BERT
[[@BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding]]
代码:google-research/bert: TensorFlow code and pre-trained models for BERT
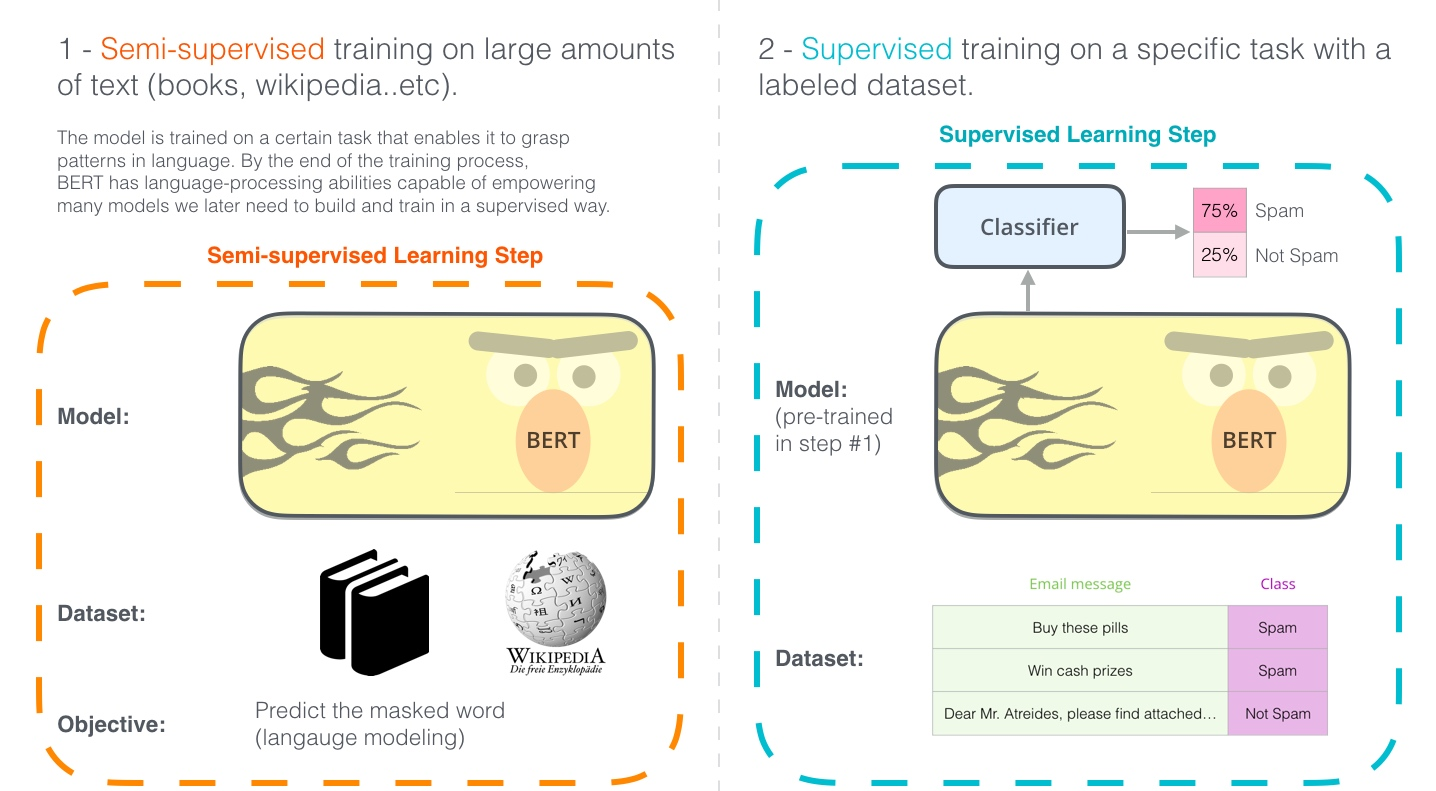
大模型 + 微调提升小任务的效果
输入层
词嵌入(token embedding)、位置嵌入(position embedding)段嵌入(segment embedding)
- 预训练任务包含判断 segment A 和 segment B 之间的关系
模型结构 12 层,每层 12 个 multi-head
CLS 句子开头,最后的输出 emb 对应整句信息
- 无语义信息的符号会更公平地融合文本中各个词的语义信息,从而更好的表示整句话的语义
SEP 句子之间分割
BERT
L=12 H=768 A=12, Total Parameters=110M
L=24 H=1024 A=16, Total Parameters=340M
两种 NLP 预训练
- 产出产品,例如 word2evc 的 embedding
- 做为骨架接新结构
[[ELMo]]
- 使用 LSTM 预测下一个单词
[[GPT]]
Transformer
单向
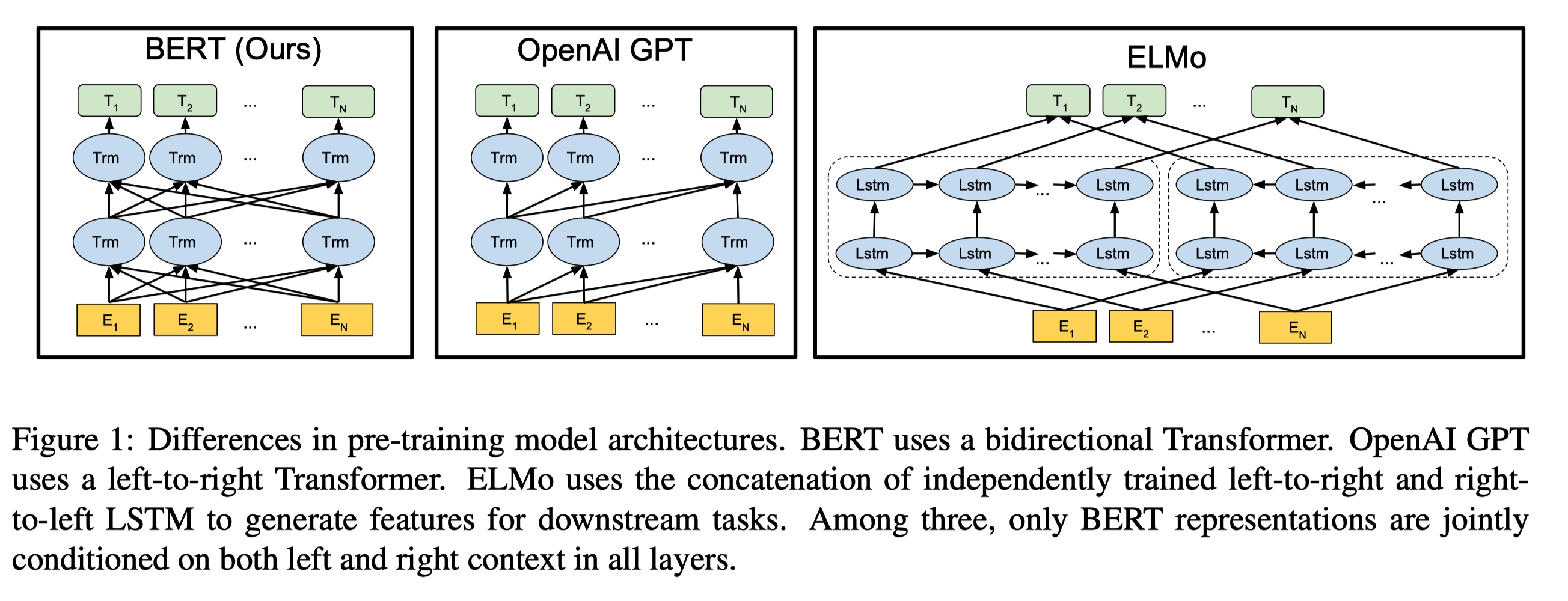
贡献性
- 双向信息重要性
模型输入:
- Token emb
- Segment emb(A B) 针对 QA 或者两个句子的任务
- Position emb
