Spark 内存模块
运行在 JVM 体系上,内存模型基于 Java 虚拟机
堆、栈、静态代码块和全局空间
Executor
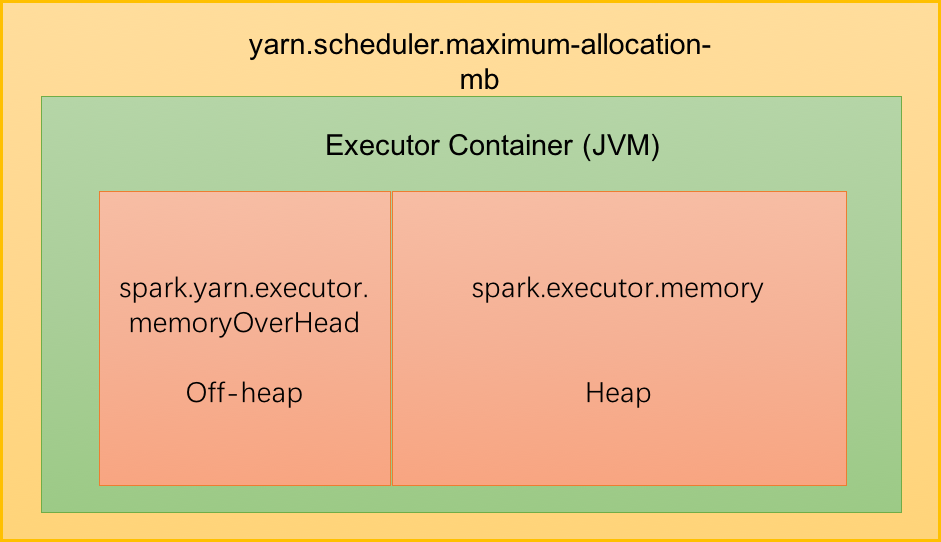
- 申请内存包括下面两部分
M1+M2
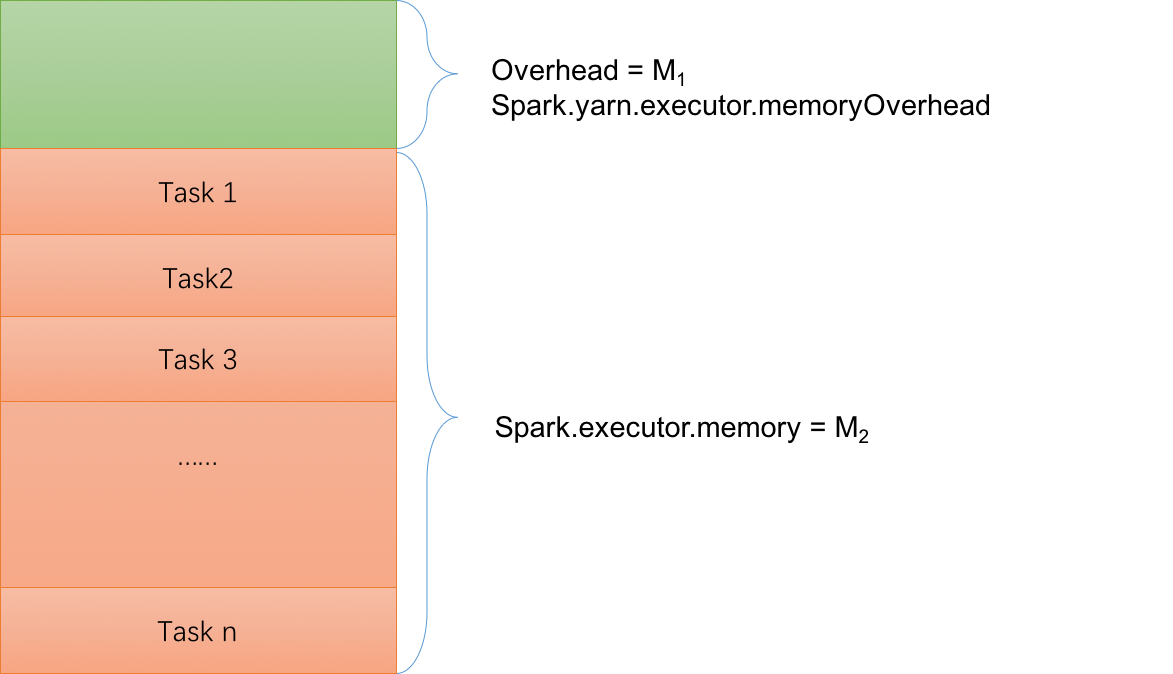
+ OnHeap 堆内内存 spark.executor.memory
+ OffHeap 堆外内存 spark.yarn.executor.memoryOverhead
+ spark.memory.offHeap.size
Task Memory Manager
- E 的线程共享 JVM 资源,没有强隔离
内存划分
Storage:RDD缓存、Broadcast 数据空间
Execution:Shuffle 过程使用的内存
第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;
- JVM
第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;
- 通过 spark.shuffle.memoryFraction 控制大小
第三块是让RDD持久化时使用,默认占Executor总内存的60%。
persisit() 或 cache()
通过 spark.storage.memoryFraction 控制大小
超过限制,旧分区会被移除内存
Other:用户定义的数据结构、Spark 内部元数据