Batch Normalization
缓解神经网络“内部协方差漂移”([[Internal Covariance Shift]], ICS)
- How Does Batch Normalization Help Optimization?
对每个隐藏层输入进行 0-1 标准化
神经网络本身是为了学习数据的分布,如果训练集和测试集分布不同,会导致学习的神经网络泛化性能大大降低
- 每一层神经网络依赖前一层神经网络,如果前一层分布一直改变,后一层很学习。
网络每次迭代需要拟合不通的数据分布,增大训练的复杂度以及过拟合的风险。
对输入的数据分布进行额外的约束,从而增强模型的泛化能力,但也降低了模型的拟合能力
[[covariate shift]] 源空间和目标空间的条件概率是一致的,但是其边缘概率不同。神经网络的各层输出由于层内操作,其分布显然与各层对应的输入信号分布不同。
在神经网络训练时遇到收敛速度很慢,或者梯度爆炸等无法训练时可以尝试使用。
batch_mean, bacth_var = tf.nn.moments(data, [0]) 求 data 数据的每一列的均值和方差
tf.nn.batch_normalization(data, mean, variance, offset, scale, variance_epsilon, name=None)
- offset 和 scale 是参数,分别初始化为 0 和 1
- variance_epsilon 很小的一个值,防止除零
批归一化也会降低模型的拟合能力,比如 sigmoid 激活函数中,批量归一化后数据整体处于函数的非饱和区,破坏之前学到的连接权重。引入 offset 和 scala 是为了能还原成最初的输入,与之前的网络层解耦。
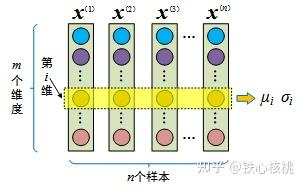
$\mu_{i}=\frac{1}{M} \sum x_{i}, \quad \sigma_{i}=\sqrt{\frac{1}{M} \sum\left(x_{i}-\mu_{i}\right)^{2}+\epsilon}$
- 对每个维度的特征计算均值和标准差
+
算法流程

occlusion:: eyIuLi9hc3NldHMvaW1hZ2VfMTcyNDE3MjAzMTgxN18wLnBuZyI6eyJjb25maWciOnsiaGlkZUFsbFRlc3RPbmUiOnRydWV9LCJlbGVtZW50cyI6W3sibGVmdCI6MTkxLjUxNTUyOTA3NzA4ODUzLCJ0b3AiOjE4OS41OTQ0MTY2NTQ0MjUyMywid2lkdGgiOjEzMS4xMTE5ODc5MjE3NDAxNCwiaGVpZ2h0IjoxMTEuMDQ2MzYzNjc5NTEyNjQsImFuZ2xlIjowLCJjSWQiOjF9LHsibGVmdCI6MjM3LjYyNjk0ODU1ODAzOTU0LCJ0b3AiOjI5My41MjM4MzU2MzQwMjc1Mywid2lkdGgiOjIyNS41NTcwNjM5NjcwNjExNywiaGVpZ2h0Ijo4OS43NDU0MTY3MDE4ODkyMSwiYW5nbGUiOjAsImNJZCI6Mn0seyJsZWZ0IjoyNDguMTgyNTc0NzA0MjgxMywidG9wIjozODEuOTEwMzMxMTI3MTkxMzQsIndpZHRoIjoyNDIuMjIzODQyMDkyNzA2MTUsImhlaWdodCI6NzUuMTAwMTE2Njg3NjUwMDcsImFuZ2xlIjowLCJjSWQiOjN9LHsibGVmdCI6MjY2LjUxNjAzMDY0MjQ5MDcsInRvcCI6NDUxLjA3ODgwMTY1ODU3NzEsIndpZHRoIjoyNzguODkwNzUzOTY5MTI0OTQsImhlaWdodCI6NTguOTE0MTUzMDI3MTIyODksImFuZ2xlIjowLCJjSWQiOjR9LHsibGVmdCI6NjAzLjY0ODM4NDc1Njg5NTQsInRvcCI6MTk1LjAyMjI3MzI2Mjk1NTIsIndpZHRoIjoxOTcuOTYzMzQ3MDEzMjc0NTYsImhlaWdodCI6NTQuNDEyOTk1NjA2OTAwNjQsImFuZ2xlIjowLCJjSWQiOjV9LHsibGVmdCI6NTg3LjkyNzU4NTQ5NDI5NTQsInRvcCI6MjkzLjg0NDM0ODI0MTY1MzcsIndpZHRoIjoyMzYuMDcxNjU2Nzg4NzMyNTUsImhlaWdodCI6NDUuNTQ4NjI2MzI2NTA1NzcsImFuZ2xlIjowLCJjSWQiOjZ9LHsibGVmdCI6NjI3LjUzNjE2NDM5MTM4MDgsInRvcCI6MzczLjczOTY1NTI2MDY1MzU0LCJ3aWR0aCI6MTU4LjQsImhlaWdodCI6NDMuNDQ0NjUyNjE4NzA3ODM1LCJhbmdsZSI6MCwiY0lkIjo3fSx7ImxlZnQiOjYxOS40MjY5ODM2MTU4MTI5LCJ0b3AiOjQ0NC41MzkyOTM0MTA5MDQyNCwid2lkdGgiOjE3NS4yOTUwOTc2MjkxMTY5OCwiaGVpZ2h0Ijo0My45ODU0NDY0NzUwMDc5NiwiYW5nbGUiOjAsImNJZCI6OH1dfX0=
原理
- 加快网络训练和收敛的速度:每层数据的分布一致
- 防止梯度爆炸和梯度消失
- BN 防止过拟合:minibatch 中的样本被关联在一起,一个样本的输出取决于样本本身,也取决于同属一个batch的其他样本。
[[Batch Normalization/前向和反向传播]]
[[Batch Normalization/维度理解]]
如何得到预测时 BN 层使用的均值和方差?