训练方式
[[Masked-Language Modeling]] :->mask 部分单词,80 % mask,10 % 错误单词, 10% 正确单词
- 目的 :-> 训练模型记忆句子之间的关系。
- 减轻预训练和 fine-tune 目标不一致给模型带来的影响
- 目的 :-> 训练模型记忆句子之间的关系。
[[Next Sentence Prediction]] :-> 预测是不是下一个句子
句子 A 和句子 B 有 50% 的概率是上下文
解决后续什么问题 :-> QA 和自然语言推理
occlusion:: eyIuLi9hc3NldHMvaW1hZ2VfMTczNDYxNjMzODQyMV8wLnBuZyI6eyJjb25maWciOnt9LCJlbGVtZW50cyI6W3sibGVmdCI6MzY3LjEzMDExNTk3NDg1MjYsInRvcCI6NTkuNDE3NTUwMDkwNDM3Mzk1LCJ3aWR0aCI6NjIzLjU5MTg3MjM5Mzc2MDksImhlaWdodCI6MTE4LjgzNTEwMDE4MDg3NDc2LCJhbmdsZSI6MCwiY0lkIjoxfSx7ImxlZnQiOjEwODEuOTAzNDAxNTY2MDE5LCJ0b3AiOjY1LjA2OTA2NDM1NDU0MTcsIndpZHRoIjo2NjUuMjAzOTI0MjY0NDI2LCJoZWlnaHQiOjkwLjM5NTU1NzkzMTAxMTA3LCJhbmdsZSI6MCwiY0lkIjoyfV19fQ==
[[激活函数]] [[GELU]]
- 和 [[GPT]] 一致,为什么?
