8d - the building blocks - block types
去年学习这门做的部分笔记,现在分享出来。
笔记格式有些问题,持续整理中。
- 大量内容参考 mbadry1/CS231n-2017-Summary
Table of contents
- Table of contents
- Course Info
- 01. Introduction to CNN for visual recognition
- 02. Image classification
- 03. Loss function and optimization
- 04. Introduction to Neural network
- 05. Convolutional neural networks (CNNs)
- 06. Training neural networks I
- 07. Training neural networks II
- 09. CNN architectures
- Reference
Course Info
- 主页: http://cs231n.stanford.edu/
- 视频:斯坦福深度学习课程CS231N 2017中文字幕版+全部作业参考_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
- 大纲:Syllabus | CS 231N
- 课件:Index of /slides/2017
- 笔记:贺完结!CS231n官方笔记授权翻译总集篇发布
- 作业仓库:MachineLearning/CS231n at master · xiang578/MachineLearning
- 总课时: 16
01. Introduction to CNN for visual recognition
- 视觉地出现促进了物种竞争。
- ImageNet 是由李飞飞维护的一个大型图像数据集。
- 自从 2012 年 CNN 出现之后,图像分类的错误率大幅度下降。 神经网络的深度也从 7 层增加到 2015 年的 152 层。截止到目前,机器分类准确率已经超过人类,所以 ImageNet 也不再举办相关比赛。
- CNN 在 1998 年就被提出,但是这几年才流行开来。主要原因有:1) 硬件发展,并行计算速度提到 2)大规模带标签的数据集。
- Gola: Understand how to write from scratch, debug and train convolutional neural networks.
02. Image classification
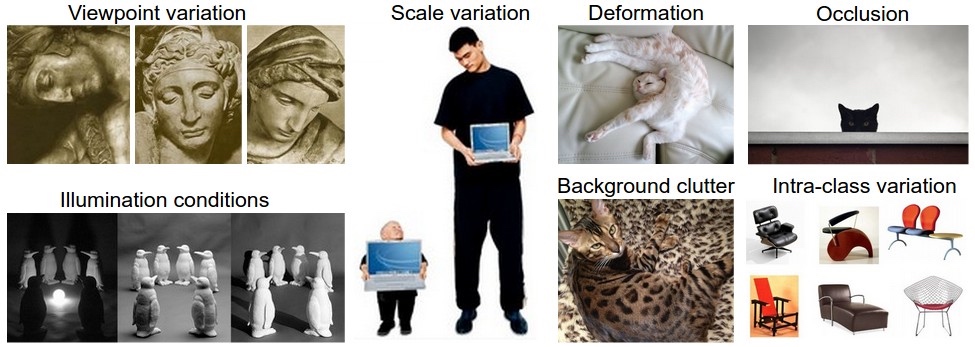
- 图像由一大堆没有规律的数字组成,无法直观的进行分类,所以存在语义鸿沟。分类的挑战有:视角变化、大小变化、形变、遮挡、光照条件、背景干扰、类内差异。
- Data-Driven Approach
- Collect a dataset of images and labels
- Use Machine Learning to train a classifier
- Evaluate the classifier on new images
- 图像分类流程:输入、学习、评估
- 图像分类数据集:CIFAR-10,这个数据集包含了60000张32X32的小图像。每张图像都有10种分类标签中的一种。这60000张图像被分为包含50000张图像的训练集和包含10000张图像的测试集。
- 一种直观的图像分类算法:K-nearest neighbor(knn)
- 为每一张需要预测的图片找到距离最近的 k 张训练集中的图片,然后选着在这 k 张图片中出现次数最多的标签做为预测图片的标签(多数表决)。
- 训练过程:记录所有的数据和标签 ${O(1)}$
- 预测过程:预测给定图片的标签 ${O(n)}$
- Hyperparameters:k and the distance Metric
- Distance Metric
- L1 distance(Manhattan Distance)
- L2 distance(Euclidean Distance)
- knn 缺点
- Very slow at test time
- Distance metrics on pixels are not informative
- 反例:下面四张图片的 L2 距离相同
- Hyperparameters: choices about the algorithm that we set ranther than learn
- 留一法 Setting Hyperparameters by Cross-validation:
- 将数据划分为 f 个集合以及一个 test 集合,数据划分中药保证数据集的分布一致。
- 给定超参数,利用 f-1 个集合对算法进行训练,在剩下的一个集合中测试训练效果,重复这一个过程,直到所有的集合都当过测试集。
- 选择在训练集中平均表现最好的超参数。
- Linear classification:
Y = wX + b- b 为 bias,调节模型对结果的偏好
- 通过最小化损失函数来,来确定 w 和 b 的值。
- Linear SVM: classifier is an option for solving the image classification problem, but the curse of dimensions makes it stop improving at some point. @todo
- Logistics Regression: 无法解决非线性的图像数据

03. Loss function and optimization
- 通过 Loss function 评估参数质量
- 比如 $$L=\frac{1}{N}\sum_iL_i\left(f\left(x_i,W\right),y_i\right)$$
- Multiclass SVM loss 多分类支持向量机损失函数
- $$L_i=\sum_{j \neq y_j}\max\left(0,s_j-s_{y_i}+1\right)$$
- 这种损失函数被称为合页损失 Hinge loss
- SVM 的损失函数要求正确类别的分类分数要比其他类别的高出一个边界值。
- L2-SVM 中使用平方折叶损失函数$$\max(0,-)^2$$能更强烈地惩罚过界的边界值。但是选择使用哪一个损失函数需要通过实验结果来判断。
- 举例

- 根据上面的公式计算:$$L = \max(0,437.9-(-96.8)) + \max(0,61.95-(-96.8))=695.45$$
- 猫的分类得分在三个类别中不是最高得,所以我们需要继续优化。
- Suppose that we found a W such that L = 0. Is this W unique?
