@didi food中的智能补贴实战漫谈
滴滴国际化外卖团队的文章,前几个月做补贴关业务的时候看过。文章链接:https://mp.weixin.qq.com/s/WU1iILMFdH3RZAbJKFU4WA
补贴问题和其他机器学习问题最核心和最关键的不同点是补贴行为需要付出成本,一般用 ROI 来评估增加补贴成本带来的增量指标收益。
智能补贴问题拆解
- 预估干预 action 相比没有干预带来的增量
- 建模 [[UPlift Model]]
- [[Meta Learning]] 主要思想通过一些基模型的组合,去近似你和一个无法被观测到的增量
- [[Two Model]] 差分模型,利用两个模型的差值去近似用户的增量
- [[Single Model]] 将与干预手段 w 有关的特征加入训练,只建立一个模型。
- 利用样本特征、label、干预 w 训练一个模型
- 预测时将特征赋值 w=1 和 w=0 计算用户增量 $\hat{\tau}(x)=\hat{\mu}(x, W=1)-\hat{\mu}(x, W=0)$
- [[X-Learner]] 利用观察到的样本结果去预估未观察到的样本结果的思想,对增量进行近似,同时还会对结果进行倾向性权重调整,以达到优化近似结果的目的。
- [[R-Learner]] 通过 Robinson’s transfomation 定义一个损失函数,然后通过最小化损失函数的方法达到对增量进行建模的目的。
- tree-base 通过树模型中节点分类的算法思想,尝试直接对增量建模,预测增量。
- 主要思路,通过对特征点进行分裂,将X划分到一个又一个subspace中,这与补贴场景下,希望找到某一小部分增量很高的用户的想法几乎是完美重合。
- [[Uplift Decision Tree]] 分裂规则