优化器
不完整版 adam
fine tune 时可能不稳定,需要换成正常版 adam
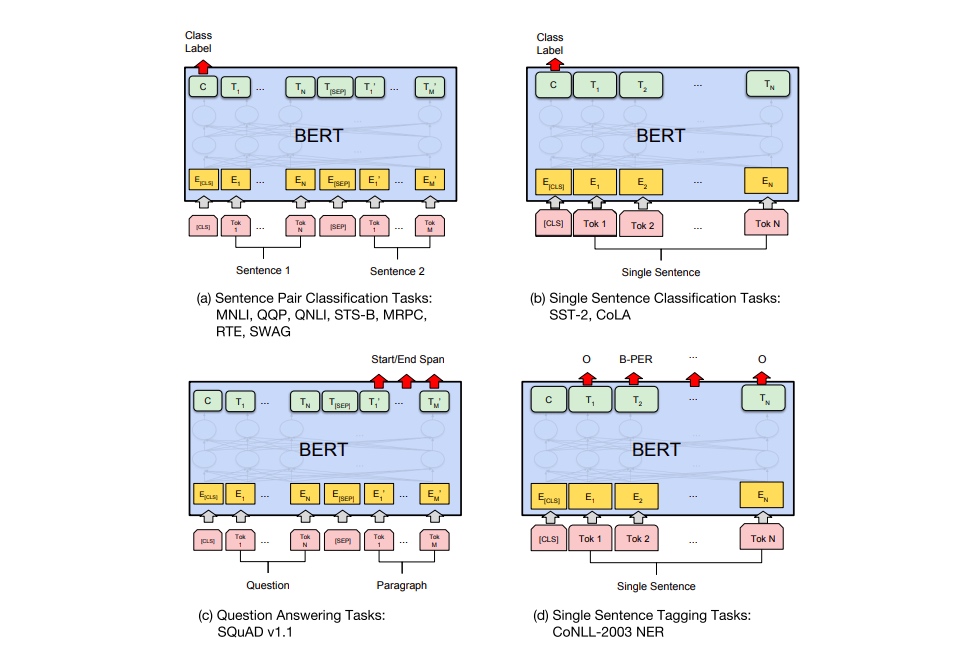
fine tune
根据任务调整输入和增加预测结构,使用相关数据训练
使用 fine tune 比将bert做为特征放到模型中效果要好
- 双句分类
- 单句分类
- CLS 后接 softmax
- 预测一个 start 和 end embedding,然后和 T 计算 softmax 取概率最大的做为开始和结束的位置
- 实体标注
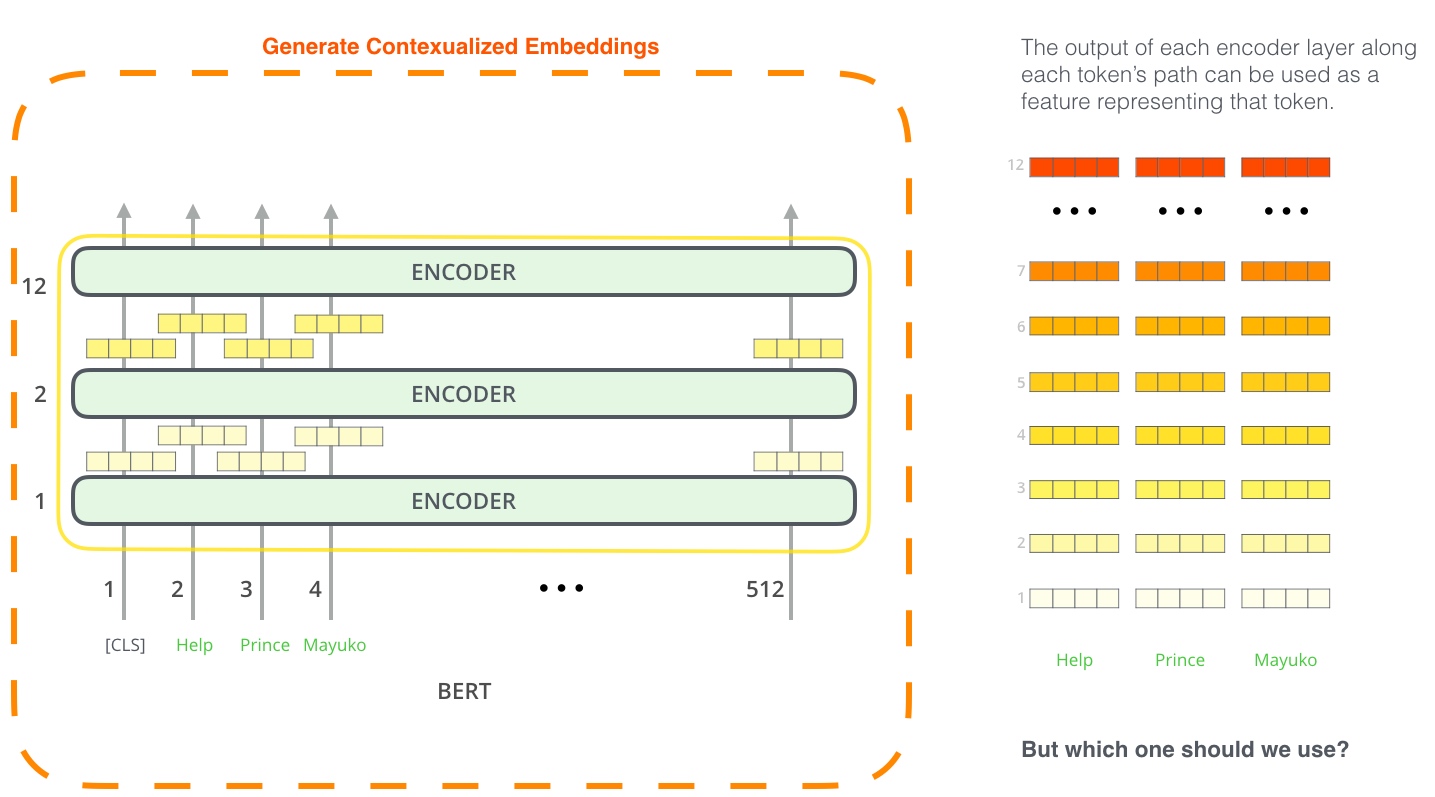
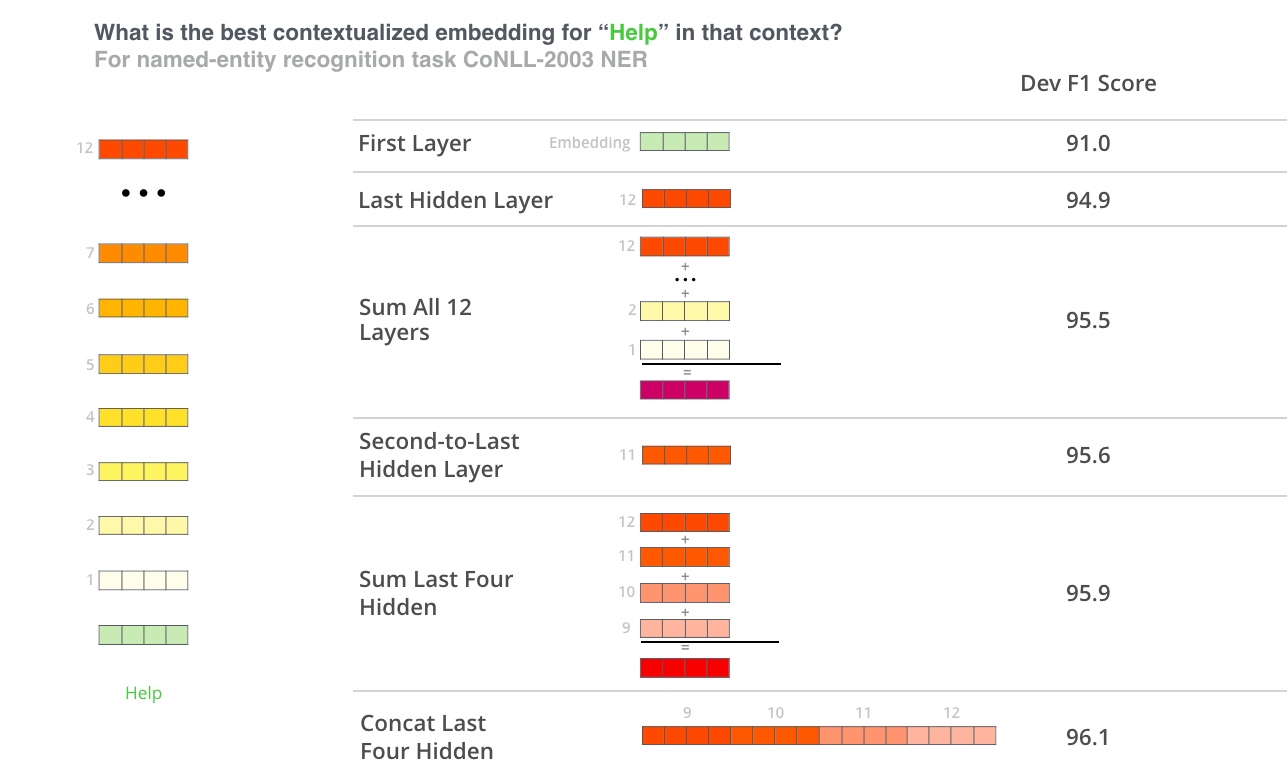
研究取不同的 embedding 效果
缺陷
- 不擅长生成类任务(机器翻译、文本摘要)
