@多目标排序在快手短视频推荐中的实践
链接:多目标排序在快手短视频推荐中的实践 (qq.com),郑东,快手推荐算法技术总监
想法
- 分享主要内容是排序机制和重排,还看不太懂。
摘录
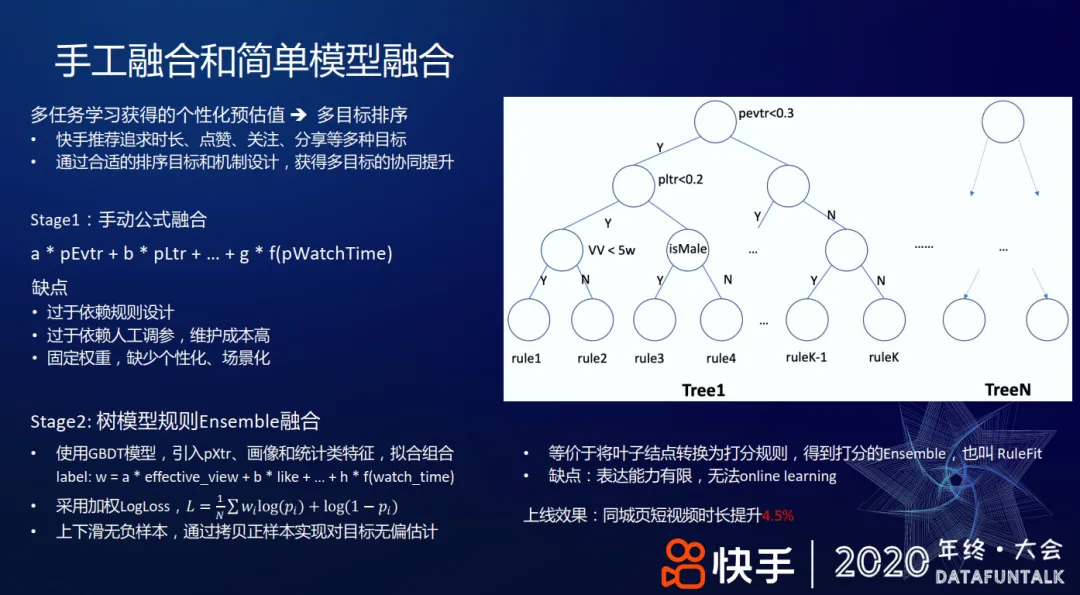
+ #### 超参 Learn To Rank #card
+ dnn 拟合组合收益,通过学习线性加权的超参数去拟合最终组合收益
+ photo_top,24维,各种个性化预估值
+ user_top,24 维,用户特征(比如对用户划分不同的时间窗口:过去1分钟、5分钟、15分钟、...、2小时,每个时间窗内,对推荐给他的视频,根据用户的反馈拼接成一个向量,这些反馈包括有效播放、点赞、关注、分享、下载、观看时长等,最后,将各时间窗口对应的反馈向量和ID类特征一起输入到用户侧网络。)

+ #### 端到端Learn To Rank
+ pointwise 更复杂特征和网络结构,#card
+ 模型表达力更强。
+ pairwise #card
+ 样本构造,一次请求 6 个视频,针对每个目标都构造偏序对
+ dnn 打分,sigmoid 变换,交叉熵损失产出 loss
