Attention
$c_{i}=\sum_{j=1}^{T_{x}} \alpha_{i j} h_{j}$
$\alpha_{i j}=\frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{T_{x}} \exp \left(e_{i k}\right)}$ 是隐藏状态 $h_j$ 的权重
用 softmax 得到一个强度表征
为什么需要使用 softmax 做归一化 #card #incremental
避免 attention score 数值过大,导致优化不稳定(数值小的部分)
保证 score 非负
$e_{i j}=a\left(s_{i-1}, h_{j}\right)$ 是注意力打分机制
代表 :-> 解码器状态 $s_{i-1}$ 和解码器状态 $h_j$ 之间的匹配程度
常用的注意力计算方式
- 加性模型 :-> $s \left(\mathbf{x}{i}, \mathbf{q}\right) =\mathbf{v}^{\mathrm{T}} \tanh \left(W \mathbf{x}{i}+U \mathbf{q}\right)$
- qkv 矩阵较大时效果超越 dot production
- 点积模型 :-> $s\left(\mathbf{x}{i}, \mathbf{q}\right) =\mathbf{x}{i}^{\mathrm{T}} \mathbf{q}$
- 不需要额外参数,但是两个矩阵大小需相同
- 缩放点积模型 :-> $s\left(\mathbf{x}{i}, \mathbf{q}\right) =\frac{\mathbf{x}{i}^{\mathrm{T}} \mathbf{q}}{\sqrt{d}}$
- 双线性模型 :-> $s\left(\mathbf{x}{i}, \mathbf{q}\right) =\mathbf{x}{i}^{\mathrm{T}} W \mathbf{q}$
聚焦式(focus)注意力:
- 加性模型 :-> $s \left(\mathbf{x}{i}, \mathbf{q}\right) =\mathbf{v}^{\mathrm{T}} \tanh \left(W \mathbf{x}{i}+U \mathbf{q}\right)$
自上而下的有意识的注意力,主动注意——是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力。
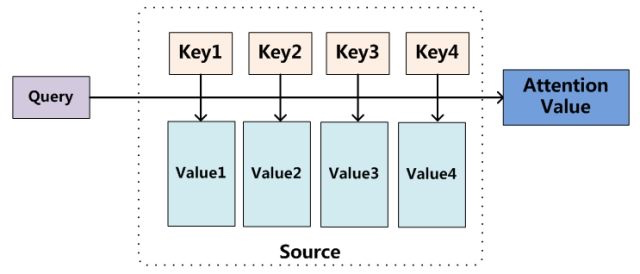
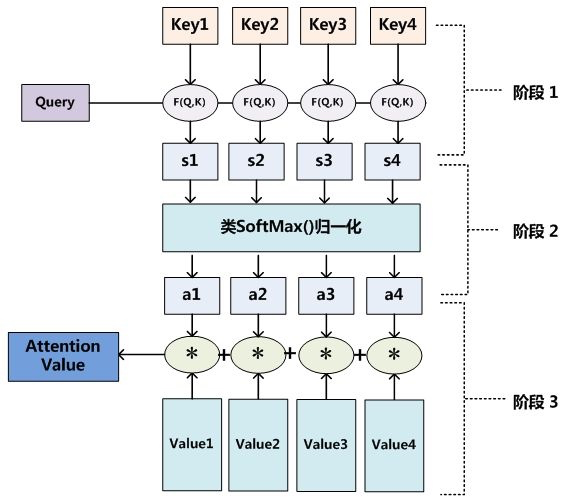
$$\text{ Attention (Query, Source) }=\sum_{i=1}^{L_{x}} \text{ Similarity (Query, Key}{i} ) * \text{Value}{i}$$
流程可视化
为什么要用 attention
参数少,速度快,能缓解神经网络模型复杂度。解决 RNN 不能并行计算问题
效果显著
按计算区域划分
soft-attention(global attention) :-> query 对所有 key 求相似度权重,得到 m*n 的 attention score
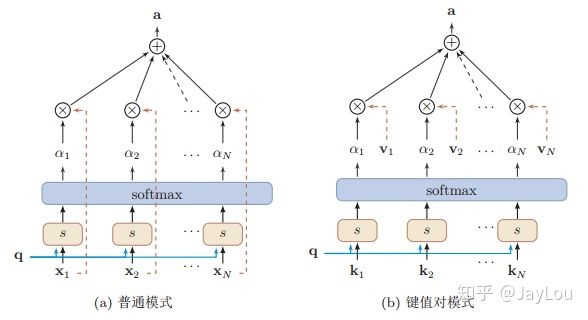
- $\begin{aligned} \operatorname{att}((K, V), \mathbf{q}) &=\sum_{i=1}^{N} \alpha_{i} \mathbf{v}{i} \ &=\sum{i=1}^{N} \frac{\exp \left(s\left(\mathbf{k}{i}, \mathbf{q}\right)\right)}{\sum{j} \exp \left(s\left(\mathbf{k}{j}, \mathbf{q}\right)\right)} \mathbf{v}{i} \end{aligned}$
hard-attention :-> 直接精准定位到某个 key,其余的 key 不管,单个样本 query 仅对单个 key 进行相似度计算,得到 m*1 的 attention score
local-attention :-> hard定位单个key,以这个 key 为中心取周围区域,计算各个窗口的 soft-attention,得到 m*k 的 attention score
按所用信息general-attention :-> 利用外部信息,用于构建两段文本之间关系的任务
[[self-attention]] :-> 只使用内部信息,寻找原文内部的关系。
按使用模型CNN 是基于 N-gram 的局部编码,RNN 由于梯度消失问题也只能建立短距离依赖。
解决上面的问题有两种方法:利用深层神经网络来获取远距离的信息交互或者是使用全连接网络。
[[LSTM]] 对所有 step 的 hidden state 进行加权,注意力集中到整段文本中比较重要的 hidden state 信息。
[[Attention 按 QKV 划分]]
注意力计算方式 Neural Machine Translation by Jointly Learning to Align and Translate
Ref