- No! 2W is also has L = 0!
- Regularization: 正则化,向某一些特定的权值 W 添加惩罚,防止权值过大,减轻模型的复杂度,提高泛化能力,也避免在数据集中过拟合现象。
- $$L=\frac{1}{N}\sum_iL_i\left(f\left(x_i,W\right),y_i\right) + \lambda R(W)$$
R正则项 $$\lambda$$ 正则化参数
- 常用正则化方法
- L2$$\begin{matrix} R(W)=\sum_{k}\sum_l W^2_{k,l} \end{matrix}$$
- L1$$\begin{matrix} R(W)=\sum_{k}\sum_l \left\vert W_{k,l} \right\vert \end{matrix}$$
- Elastic net(L1 + L2): $$\begin{matrix} R(W)=\sum_{k}\sum_l \beta W^2_{k,l} + \left\vert W_{k,l} \right\vert \end{matrix}$$
- Dropout
- Batch normalization
- etc
- L2 惩罚倾向于更小更分散的权重向量,L1 倾向于稀疏项。
- Softmax function:
- $$f_j(z)=\frac{e^{s_i}}{\sum e^{s_j}}$$
- 该分类器将输出向量 f 中的评分值解释为没有归一化的对数概率,通过归一化之后,所有概率之和为1。
- Loss 也称交叉熵损失 cross-entropy loss $$L_i = - \log\left(\frac{e^{s_i}}{\sum e^{s_j}}\right)$$
1 | f = np.array([123, 456, 789]) # 例子中有3个分类,每个评分的数值都很大 |
- SVM 和 Softmax 比较
- 评分,SVM 的损失函数鼓励正确的分类的分值比其他分类的分值高出一个边界值。
- 对数概率,Softmax 鼓励正确的分类归一化后的对数概率提高。
- Softmax 永远不会满意,SVM 超过边界值就满意了。
- Optimization:最优化过程
- Follow the slope
- Follow the slope
- 梯度是函数的斜率的一般化表达,它不是一个值,而是一个向量,它是各个维度的斜率组成的向量。
- Numerical gradient: Approximate, slow, easy to write. (But its useful in debugging.)
