MoCo
Summary
- 填补 CV 领域有监督学习和无监督学习的差距
Abstract
dictionary look-up
- 提出基于队列+动量对比用于无监督的表征学习。
Introduction
创新点:用队列表示字典
什么样的字典才适合对比学习?
(i) large
从连续高维空间做更多的采样,字典 key 越多,表示的信息越丰富
字典小,key 少,模型泛化能力弱
(ii) consistent
字典中的 key 应该用相同或相似的编码器生成
如果key是使用不同编码器得到的,查询时可能找到与 query 使用相同或相似编码器生成的key,而不是语义上相似的 key
无监督在 CV 领域不成功的原因
原始信号空间的不同
NLP 原始信号是离散的,词、词根、词缀,容易构建 tokenized dictionaries 做无监督学习
tokenized: 把一个词对应成某一个特征
Why tokenized dictionaries 有助于无监督学习?
把字典的 key 认为是一个类别,有类似标签的信息帮助学习
NLP 无监督学习很容易建模,建好的模型也好优化
CV 原始信号是连续的、高维的,不像单词具有浓缩好的、简洁的语义信息,不适合构建一个字典
如果没有字典,无监督学习很难建模
无监督学习主要的两个部分:
pretext tasks 代理任务
学习更好的特征表示
常见代理任务
denoising auto-encoders 重建整张图
context auto-encoders 重建某个 patch
cross-channel auto-encoders (colorization) 给图片上色当自监督信号
pseudo-labels 图片生成伪标签
exemplar image 给同一张图片做不同的数据增广,它们都属于同一个类。
patch ordering 九宫格方法:打乱了以后预测 patch 的顺序, or 随机选一个 patch 预测方位 eight positions
利用视频的顺序做 tracking
做聚类的方法 clustering features
loss functions
衡量模型预测结果和固定目标的差异
L1 or L2 Loss
- Auto-encoder
判别式网络
eight position
- 图片 9 等分,判断选出的图片位于中间图片的什么方向。
对比学习损失:目标不固定,训练过程中不断改变
对抗学习损失:衡量两个概率分布之间的差异
Method
- 代理任务 instance discrimination 个体判别
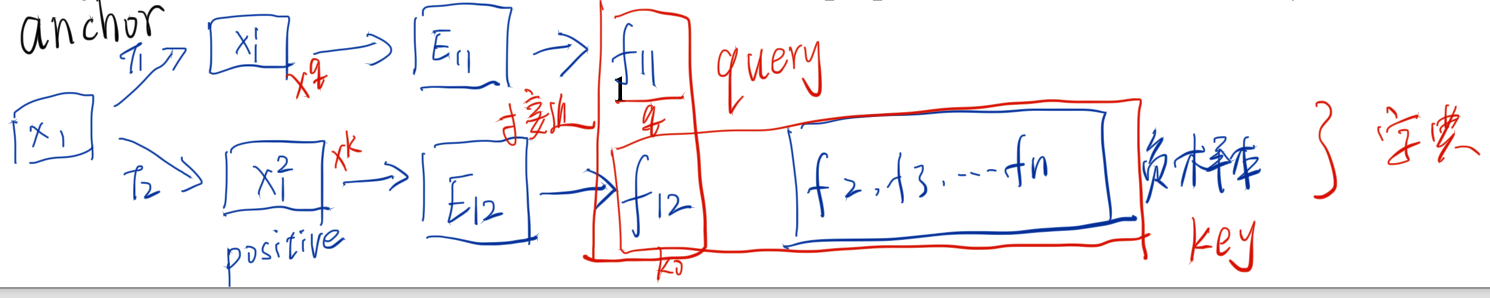
+ 一张图片 $$x_{i}$$ 经过翻转+裁剪等方法得到 $$x_{i1}$$ 和 $$x_{i2}$$,这两张图片做为正样本,其他图片做为负样本。
+ $$x_{i1}$$ 是 anchor
+ $$x_{i2}$$ 是 positive
+ 编码器 E11 和 E12 可以相同,也可以不同。
+ 对比学习怎么做?
