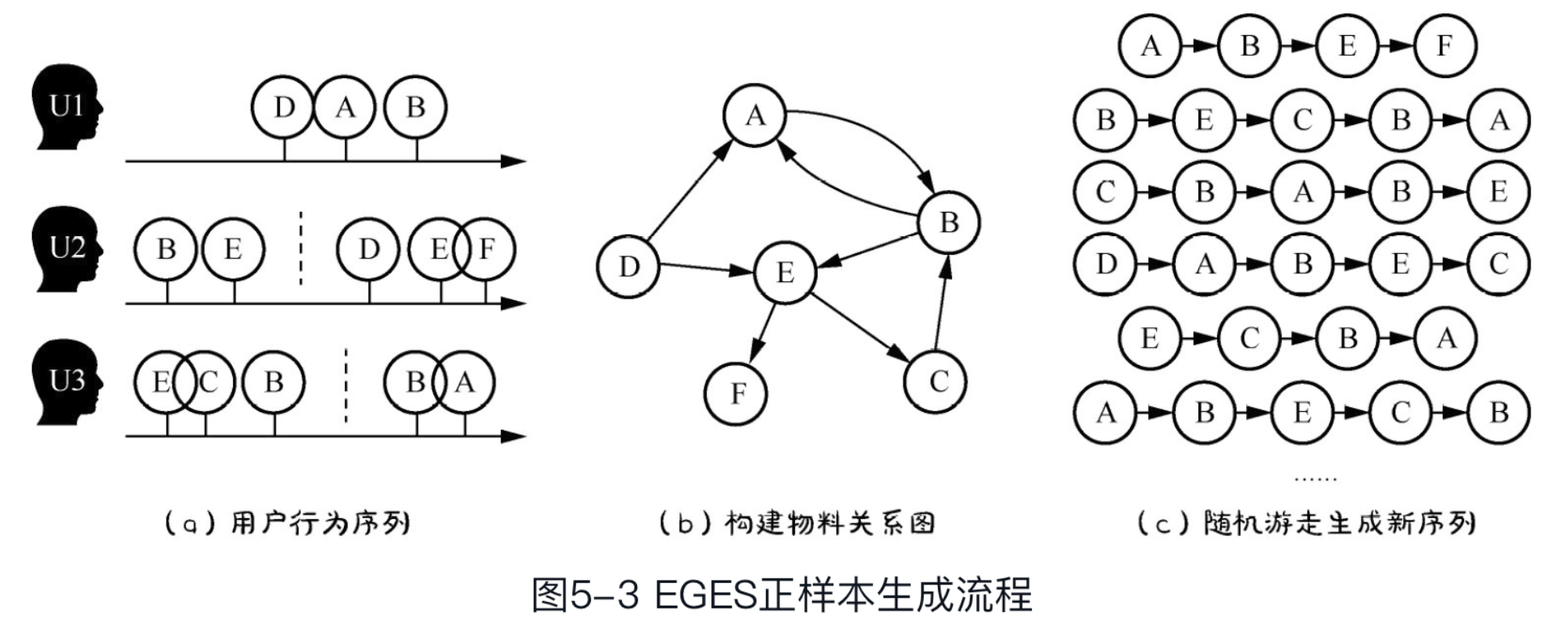
+ (1)根据用户行为序列(如图5-3(a)所示)建立物料关系图(如图5-3(b)所示)。#card
+ 图上的每一个节点代表一个物料,每一条边代表两个物料被顺序交互过。
+ 比如,图5-3(a)中的用户U1先点击过物料D,再点击过物料A,那么在图5-3(b)上就有一条边由D指向 A。
+ 第 $i$ 、 $j$ 两个节点之间的边上的权重 $M_{i j}$ ,等于数据集中"先点击物料腯点击物料 $j$"的次数。
+ (2)沿图5-3(b)中的边随机游走,生成一批新的序列(如图5-3(c)所示)。#card
+ 随机游走过程中,由节点倒节点的转移概率 $P\left(v_j \mid v_i\right)=\frac{M_{i j}}{\sum_{j \in N_{+}\left(v_i\right)} M_{i j}}, ~ M_{i j}$ 是由指向那条边上的权重
+ ,$N_{+}\left(v_i\right)$ 是由第 $i$ 个节点出发的邻居节点的集合。
+ (3)在这些随机游走生成的新序列(如图5-3(c)所示)上,再套用Word2Vec的方法, 定义滑窗,窗口内的两个物料是 **相似** 的,成为正样本。
+
- 如何 embedding #card
- 推荐系统与NLP的区别就在于,通常NLP中除了单词本身,就没有多少其他特征可利用了;但是在推荐系统中,除了ID,每个物料还有丰富的属性信息(也称为Side Information),比如商品的类别、品牌、商铺等。这些信息在照搬Word2Vec的Item2Vec中没有被利用上,太可惜了。另外,加入这些额外的物料属性当特征,还有利于新物料的冷启。对于ID从未在训练集中出现过的新物料,Item2Vec无法给出其Embedding;但是新物料的属性大多在训练集中出现过,并且它们的Embedding已经被训练好了,EGES可以拿这些属性的Embedding合成新物料的Embedding,解一时之需。

