X-Learner
[[X-Learner ppt]]
X-Learner 基于 T-Learner 而改进点 #card
一是针对当干预组样本较少时 T-learner 预测不准,
二是针对 S/T-Leaner 都不是直接预测因果效应。
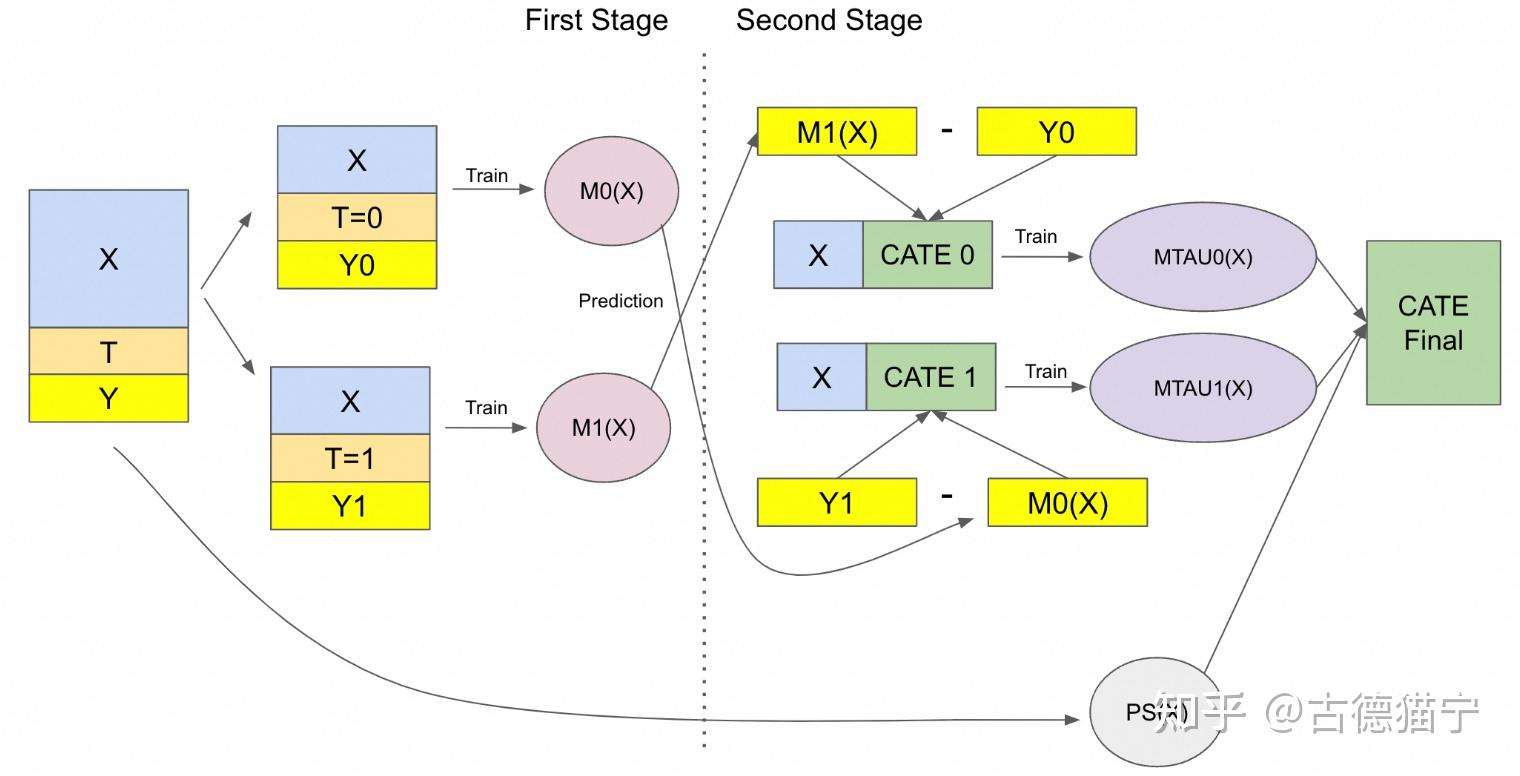
分为两个阶段:
X-Learner第一阶段#card
和 T-Learner 一样,将控制组样本和干预组样本分别用于训练模型 $M_0$ 和 $M_1$ ,
分别学习 $M_0(X) = E(Y|T=0,X)$ 和 $M_1(x) = E(Y|T=1,X)$
X-Learner 第二阶段#card
基于 和 $M_0和M_1$ 分别交叉(X 的由来)预测干预组和控制组样本的反事实结果,与事实结果的差值就是样本的因果效应,此时就可以用控制组和干预组的样本分别训练 CATE 预估模型 $M_{\tau0}(X)$ 和 $M_{\tau1}(X)$ ,
最终的 CATE 估计是两者的融合 $\hat{\tau}(x)i = M{\tau0}(x)g(x) + M_{\tau1}(x)(1-g(x) )$ ,对于权重函数 $g(x)$ 一种选择是[[倾向性评分]]函数 $e(x)$ ,当干预组样本量远大于控制组时也可以取 1 或 0。
通过与实际结果差分计算增量
用有干预模型预测无干预群体的有干预结果,无干预组近似增量 $D_0=\hat{\mu}_1\left(X_0\right)-Y_0$
用无干预模型预测有干预群体的无干预结果,有干预组近似增量 $D_1=Y_1-\hat{\mu}_0\left(X_1\right)$
根据增量建立两个模型,对增量建模可以引入相关先验知识提升模型精度
$\hat{\tau}_0=f\left(X_0, D_0\right)$
$\hat{\tau}_1=f\left(X_1, D_1\right)$
引入 [[倾向性评分匹配]]PSM 加权得到最后提升评估结果
- $\begin{aligned} & e(x)=P(W=1 \mid X=x) \ & \hat{\tau}(x)=e(x) \hat{\tau}_0(x)+(1-e(x)) \hat{\tau}_1(x)\end{aligned}$
优点#card
适合实验组和对照组样本数量差别较大场景
增量的先验知识可以参与建模,引入权重系数,减少误差
缺点#card
- 多模型造成误差累加