- $\Delta_{\text {gain }}=D_{\text {after }}\left(P^T, P^C\right)-D_{\text {before }}\left(P^T, P^C\right)$
- [[Contextual Treatment Selection]] 直接最大化每个节点上实验组和对照组之间label期望的差值(可以理解为该节点上样本的Uplift值)
- [[Meta Learning]] 主要思想通过一些基模型的组合,去近似你和一个无法被观测到的增量
- [[Uplift Model 评估]]
- [[Qini curve]]
- [[AUUC]]
- 建模 [[UPlift Model]]
- 分配策略:存在多种干预 action 和已预估了他们 增量 的情况下,如何为每个用户合理分配 action 以期望达到全局最优
- 贪心分配
- 根据运营规则计算每个类别券的可支配数量
- 用户按计算出的 uplift 值倒排,按可以发放券的数量截断。
- 同一个用户如果在多个券的 uplift 都比较高,优先发比较低的券
- 整数规划
- 参数含义
- $x_{i,j}$:是否对用户 i 发 j 券
- $p_{i,j}$ 增量模型预估用户 i 在 j 券下的增量
- $t_{i,j}$ 转化率模型预估用户 i 在 j 券下的转化率
- 优化目标
- $\max \left(x_{1,1} t_{1,1}+x_{1,2} t_{1,2}+x_{1,3} t_{1,3}+x_{1,4} t_{1,4}+\ldots+x_{n, 1} t_{n, 1}+x_{n, 2} t_{n, 2}+x_{n, 3} t_{n, 3}+x_{n, 4} t_{n, 4}\right)$
- 问题约束
- 用户只能拿到一张券
- $\left{\begin{array}{l}x_{1,1}+x_{1,2}+x_{1,3}+x_{1,4}=1 \ \cdots \ x_{n, 1}+x_{n, 2}+x_{n, 3}+x_{n, 4}=1\end{array}\right.$