- Analytic gradient: Exact, Fast, Error-prone. (Always used in practice)
- 实际应用中使用分析梯度法,但可以用数值梯度法去检查分析梯度法的正确性。
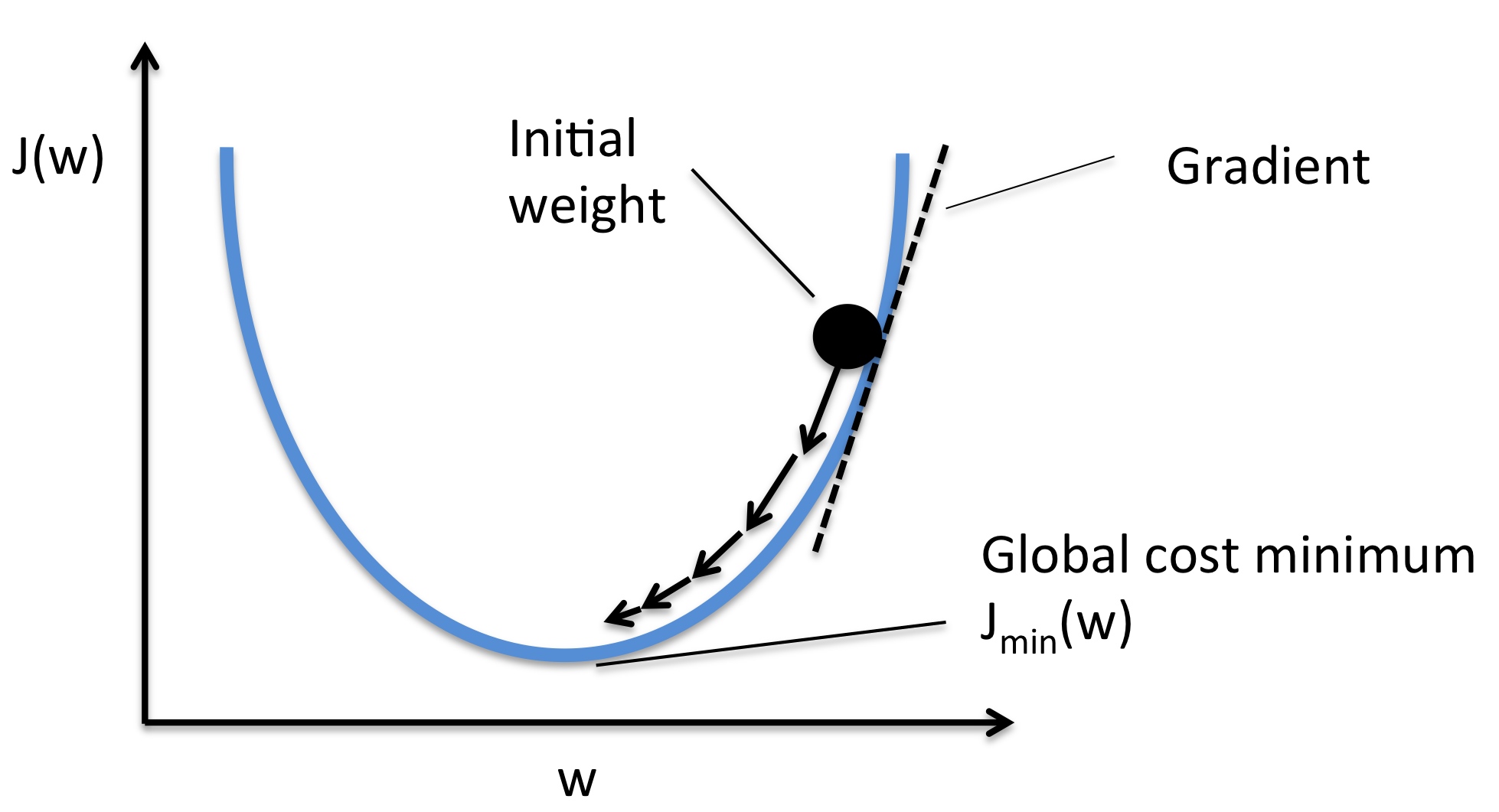
- 利用梯度优化参数的过程:
W = W - learning_rate * W_grad - learning_rate 被称为是学习率,是一个比较重要的超参数
- Stochastic Gradient Descent SGD 随机梯度下降法
- 每次使用一小部分的数据进行梯度计算,这样可以加快计算的速度。
- 每个批量中只有1个数据样本,则被称为随机梯度下降(在线梯度下降)
- 图像分类任务中三大关键部分:
- 评分函数
- 损失函数:量化某个具体参数 ${W}$ 的质量
- 最优化:寻找能使得损失函数值最小化的参数 ${W}$ 的过程
04. Introduction to Neural network
- 反向传播:在已知损失函数 ${L}$ 的基础上,如何计算导数${\nabla _WL}$?
