@LiRank: Industrial Large Scale Ranking Models at LinkedIn
想法
- 主要是工程实践经验,完全覆盖搜广推系统的方方面面。如果没有遇到过相关的问题,看起来完全是天书。当成是手册查询吧。
Large Ranking Models
[[3.1 Feed Ranking Model]]
[[3.2 Ads CTR Model]]
[[Dense Gating and Large MLP]]
[[3.6.Incremental Training]]
[[3.7 Member History Modeling]]
[[3.8 Explore and Exploit]]
[[3.9 Wide Popularity Features]]
[[3.10 Multi-task Learning]]
[[3.11 Dwell Time Modeling]]
[[3.13 Embedding Table Quantization]]
Training scalability
[[4.1 4D Model Parallelism]] 解决训练过程中 embedding 表梯度同步存在性能瓶颈
[[4.2 Avro Tensor Dataset Loader]] 解决训练过程中 io 瓶颈
[[4.3 Offload Last-mile Transformation to Asynchronous Data Pipeline]] 优化训练过程
[[4.4 Prefetch Dataset to GPU]] 预取数据到 GPU
Experiments
[[5.1. Incremental Learning]]
- 两个场景增量学习效果
[[5.2 Feed Ranking]]
- 通过 replay metric 评估 3 中策略的效果
[[5.3 Jobs Recommendations]]
[[Jobs Recommendations Ranking Model Architecture]]
验证 [[3.12 Model Dictionary Compression]] 压缩方法没有任何性能损失
[[Dense Gating and Large MLP]] 并没有改进
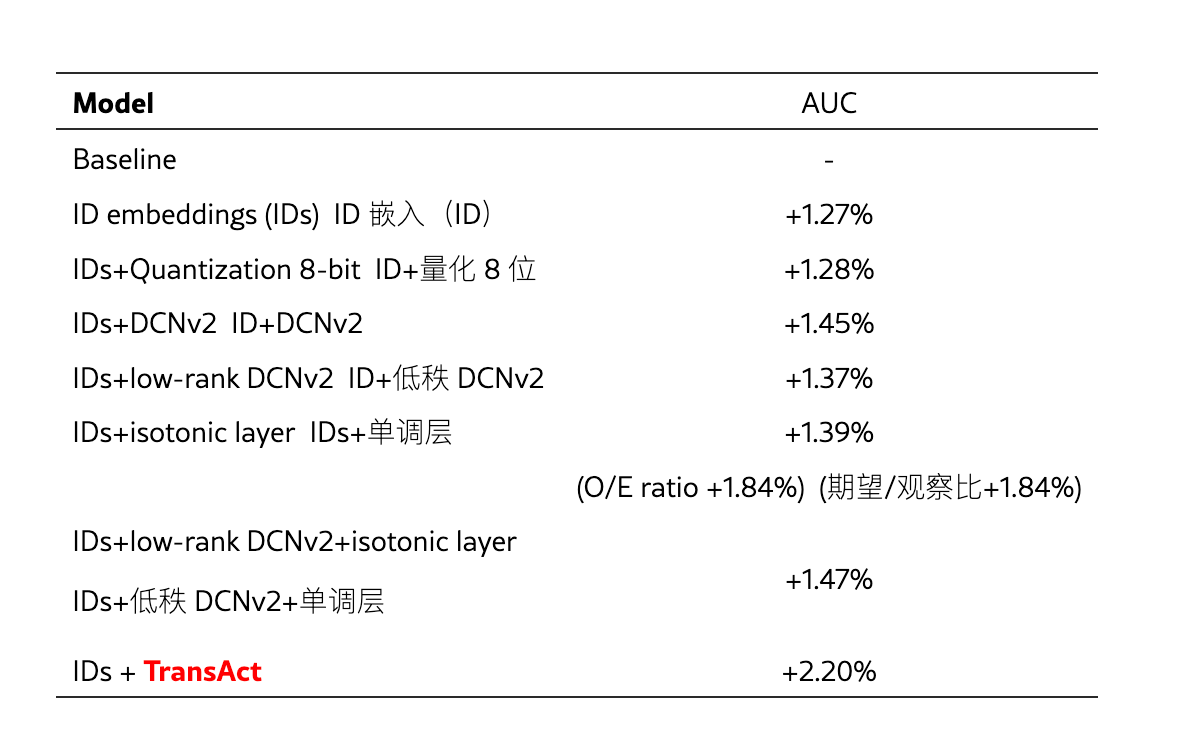
5.4 Ads CTR
- 效果 #card
- 基线 GDMix model
- 效果 #card
6 Deployment Lessons
6.1 Scaling up Feed Training Data Generation
- 没太看明白,感觉是优化性能实现用 100% sessions 进行训练
6.2 Model Convergence
- [[DCNv2]] 初始训练不收敛 #card
对数值输入特征应用批量归一化,在当前训练步数下存在欠拟合,但是增加训练步数会导致实验速度下降。
增加 warm-up steps 稳定训练,且可以使用三倍学习率
- [[DCNv2]] 初始训练不收敛 #card
@LiRank: Industrial Large Scale Ranking Models at LinkedIn