@重排序在快手短视频推荐系统中的演进
链接:渠江涛:重排序在快手短视频推荐系统中的演进 (qq.com)
想法
- 值得一看,混排强化学习那部分设计还不是很熟悉
- 端上重排,如何拆分模型部署在服务器和端上
摘录
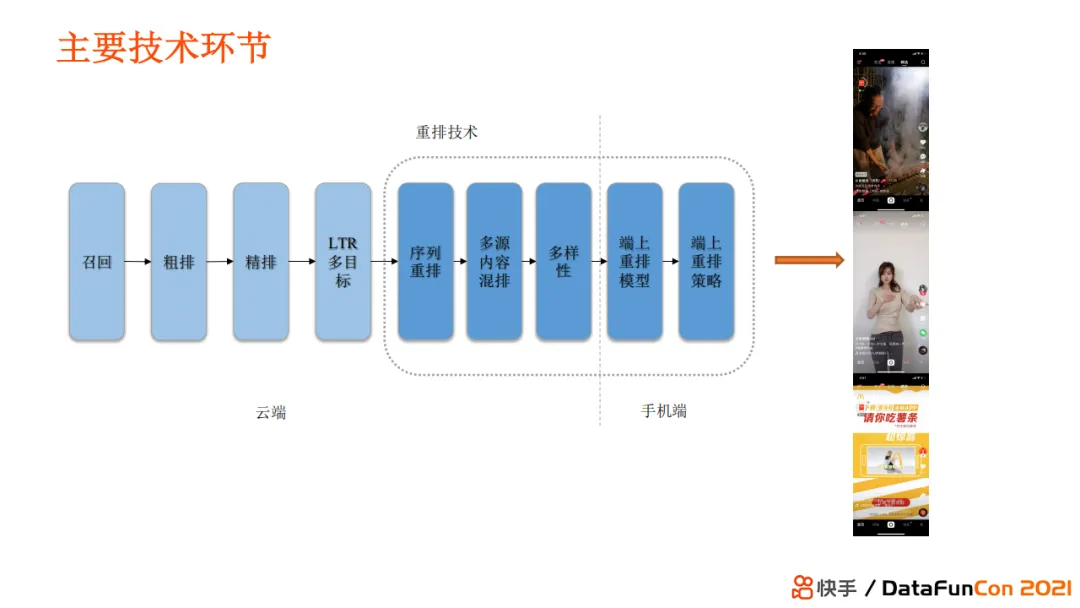
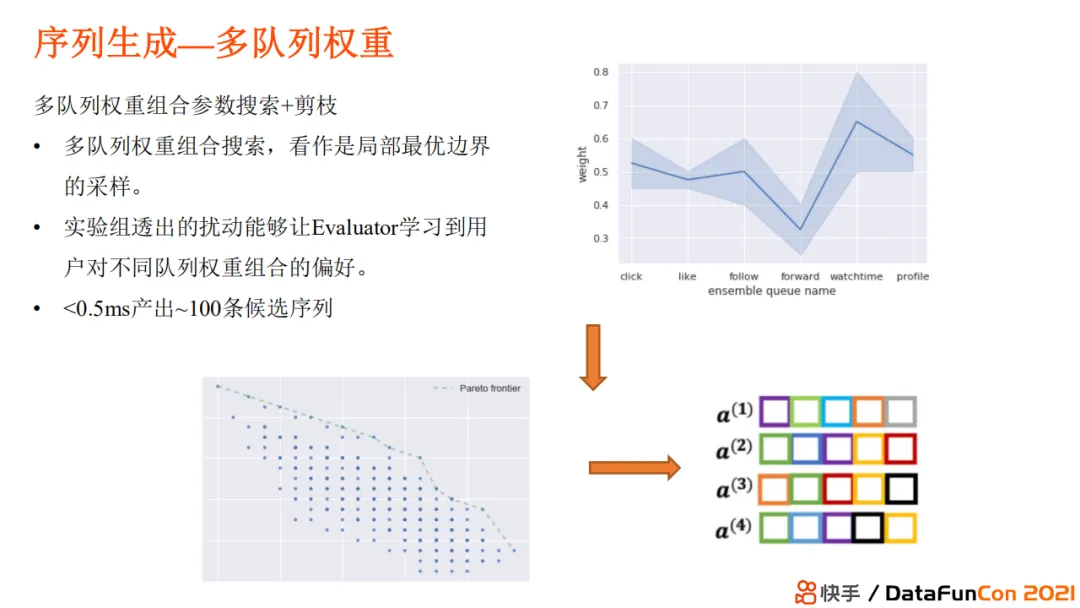
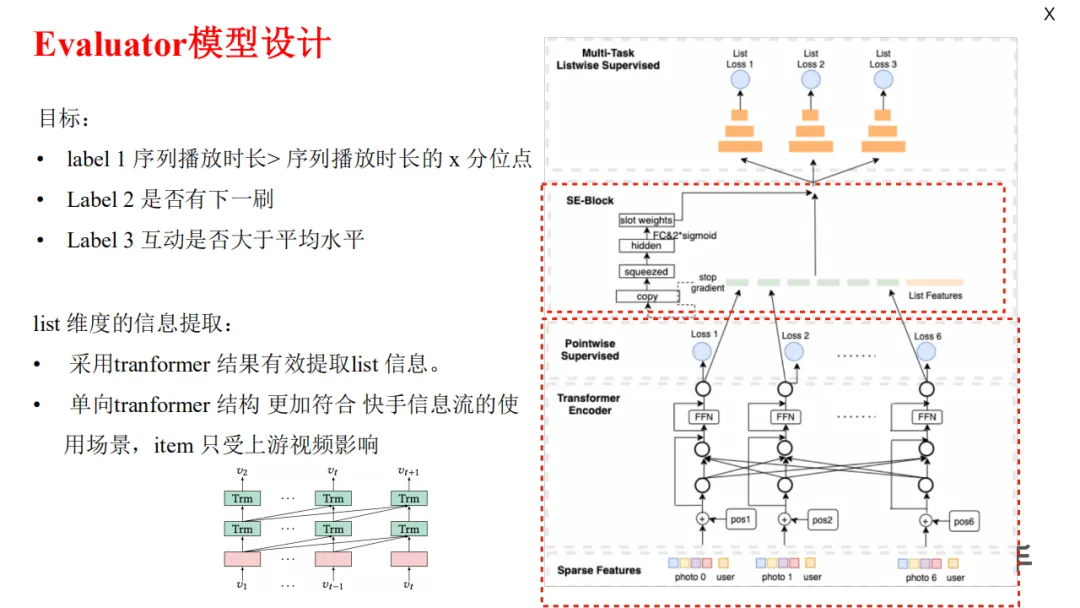
+ #### [[Evaluator]]
+ 三个业务目标