- 计算图
- 由于计算神经网络中某些函数的梯度很困难,所以引入计算图的概念简化运算。
- 在计算图中,对应函数所有的变量转换成为计算图的输入,运算符号变成图中的一个节点(门单元)。
- 反向传播:从尾部开始,根据链式法则递归地向前计算梯度,一直到网络的输入端。
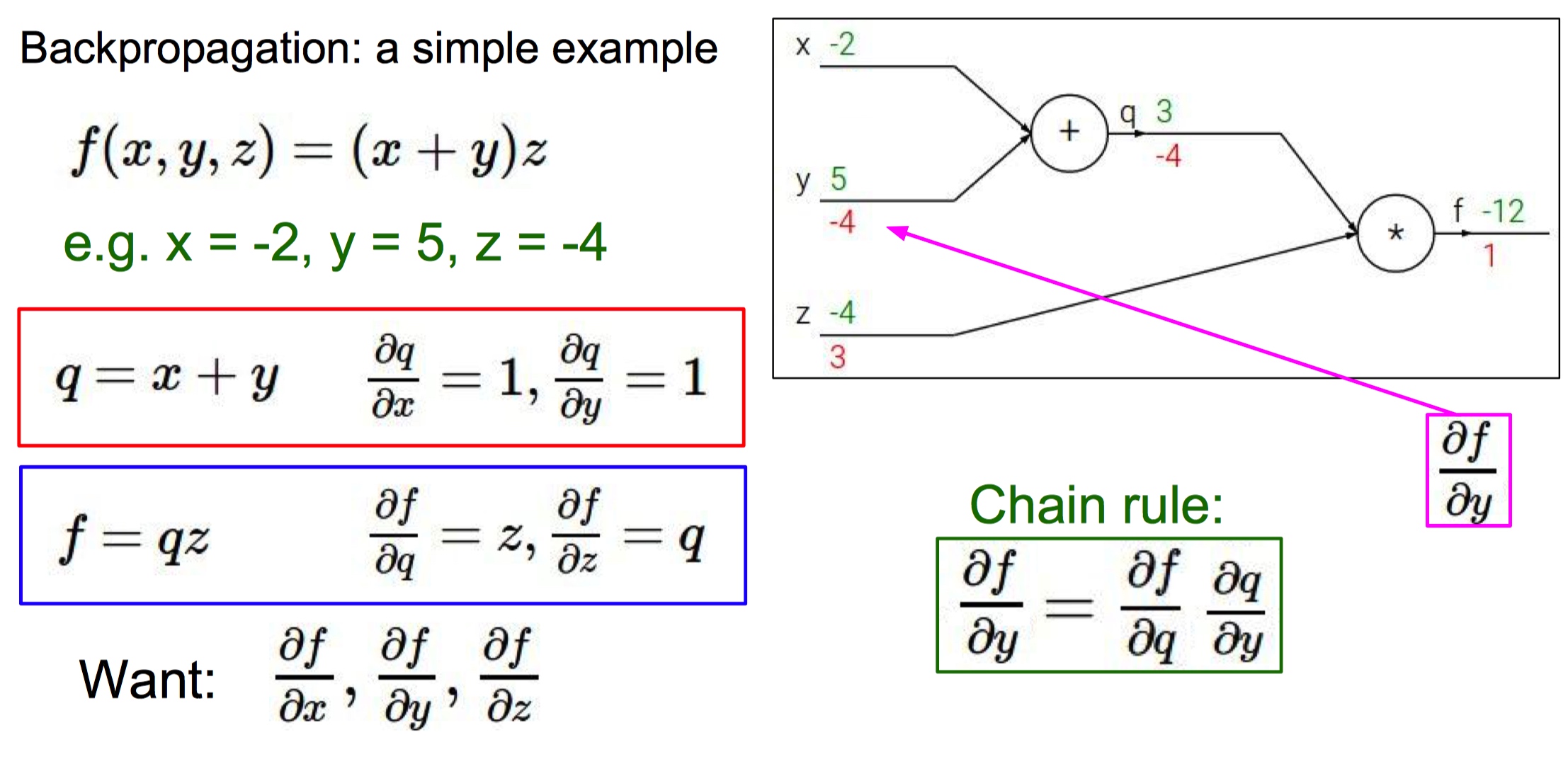
- 绿色是正向传播,红色是反向传播。
- 对于计算图中的每一个节点,我们需要计算这个节点上的局部梯度,之后根据链式法则反向传递梯度。
- Sigmoid 函数:${f(w,x)=\frac{1}{1+e^{-(w_0x_0+w_1x_1+w_2)}}}$
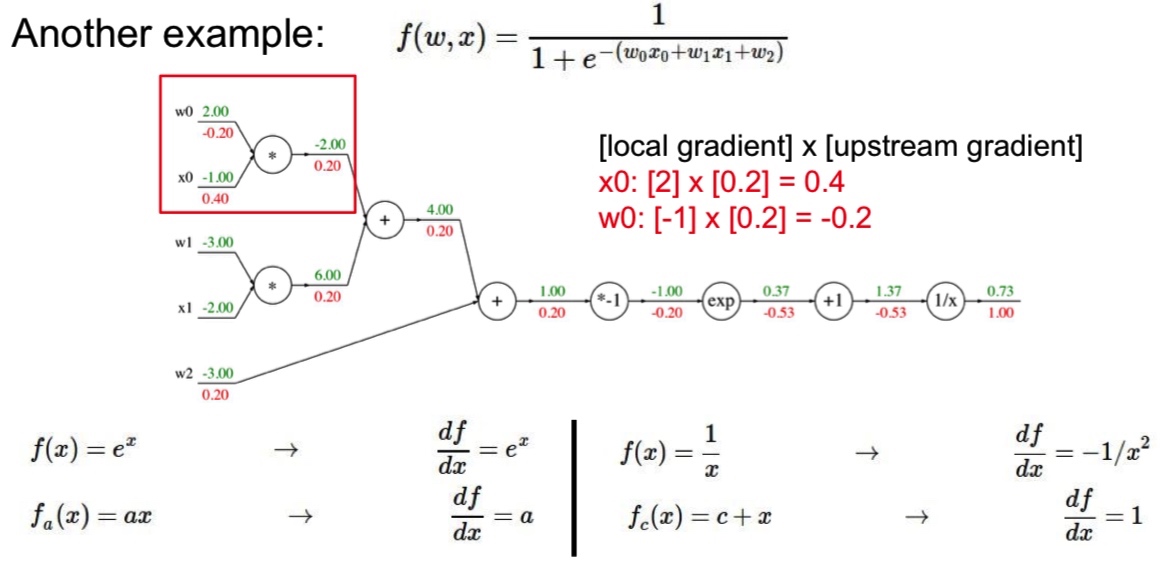
- 对于门单元 ${\frac{1}{x}}$,求导的结果是 ${-\frac{1}{x^2}}$,输入为 1.37,梯度返回值为 1.00,所以这一步中的梯度是 ${(\frac{-1}{1.37^2})*1.00=-0.53}$。
- 模块化思想:对 ${\sigma(x)=\frac{1}{1+e^{-x}}}$ 求导的结果是 ${(1-\sigma(x))\sigma(x)}$。如果 sigmoid 表达式输入值为 1.0 时,则前向传播中的结果是 0.73。根据求导结果计算可得局部梯度是 ${(1-0.73)*0.73=0.2}$。
- Modularized implementation: forward/backwar API
1 | class MultuplyGate(object): |
- 深度学习框架中会实现的门单元:Multiplication、Max、Plus、Minus、Sigmoid、Convolution
- 常用计算单元
- 加法门单元:把输出的梯度相等地分发给它所有的输入,这一行为与输入值在前向传播时的值无关。
- 取最大值门单元:将梯度转给前向传播中值最大的那个输入,其余输入的值为0。
- 乘法门单元:等值缩放。局部梯度就是输入值,但是需要相互交换,然后根据链式法则乘以输出值得梯度。
- Neural NetWorks
- (Before) Linear score function $$f = Wx$$
- (Now) 2-layer Neural NetWork $$f=W_2\max(0,W_1x)$$
- ReLU $$\max(0,x)$$ 是激活函数,如果不使用激活函数,神经网络只是线性模型的组合,无法拟合非线性情况。
- 神经网络是更复杂的模型的基础组件
05. Convolutional neural networks (CNNs)
- 这一轮浪潮的开端:AlxNet
- 卷积神经网络
- Fully Connected Layer 全连接层:这一层中所有的神经元链接在一起。
- Convolution Layer:
- 通过参数共享来控制参数的数量。Parameter sharing
- Sparsity of connections
- 卷积神经网络能学习到不同层次的输入信息
- 常见的神经网络结构:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC - 使用小的卷积核大小的优点:多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好地特征。而且使用的参数也会更少
- 计算卷积层输出
- stride 是卷积核在移动时的步长
- 通用公式 (N-F)/stride + 1
- stride 1 => (7-3)/1 + 1 = 5
- stride 2 => (7-3)/2 + 1 = 3