+ f11 和 f12 接近,和其他样本远离
+ matching key and dissimilar to others
+ Learning is formulated as minimizing a contrastive loss
+ f11 当成是 query,在字典中查询接近的 key
如何构建大 + 一致的字典
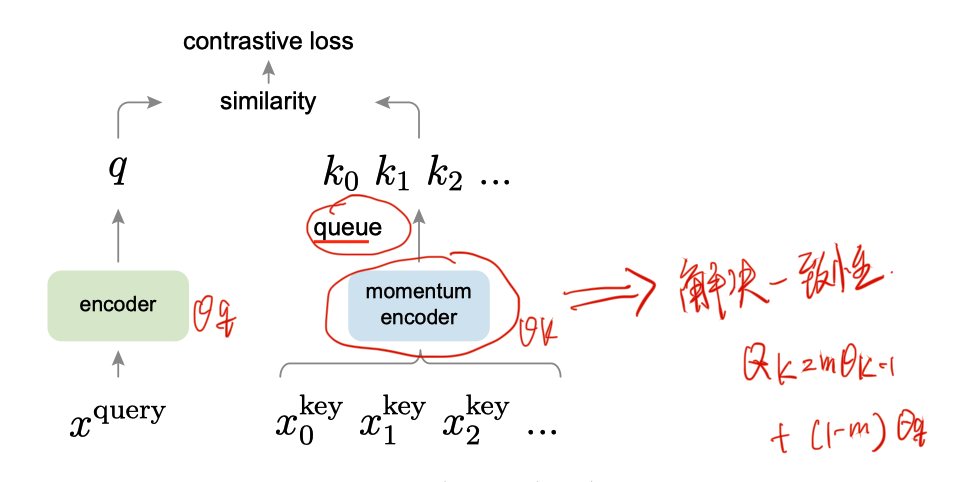
基于队列的字典
摆脱 batch size 的限制
用队列大小限制字典大小
基于动量的编码器
$$\theta_{\mathrm{k}} \leftarrow m \theta_{\mathrm{k}}+(1-m) \theta_{\mathrm{q}}$$
momentum encoder 由当前的编码器初始化得到
动量 m=0.999 比较大是,动量编码器更新缓慢。尽可能保证队列的 key 由相似的编码器生成
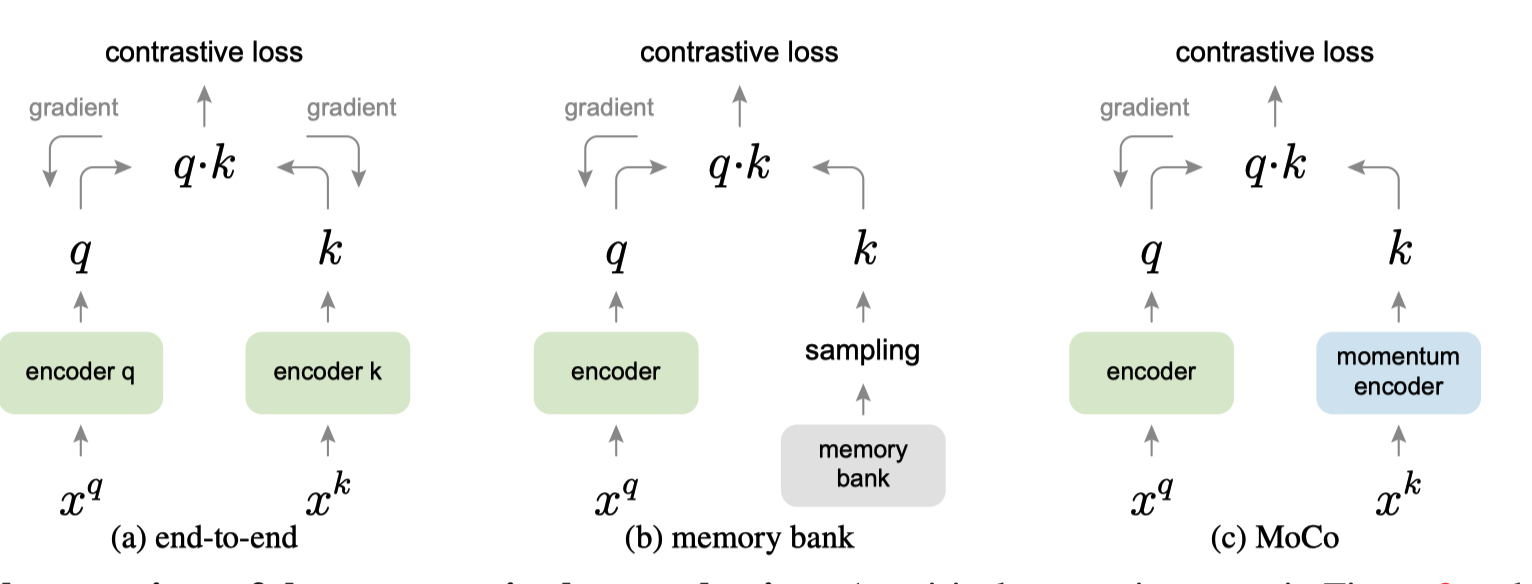
和之前方法对比
end-to-end 牺牲大
- 负样本大小等于 batch size 大小
memory-bank 牺牲一致性
- 采样得到负样本
moco
encoder 基于梯度更新
momentum encoder 基于 encoder 进行动量更新
