GAT
两种方式
Global graph attention
每个顶点 i 都对图上任意顶点进行 attention 计算
相当于不考虑图结构
Mask graph attention
- 只在相邻顶点上计算
GAL graph attentional layer
attention 系数 $e_{i, j}=a\left(\mathbf{W} \overrightarrow{\mathbf{h}}{i}, \mathbf{W} \overrightarrow{\mathbf{h}}{j}\right)$
共享参数 W 相当于对顶点特征进行增维
站在顶点 i 的角度看顶点 j 对它的重要性
masked attention 机制,只计算顶点 i 和其他相邻点的系数
$\alpha_{i, j}=\operatorname{softmax}{j}\left(e{i, j}\right)=\frac{\exp \left(\operatorname{LeakyReLU}\left(\overrightarrow{\mathbf{a}} \cdot\left[\mathbf{W} \overrightarrow{\mathbf{h}}{i}, \mathbf{W} \overrightarrow{\mathbf{h}}{j}\right]\right)\right)}{\left.\sum_{k \in \mathcal{N}{i}} \exp \left(\operatorname{LeakyReLU}\left(\overrightarrow{\mathbf{a}} \cdot\left[\mathbf{W} \overrightarrow{\mathbf{h}}{i}, \mathbf{W} \overrightarrow{\mathbf{h}}_{k}\right]\right)\right)\right)}$
每个顶点最终输出 $\overrightarrow{\mathbf{h}}{i}^{\prime}=\sigma\left(\sum{j \in \mathcal{N}{i}} \alpha{i, j} \mathbf{W} \overrightarrow{\mathbf{h}}_{j}\right)$
multi-head attention
- $h_{i}^{\prime}(K)=|{k=1}^{K} \sigma\left(\sum{j \in \mathcal{N}{i}} \alpha{i j}^{k} W^{k} h_{j}\right)$
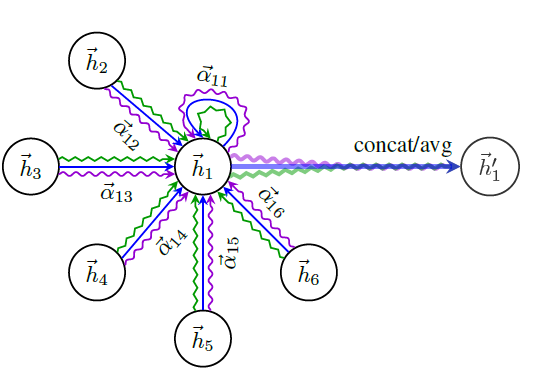
和 [[GCN]] 联系
将临接点的特征聚合到中心顶点上,利用 graph 的 local stationary 学习新的顶点特征表达。
GCN 利用 [[Laplacian matrix]],GAT 利用 attention 系数
如何适用于 inductive 任务
学习参数 W 和 a,与顶点特征相关,与图结构无关
GCN 是一种全图计算方法,一次计算就更新全图的节点特征
Graph Attention Network的本质是什么? - 知乎 (zhihu.com) [[2023/03/03]]
Graph Convolution 的核心思想是利用边的信息对节点进行聚合,从而生成新的节点表示。
CNN 是利用节点信息生成新的节点表示?
如何让模型学习到相邻节点的权值?
利用相似度
利用 cost 衡量两个节点的相似度 AGNN
$a_{\text {learn }}(i, j)=\frac{\exp \left(\beta \times \cos \left(W x_i, W x_j\right)\right)}{\Sigma_{k \in \text { neigh }(i)} \exp \left(\beta \times \cos \left(W x_i, W x_j\right)\right)}$
完全利用学习 GAT
- $a_{\text {learn }}(i, j)=\frac{\exp \left(\operatorname{LeakyReLU}\left(w\left[W x_i, W x_j\right]\right)\right)}{\Sigma_{k \in n e i g h(i)} \exp \left(\operatorname{LeakyReLU}\left(w\left[W x_i, W x_k\right]\right)\right)}$
GNN 让模型关注到 Garph 中最重要的节点/节点中最重要的信息从而提高信噪比。
- GAT 利用节点之间的关系,区分联系的层级,增强任务中需要的有效信息。
GAT 在同质图上学不到任何有用的 attention 值
Cora 机器学论文,7类
citeseer 科学论文,6类
非同质 PPI
- 节点蛋白质,边表示蛋白质之间的相互作用
退化成 GCN