[[Ref]]
[[Multimodal BERT]]
-
像Bert这样的双向语言模型为何要做 masked LM?[[GPT]] 为何一直坚持单向语言模型? Elmo 也号称双向,为何不需要 mask?[[Word2Vec]] 的 CBOW 为何也不用 mask?
indirectly see themselves
GPT 保留用上文生成下文的能力
为什么 Bert 的三个 Embedding 可以进行相加? - 知乎
三个 embedding 相加和拼接
- 联系 :-> 三个 embedding 相加相当于三个原始的 one-hot 拼接再经过一个全连接网络。
- 优点 :-> 和拼接相比,相加可以节约模型参数。
- 实验显示拼接并没有相加效果好,拼接后维度增加,需要再经过一个线性变换降低维度,增加了更多参数。
- 联系 :-> 三个 embedding 相加相当于三个原始的 one-hot 拼接再经过一个全连接网络。
之前的理解和多个波长不同的波相加,最后还是能分离出来,所以模型也应该能区分。
空间维度很高,模型能区分各个组分
参数空间量 30k2512
模型表达能力至少是 2^768
梯度角度,
(f + g +h)' = f' + g' + h'
BERT—容易被忽视的细节
- 细节三:对于任务一,对于在数据中随机选择 15% 的标记,其中80%被换位[mask],10%不变、10%随机替换其他单词,原因是什么?#card
[mask] 在 fine-tune 任务中不会出现,模型不知道如何处理。
缓解上面的现象
15% 标记被预测,需要更多训练步骤来收敛
- 细节三:对于任务一,对于在数据中随机选择 15% 的标记,其中80%被换位[mask],10%不变、10%随机替换其他单词,原因是什么?#card