+ 单向 Transformer (用户自上而下刷视频,下游视频对上游视频没有增益),也可以降低复杂度,提升模型稳定性。
+

+ base 方案的问题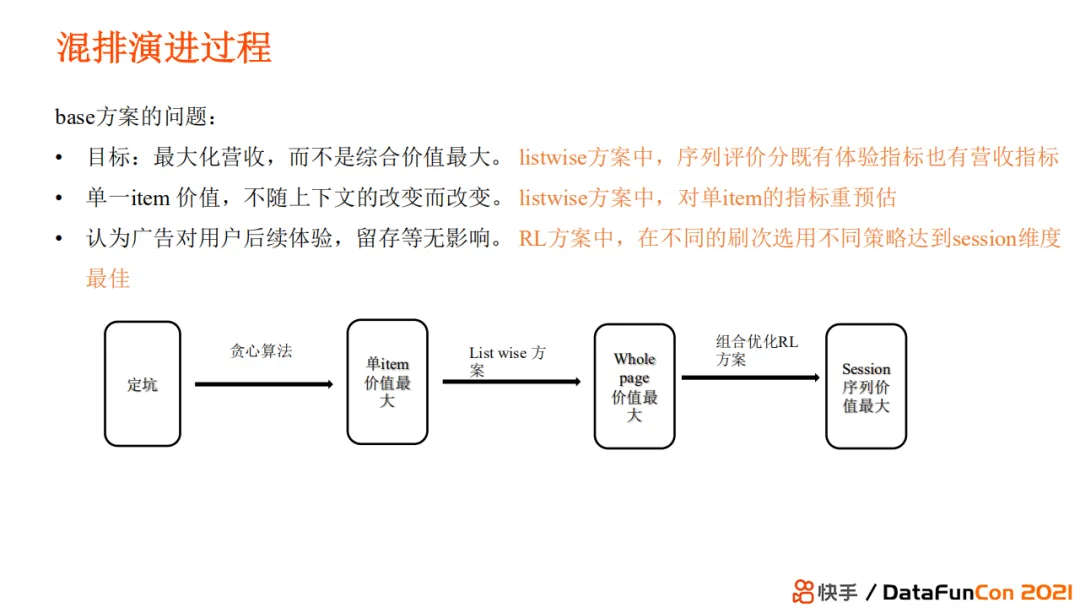
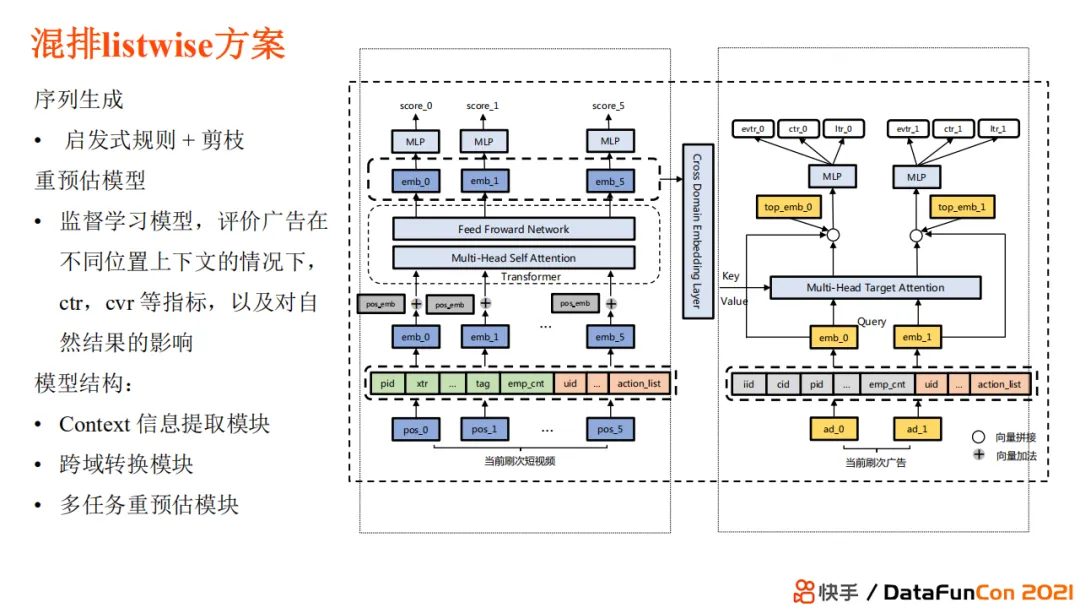
+ #### 混排 listwise 方案
+ 跨域转化模块,广告和自然内容是跨域的
+ 广告内容多任务预估,利用左侧短视频信息和 context 信息校准广告 ctr 和 cvr 等指标