- stride 3 => (7-3)/3 + 1 = 2.33
- Zero pad the border: 用零填充所有的边界,保证输入输出图像大小相同,保留图像边缘信息,提高算法性能
- 步长为 1 时,需要填充的边界计算公式:(F-1)/2
- F = 3 => zero pad with 1
- F = 5 => zero pad with 2
- F = 7 => zero pad with 3
- 步长为 1 时,需要填充的边界计算公式:(F-1)/2
- 计算例子
- 输入大小
32*32*3卷积大小 10 5*5 stride 1 pad 2 - output
32*32*10 - 每个 filter 的参数数量:
5*5*3+1 =76bias - 全部参数数量 76*10=760
- 输入大小
- 卷积常用超参数设置
- 卷积使用小尺寸滤波器
- 卷积核数量 K 一般为 2 的次方倍
- 卷积核的空间尺寸 F
- 步长 S
- 零填充数量 P
- Pooling layer
- 降维,减少参数数量。在卷积层中不对数据做降采样
- 卷积特征往往对应某个局部的特征,通过池化聚合这些局部特征为全局特征
- Max pooling
- 2*2 stride 2
- 避免区域重叠
- Average pooling
06. Training neural networks I
Activation functions 激活函数
- 不使用激活函数,最后的输出会是输入的线性组合。利用激活函数对数据进行修正。
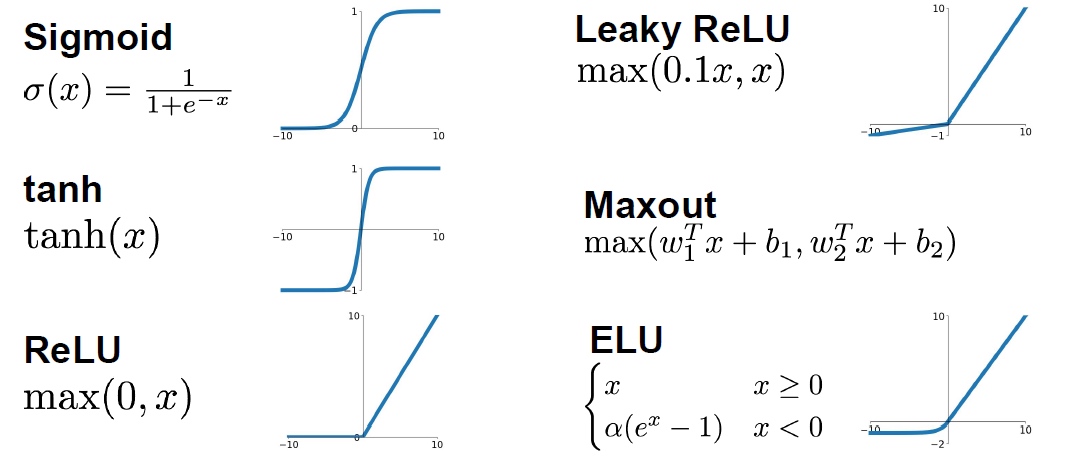
- Sigmoid
- 限制输出在 [0,1]区间内
- firing rate
- 二分类输出层激活函数
- Problem
- 梯度消失:x很大或者很小时,梯度很小,接近于0(考虑图像中的斜率。无法得到梯度反馈。
- 输出不是 0 均值的数据,梯度更新效率低
- exp is a bit compute expensive
- tanh
- 输出范围 [-1, 1]
- 0 均值
- x 很大时,依然没有梯度
- ${f(x)=\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}}}$
- ${1-(tanh(x))^2}$
- RELU rectified linear unit 线性修正单元
- 一半空间梯度不会饱和,计算速度快,对结果又有精确的计算
- 不是 0 均值
- Leaky RELU
leaky_RELU(x) = max(0.01x, x)- 梯度不会消失
- 需要学习参数
- ELU
- 比 ReLU 好用
- 反激活机制
- Maxout
- maxout(x) = max(w1.Tx + b1, w2.Tx + b2)
- 梯度不会消失
- 增大参数数量
- 激活函数选取经验
- 使用 ReLU ,但要仔细选取学习率
- 尝试使用 Leaky ReLU Maxout ELU
- 使用 tanh 时,不要抱有太大的期望
- 不要使用 sigmoid
数据预处理 Data Preprocessing
- 均值减法:对数据中每个独立特征减去平均值,从几何上来看是将数据云的中心都迁移到原点。
- 归一化:将数据中的所有维度都归一化,使数值范围近似相等。但是在图像处理中,像素的数值范围几乎一致,所以不需要额外处理。
1
2X -= np.mean(X, axis = 1)
X /= np.std(X, axis =1)- 图像归一化
- Subtract the mean image AlexNet
- mean image 32,32,3