- $\left{x_{1,1}, x_{1,2}, x_{1,3}, x_{1,4}, \ldots, x_{n, 1}, x_{n, 2}, x_{n, 3}, x_{n, 4}\right} \in{0,1}$
- 总资金约束
- $x_{1,1} p_{1,1} c_{1,1}+x_{1,2} p_{1,2} c_{1,2}+x_{1,3} p_{1,3} c_{1,3}+x_{1,4} p_{1,4} c_{1,4}+\ldots+x_{n, 1} p_{n, 1} c_{n, 1}+x_{n, 2} p_{n, 2} c_{n, 2}+x_{n, 3} p_{n, 3} c_{n, 3}+x_{n, 4} p_{n, 4} c_{n, 4} \leq B$
- 用户只能拿到一张券
- 参数含义
- 贪心分配
实验设计
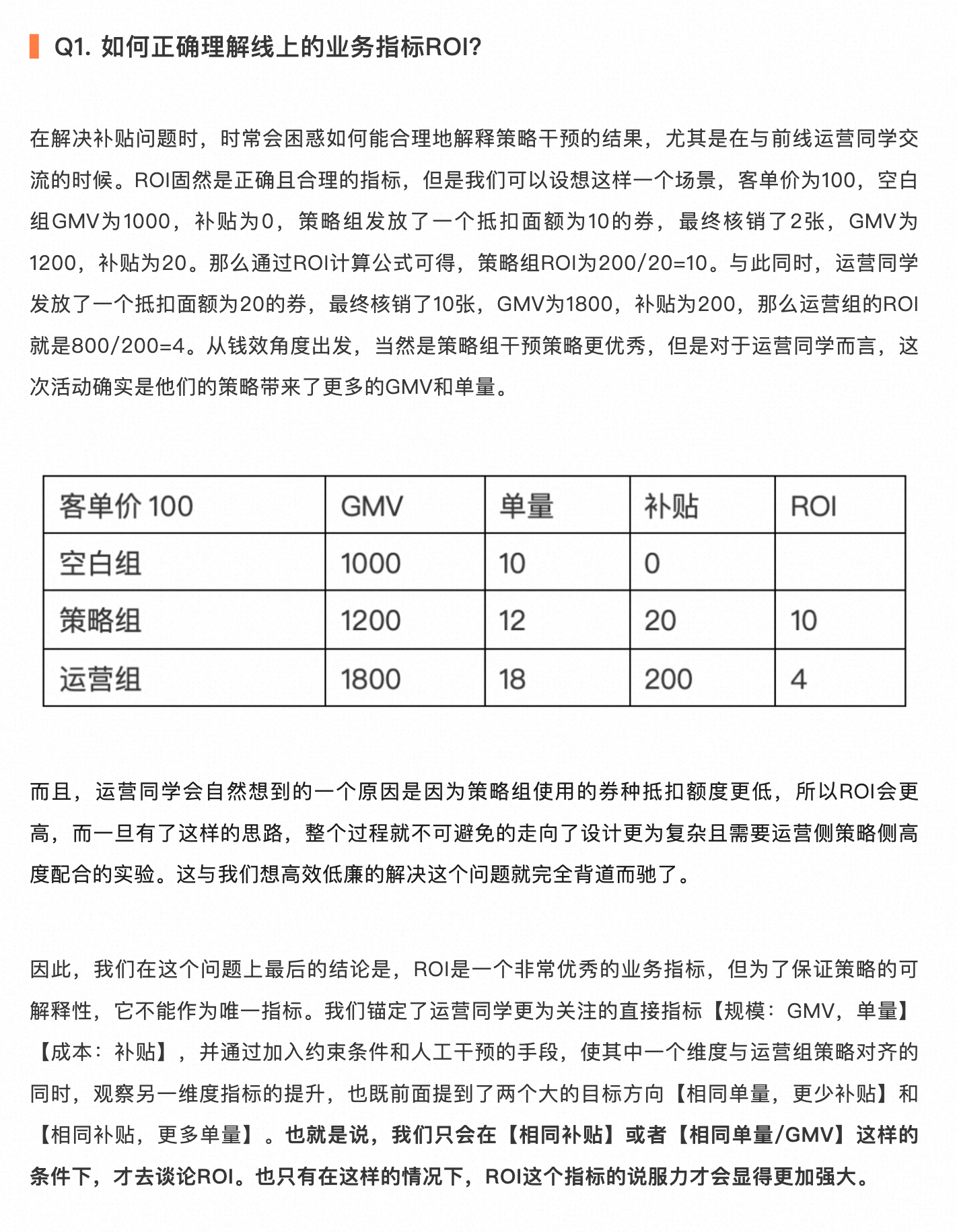
- 作者做了两组实验,来分别验证不同业务目标。(相同补贴或者相同单量/GMV 条件下,对比 ROI 才有意义)
- 相同单量,更少补贴
- 相同补贴,更多单量
后续规划
- 整数规划与强化学习理论结合的可能性
- 当前方法是针对每一次活动求得全局的最优化,实际需要对用户长期价值 [[LTV]] 建模。
问题
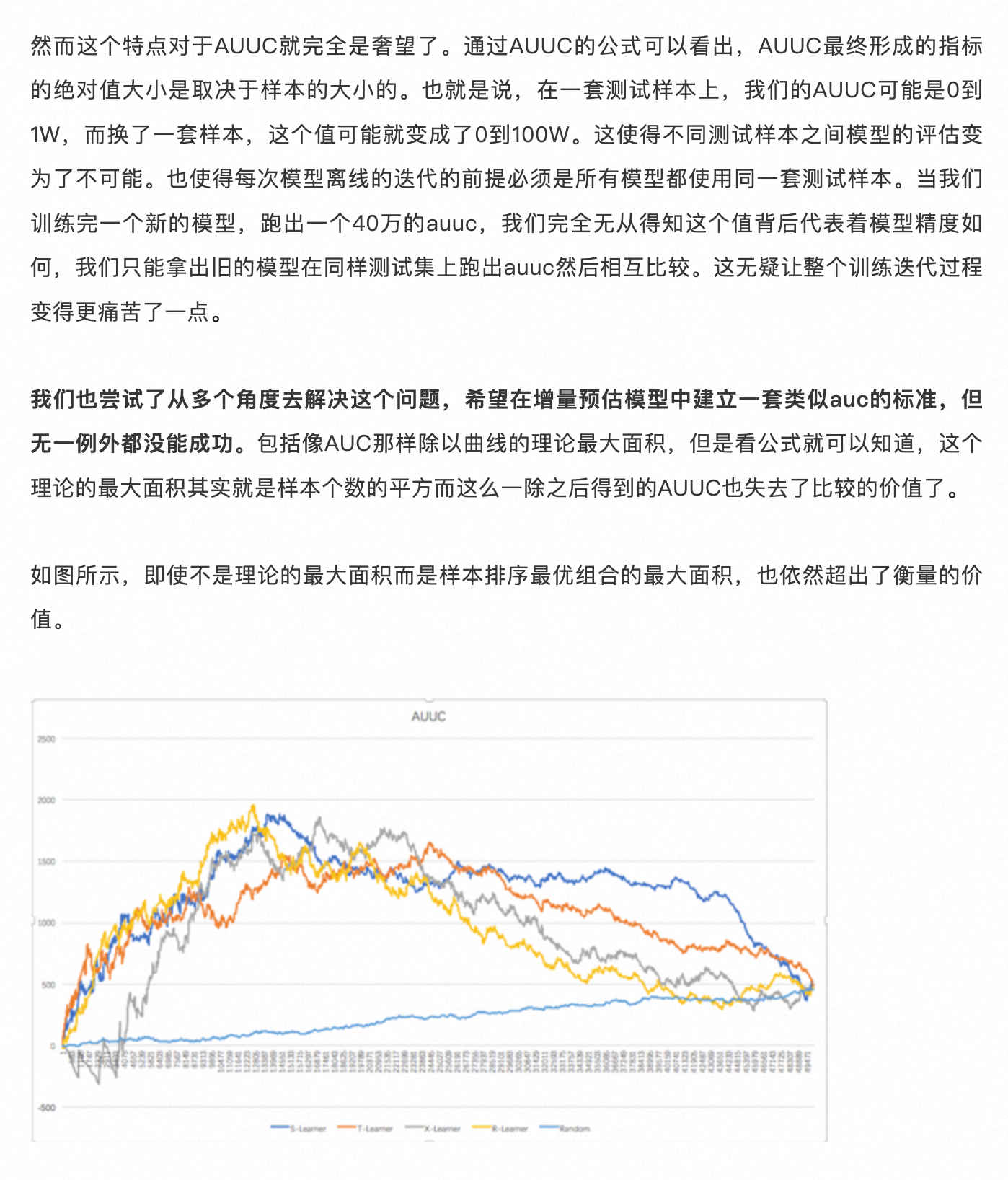
如何理解离线指标 [[AUUC]]
- [[AUC]] 不同范围含义
- 0.5 随机线
- 0.6 模型还需要迭代
- 0.6-0.8 模型上线标准
- 0.9 模型是否过拟合或是否有未知强相关特征参与模型训练
- 补贴问题本身就是与实验批次和样本强相关的问题,很难在增量预估模型中建立一套类似 auc 的标准
- [[AUC]] 不同范围含义
@didi food中的智能补贴实战漫谈