- 训练时,保留每组 mini-batch 训练数据在网络每一层的均值和方差
- 均值、方差是基于所有批次的期望计算所得
- $E[x] \leftarrow E_{B}\left[\mu_{B}\right]$
- $\operatorname{Var}[x] \leftarrow \frac{m}{m-1} E_{B}\left[\sigma_{B}^{2}\right]$
- moving statistics [[Batch Normalization/Moving average]]
如果训练时使用这个方法,会减少当前 batch 对参数的影响
Batch Normalization 训练的时候为什么不使用 moving statistics? - 知乎 (zhihu.com)
不能对统计量求导
除以标准差后的梯度方向是与减均值之后的feature垂直的,用这个梯度更新不会引起 feature scale 的剧变,从而解决梯度爆炸
moving statistics 对于 BN输入的变化是滞后的
为什么BN层一般用在线性层和卷积层后面,而不是放在非线性单元后
BN 层希望得到 0-1 高斯分布 的数据
非线性单元之后的数据分布 不一定对称
实践中 BN 放在 ReLU 后面 #card
- Normalization 一般是在输入层之前对数据处理,Batch-Normalization 可以视作对传给隐藏层的输入的normalization。
放在 tanh 或 sigmoid 之前,可以 避免进入饱和区,缓解梯度衰减问题 。
BN 和 [[ReLU]] 的顺序关系?[[ResNet]] :->
Skip -> BN -> RELU -> Conv -> BN -> RELU -> Conv -> Add- [[Identity Mappings in Deep Residual Networks]]
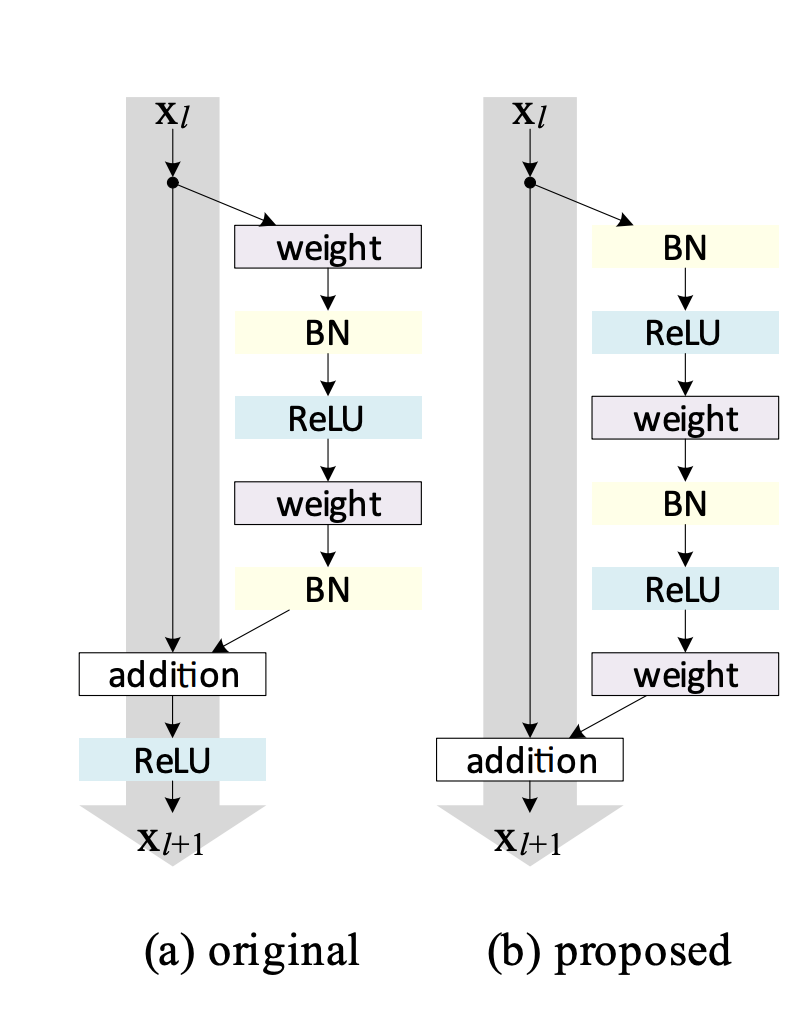
- BN-ReLU
- 特点 :-> BN 后输入数据更接近 0 均值,或减轻数据落入负区间梯度消失现象,或更好展现 ReLU 的单侧抑制作用进行特征选择
- ReLU-BN
- 特点 :-> 激活后再 Norm,保证下一层的输入是零均值的。
[[Batch Normalization/多卡同步]]
- 特点 :-> 激活后再 Norm,保证下一层的输入是零均值的。
[[Batch Normalization 为何有效]]
[[Ref]]
Batch Normalization
https://blog.xiang578.com/post/logseq/Batch Normalization.html