- Subtract per-channel mean VGGNet
- mean along each channel = 3 numbers
- 如果需要进行均值减法时,均值应该是从训练集中的图片平均值,然后训练集、验证集、测试集中的图像再减去这个平均值。
- Subtract the mean image AlexNet
- Weight Initialization
- 全零初始化
- 网络中的每个神经元都计算出相同的输出,然后它们就会在反向传播中计算出相同的梯度。神经元之间会从源头上对称。
- Small random numbers
- 初始化权值要非常接近 0 又不能等于 0。将权重初始化为很小的数值,以此来打破对称性
- randn 函数是基于零均值和标准差的高斯分布的随机函数
- W = 0.01 * np.random.rand(D,H)
- 问题:一个神经网络的层中的权重值很小,那么在反向传播的时候就会计算出非常小的梯度。会减小反向传播中的“梯度信号”,在深度网络中就会出现问题。
- Xavier initialization
- W = np.random.rand(in, out) / np.sqrt(in)
- 校准方差,解决输入数据量增长,随机初始化的神经元输出数据的分布中的方差也增大问题。
- He initialization
- W = np.random.rand(in, out) / np.sqrt(in/2)
- 全零初始化
- Batch normalization
- 保证输入到神经网络中的数据服从标准的高斯分布
- 通过批量归一化可以加快训练的速度
- 步骤
- 首先计算每个特征的平均值和平方差
- 通过减去平局值和除以方差对数据进行归一化
Result = gamma * normalizedX + beta- 对数据进行线性变换,相当于对数据分布进行一次移动,可以恢复数据之前的分布特征
- BN 的好处
- 加快训练速度
- 可以使用更快的而学习率
- 减少数据对初始化权值的敏感程度
- 相当于进行一次正则化
- BN 适用于卷积神经网络和常规的 DNN,在 RNN 和增强学习中表现不是很好
- Babysitting the Learning Provess
- Hyperparameter Optimization
- Cross-validation 策略训练
- 小范围内随机搜索
07. Training neural networks II
- Optimization Algorithms:
SGD 的问题
x += - learning_rate * dx- 梯度在某一个方向下降速度快,在其他方向下降缓慢
- 遇到局部最小值点,鞍点
mini-batches GD
- Shuffling and Partitioning are the two steps required to build mini-batches
- Powers of two are often chosen to be the mini-batch size, e.g., 16, 32, 64, 128.
SGD + Momentun
- 动量更新:从物理学角度启发最优化问题
V[t+1] = rho * v[t] + dx; x[t+1] = x[t] - learningRate * V[t+1]- rho 被看做是动量,其物理意义与摩擦系数想类似,常取 0.9 或0.99
- 和 momentun 项更新方向相同的可以快速更新。
- 在 dx 中改变梯度方向后, rho 可以减少更新。momentun 能在相关方向加速 SGD,抑制震荡,加快收敛。
Nestrov momentum
