S-Learner
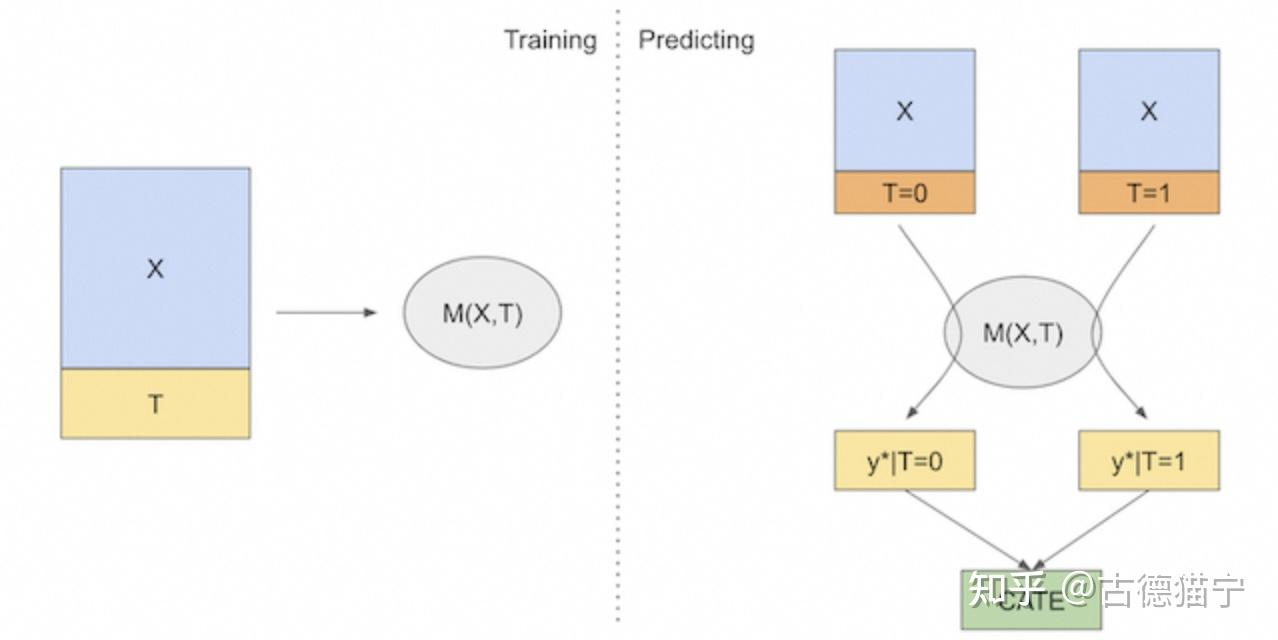
S 的由来 :-> 将干预变量 $T$ 和背景变量 $X$ 一起作为特征输入到单个模型 $M$ (Single,S 的由来)学习 $M(X,T) = E(Y|T,X)$
把用户是否干预作为特征加入到模型构建中
预测阶段如何得到反事实结果? #card
- 在预测时通过修改干预变量 $T$ 的值预测获得反事实结果,
- 最终的 CATE 估计为 $\hat{\tau}(x)_i=M_s\left(X_i, T=1\right)-M_s\left(X_i, T=0\right)$
优点:#card
1)干预变量作为特征可以适用于多值干预。
2)干预 / 控制组样本共同训练单个模型的参数,有助于缓解干预组样本稀疏时的欠拟合问题,提高模型精度
可以直接使用现有分类算法
减少双模型误差累积
缺点:#card
- 干预变量作为输入特征可能会被淹没在其他众多特征中,如果干预变量与其他特征存在相关性时会更严重。间接计算增量,无法根据增量对模型进行优化
S-Learner 中缓解特征被忽视的方法 #card
构造更强的交叉特征,
直连模型输出层干预打分,
作为裁判特征输出权重