+ #### 混排 RL 方案
+ 目标:长期体验和近期收入平衡
+ 状态、动作、回报

+ [[Dueling DQN]]
+ 首先,V网络评估用户当前的满意程度,这使得模型可以在不同的用户状态下选择不同的放置策略。但由于放置策略十分离散,它的解空间相当大,那么我们需要对离散空间 dense 化。
+ 我们的 dense 化不是通过模型去做的,而是通过之前使用的重预估监督模型来实现。通过监督模型,我们就可以知道这个 action 下每个位置放置的内容可以带来多少的用户体验和商业价值。
+ 之后,我们可以使用一个神经网络对不同的 action 进行打分。
+ 我们的优化目标是每一步选择能够达到最终的总和价值最大,reward 是长期价值和近期价值的组合。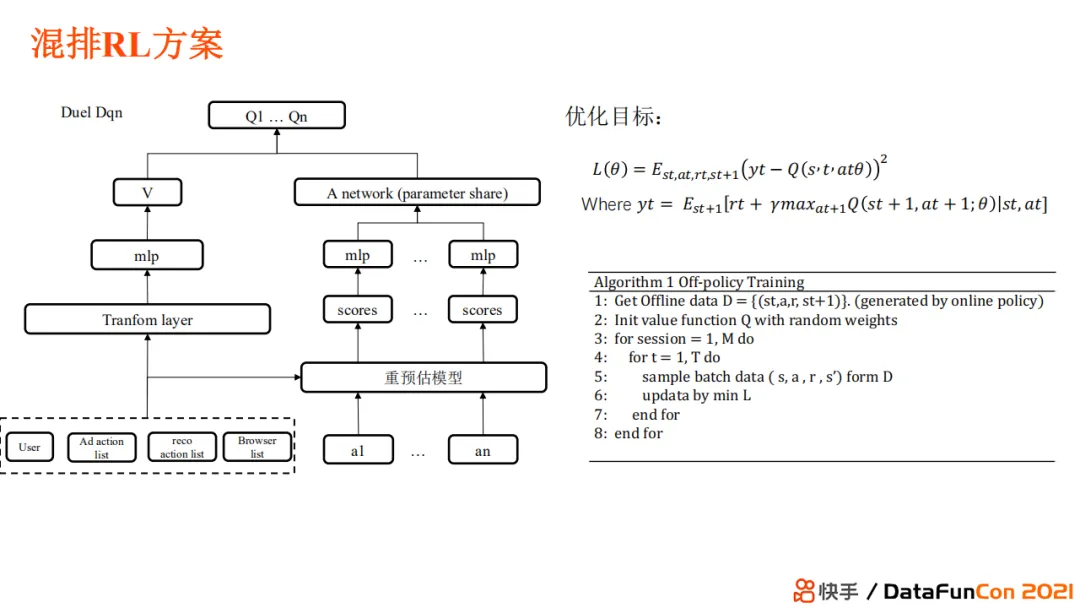
+ 两段式训练范式
+ 首先,使用 online policy 的方式,先将模型部署上线生成 online policy 下的数据,作为 off policy 的训练数据放入回放池。
+ 之后,使用 off policy 来训练 Dqn 模型。
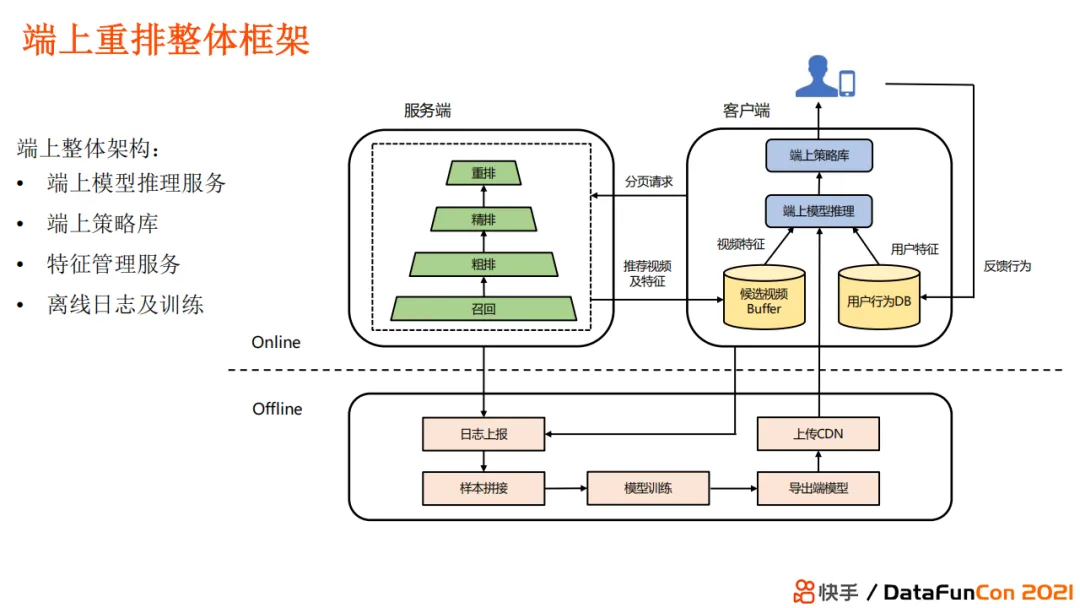