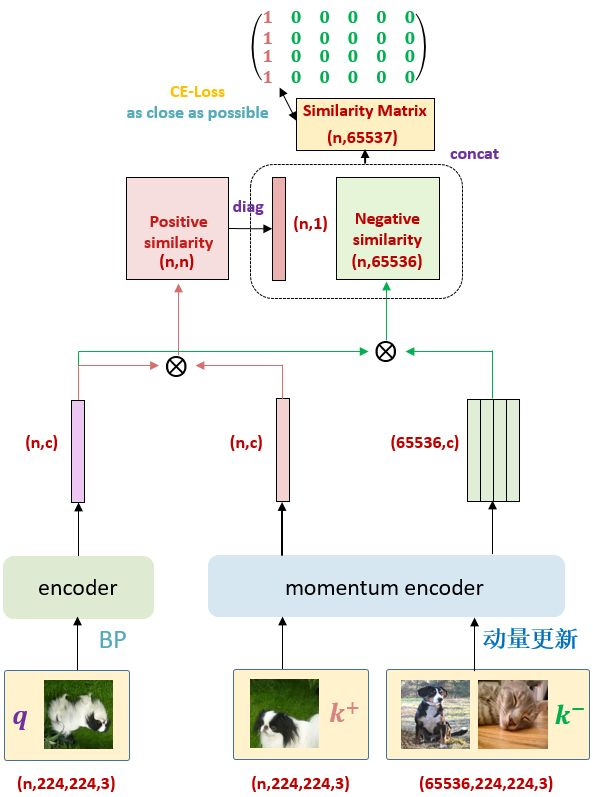
目标函数 [[InfoNCE]]
$$\mathcal{L}{q}=-\log \frac{\exp \left(q \cdot k{+} / \tau\right)}{\sum_{i=0}^{K} \exp \left(q \cdot k_{i} / \tau\right)}$$
计算 q 和 k 的点积判断两个样本之间的相似度
$$\tau$$ 控制分布图形,越大越关注困难样本
同一张图片的增强版本分别做为两个编码器的输入
Experiments
7 个检测 + 分割任务
linear protocol
预训练模型,应用时只改变最后的全连接层。
backbone 做为特征提取器
对比预训练的效果好不好
Conclusion
1000 倍数据增加,moco 性能提升不高
尝试NLP中其他代理任务 masked auto-encoding
[[Masked-Language Modeling]]
见 [[Masked Autoencoders Are Scalable Vision Learners]]
总结
- 去构造一个大的字典,从而让正负样本能够更有效地去对比,提供一个稳定的自监督信号,最后去训练这个模型