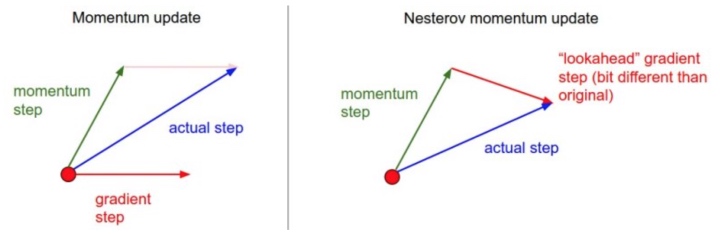
v_prev = v; v = mu * v - learning_rate * dx; x += -mu * v_prev + (1 + mu) * v
AdaGrad
- $n_t=n_{t-1}+g^2_t$
- $\Delta \theta _t = -\frac{\eta}{\sqrt{n_t+\epsilon}}$
- 下面根号中会递推形成一个约束项。前期这一项比较大,能够放大梯度。后期这一项比较小,能约束梯度。
- gt 的平方累积会使梯度趋向于 0
RMSProp
- RMS 均方根
- 自适应学习率方法
- 求梯度的平方和平均数:
cache = decay_rate * cache + (1 - decay_rate) * dx2 x += - learning_rate * dx / (sqrt(cache) + eps)- 依赖全局学习率
Adam
- RMSProp + Momentum
- It calculates an exponentially weighted average of past gradients, and stores it in variables $v$ (before bias correction) and $v^{corrected}$ (with bias correction).
- It calculates an exponentially weighted average of the squares of the past gradients, and stores it in variables $s$ (before bias correction) and $s^{corrected}$ (with bias correction).
- 一阶到导数累积,二阶导数累积
- It updates parameters in a direction based on combining information from “1” and “2”.
- The update rule is, for $l = 1, …, L$:
$$\begin{cases}
v_{dW^{[l]}} = \beta_1 v_{dW^{[l]}} + (1 - \beta_1) \frac{\partial \mathcal{J} }{ \partial W^{[l]} } \
v^{corrected}{dW^{[l]}} = \frac{v{dW^{[l]}}}{1 - (\beta_1)^t} \
s_{dW^{[l]}} = \beta_2 s_{dW^{[l]}} + (1 - \beta_2) (\frac{\partial \mathcal{J} }{\partial W^{[l]} })^2 \
s^{corrected}{dW^{[l]}} = \frac{s{dW^{[l]}}}{1 - (\beta_1)^t} \
W^{[l]} = W^{[l]} - \alpha \frac{v^{corrected}{dW^{[l]}}}{\sqrt{s^{corrected}{dW^{[l]}}} + \varepsilon}
\end{cases}$$
where:
- t counts the number of steps taken of Adam
- L is the number of layers
- $\beta_1$ and $\beta_2$ are hyperparameters that control the two exponentially weighted averages.
