self-attention
不同部分作用
- query :-> 与 key 计算相似度,为自身的输出 i 建立权重
- key :-> 与 query 计算相似度,建立第 j 个向量 j 的权重
- value :-> 作为加权总和的一部分,计算每个输出向量
对自身 $$X$$ 线性变化得到 $$Q=W_QX, K=W_KX, V=W_VX$$,用来捕获同一个句子中单词之间的一些句法特征或者语义特征。
注意力计算
- $$\begin{aligned} \mathbf{h}{i} &=\operatorname{att}\left((K, V), \mathbf{q}{i}\right) \ &=\sum_{j=1}^{N} \alpha_{i j} \mathbf{v}{j} \ &=\sum{j=1}^{N} \operatorname{softmax}\left(s\left(\mathbf{k}{i}, \mathbf{q}{i}\right)\right) \mathbf{v}_{j} \end{aligned}$$
打分函数 $${H=V softmax(\frac{K^TQ}{\sqrt{d_3}})}$$
过程
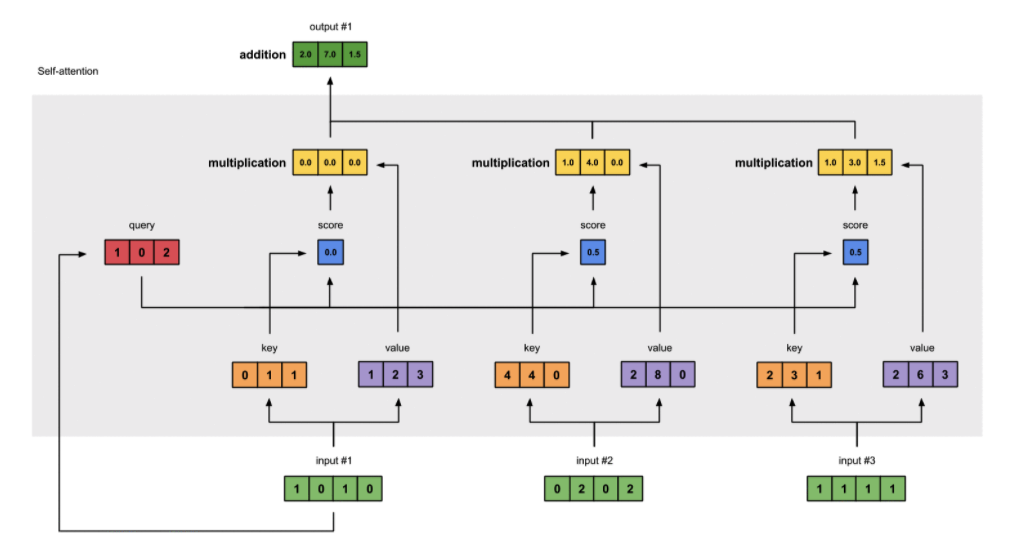
为什么 self-attention 先对 embedding 进行 dense 层映射,然后再进行 attention 计算?
dense 层 #card
W 为自注意力层提供一些可控制的参数,允许输入的向量适合 QKV 的功能。
qkv 的大小,实现降维。
多头机制作用 :-> 每一个头对应的 wq、wk、wv 矩阵都不同,对模型的本身特征抽取的多样性具有帮助。
为什么不能直接做 attention 计算?原始 embedding 空间点击建模 :-> 语义关系
点积建模语义的问题 :-> 默认假设语义相近的注意力更高, VVV 中自己对自己的注意力权重永远最高
- 结果 :-> 其他位置上有关系的注意力相关性就会被弱化。
进行变换后的点积含义
- 新空间点积 :-> 表示注意力高,但不代表语义相似度高。
- 好处 :-> 能在新空间里更加专注于注意力的学习。
- 新空间点积 :-> 表示注意力高,但不代表语义相似度高。
一个词在做 query、key、value 时,直觉 :-> 有不同的表示
为什么 self-attention 中的词向量要乘以 QKV 参数矩阵?
- self-attention 核心利用 文本中的其它词 来增强 目标词的语义表示
- 不乘以 QKV 矩阵 :-> qkv 完全一样,qi 和 ki 的点积比重会最大,无法有效利用上下文信息来增强当前词的语义表示。
- QKV 参数矩阵使得多头作用 :-> 类似于 CNN 中的多核,使捕捉更丰富的特征/信息成为可能
现在看来self-attention 是增强了模型表示能力,还是有了更好的对特征的权重加权? - 知乎 :-> 增强模型表达能力 - 增强模型表达能力 :-> 加权对象是 token,融合不同的 token 来构造当前 token 在当前上下文情况下的表示
- 如果是对特征进行加权, :-> 初始化的 word embedding应该直接用那些预训练好的,实际上预训练的词向量并不会提高模型收敛后的效果。
Ref
关于attention机制的一些细节的思考 - 知乎 (zhihu.com)
- 为什么 self-attention 先对 embedding 进行 dense 层映射,然后再进行 attention 计算?