+ #### 千人千端
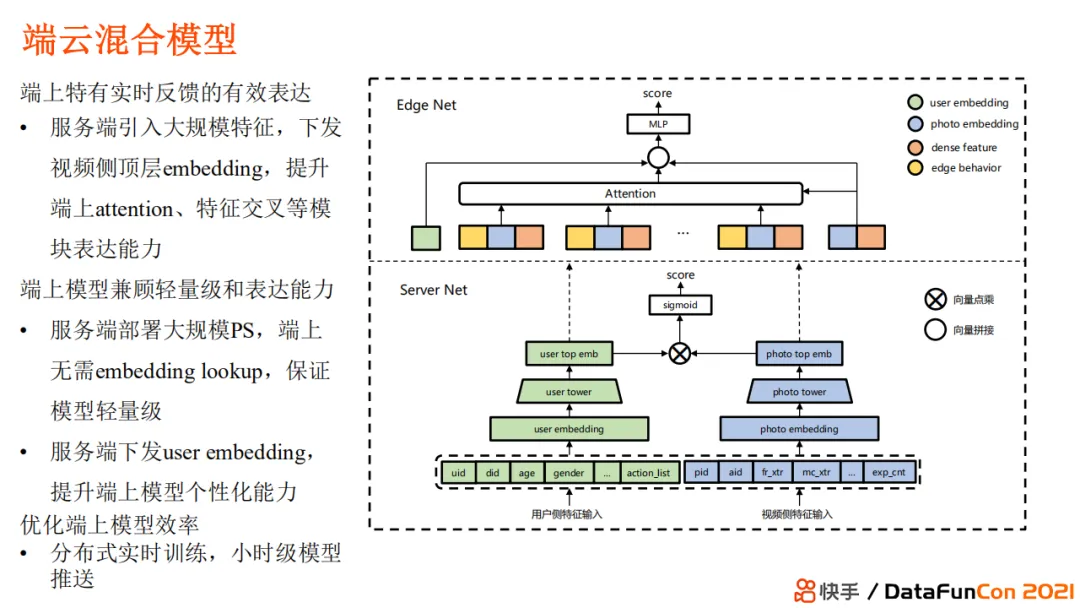
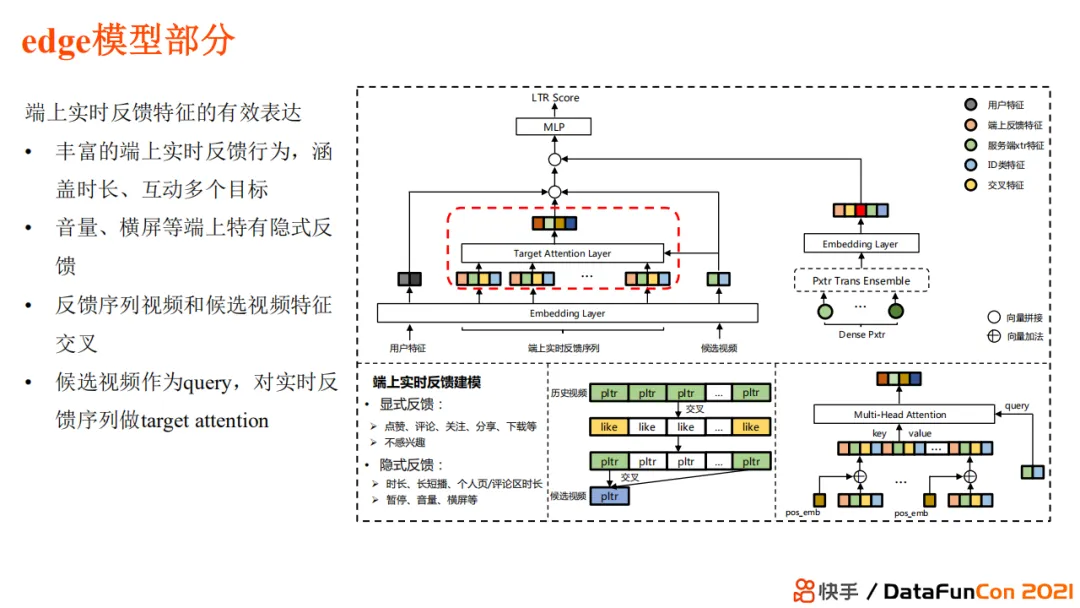
+
Ref
- 读《重排序在快手短视频推荐系统中的演进》有感 - 知乎 (zhihu.com) 评论区 qujt08 感觉是快手员工?
@重排序在快手短视频推荐系统中的演进
https://blog.xiang578.com/note/wx_OTyEbPCBh1NHogPM7bBtvA.html