- $\alpha$ is the learning rate
- $\varepsilon$ is a very small number to avoid dividing by zero
特点:
- 适用于大数据集和高维空间。
- 对不同的参数计算不同的自适应学习率。
Learning decay
- 学习率随着训练变化,比如每一轮在前一轮的基础上减少一半。
- 防止学习停止
Second order optimization
- Regularization
- Dropout
- 每一轮中随机使部分神经元失活,减少模型对神经元的依赖,增强模型的鲁棒性。
- Dropout
- Transfer learning
- CNN 中的人脸识别,可以在大型的模型基础上利用少量的相关图像进行继续训练。
09. CNN architectures
- 研究模型的方法:搞清楚每一层的输入和输出的大小关系。
- LeNet - 5 [1998]
- 60k 参数
- 深度加深,图片大小减少,通道数量增加
- ac: Sigmod/tanh
- AlexNet [2012]
- (227,227,3) (原文错误)
- 60M 参数
- LRN:局部响应归一化,之后很少使用
- VGG - 16 [2015]
- 138 M
- 结构不复杂,相对一致,图像缩小比例和通道增加数量有规律
- ZFNet [2013]
- 在 AlexNet 的基础上修改
CONV1: change from (11 x 11 stride 4) to (7 x 7 stride 2)CONV3,4,5: instead of 384, 384, 256 filters use 512, 1024, 512
- 在 AlexNet 的基础上修改
- VGG [2014]
- 模型中只使用 3*3 conv:与 77 卷积有相同的感受野,而且可以将网络做得更深。比如每一层可以获取到原始图像的范围:第一层 33,第二层 55,第三层 77。
- 前面的卷积层参数量很少,模型中大部分参数属于底部的全连接层。
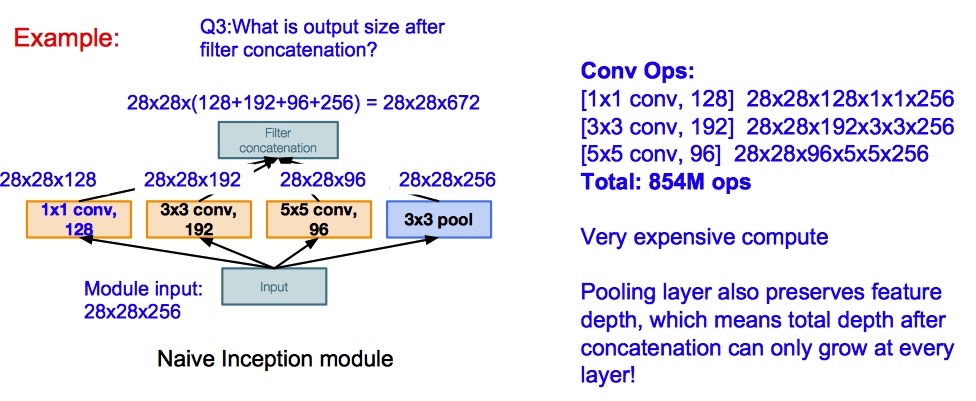
- GoogLeNet
- 引入
Inception module- design a good local network topology (network within a network) and then stack these modules on top of each other
- 该模块可以并行计算
- conv 和 pool 层进行 padding,最后将结果 concat 在一起
- 引入
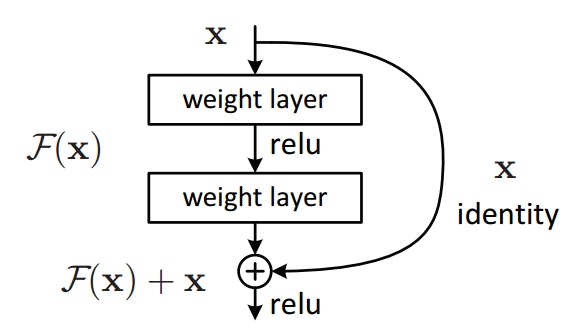
- ResNet
- 目标:深层模型表现不应该差于浅层模型,解决随着网络加深,准确率下降的问题。
Y = (W2* RELU(W1x+b1) + b2) + X- 如果网络已经达到最优,继续加深网络,residual mapping会被设置为 0,一直保存网络最优的情况。