+ $\begin{gathered}s_{i j}=\sigma\left(s_i-s_j\right) \\ \operatorname{loss}{ }_{l i k e}^{i j}=y_{i j} \cdot \log \left(s_{i j}\right)+\left(1-y_{i j}\right) \log \left(1-s_{i j}\right)\end{gathered}$
+ 不同目标 loss 线性加权,从而兼顾多个目标的权重
+ 效果上看做对不同目标的 auc 加权求和,auc 本质上是一个偏序的关系。
+
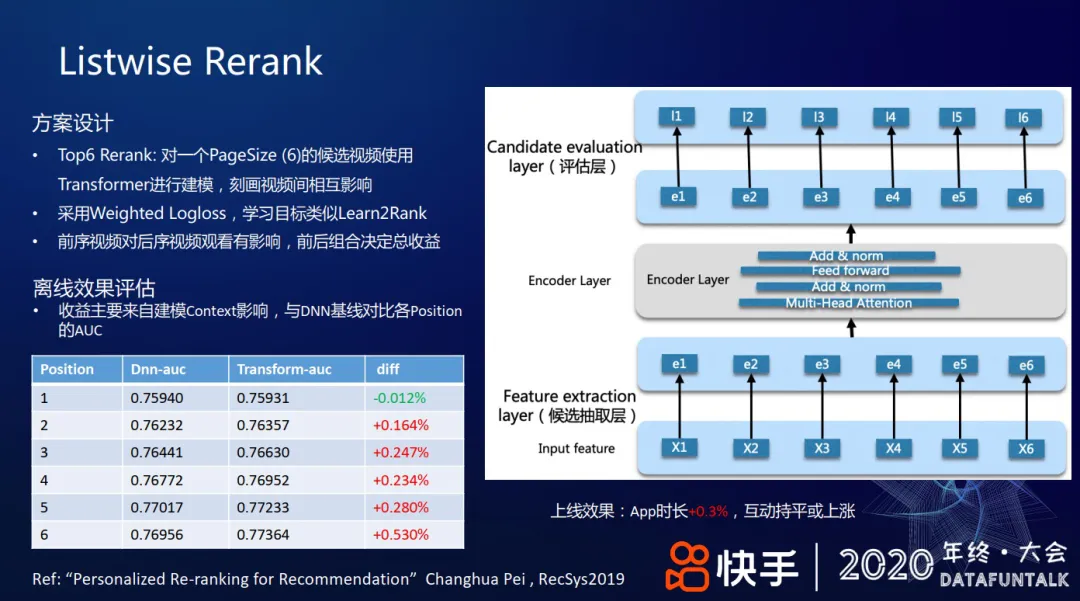
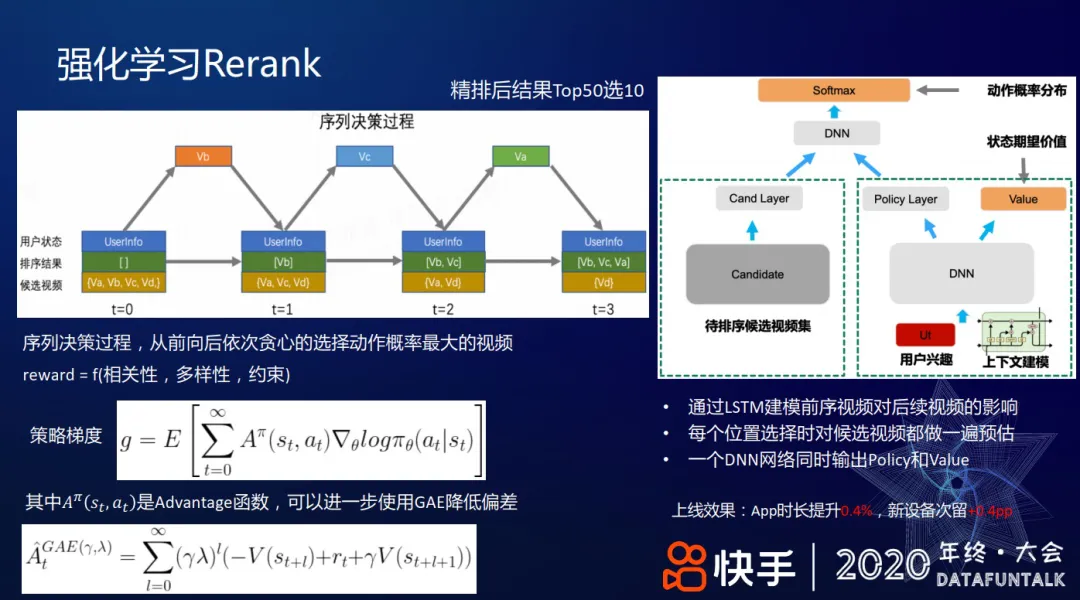
+ #### 强化学习 Rerank
+ 贪心选择,LSTM 建模前序特征
+ 策略梯度, [[GAE]]
+ 使用仿真器训练
+ on-policy 训练更加稳定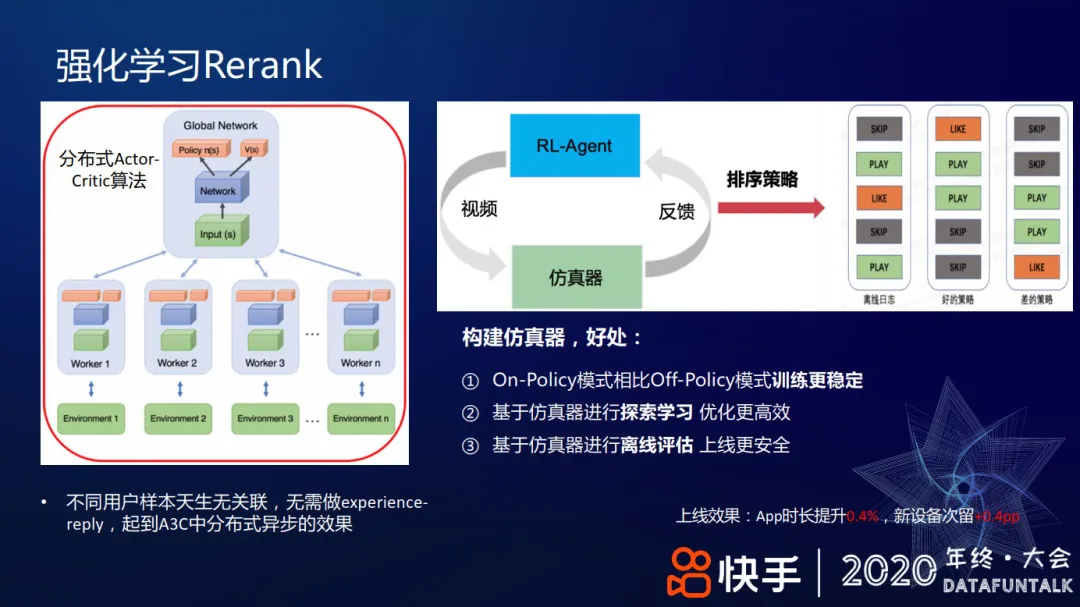
+ #### [[端上重排]]
+ 端上网络结构使用 [[TFLite]]
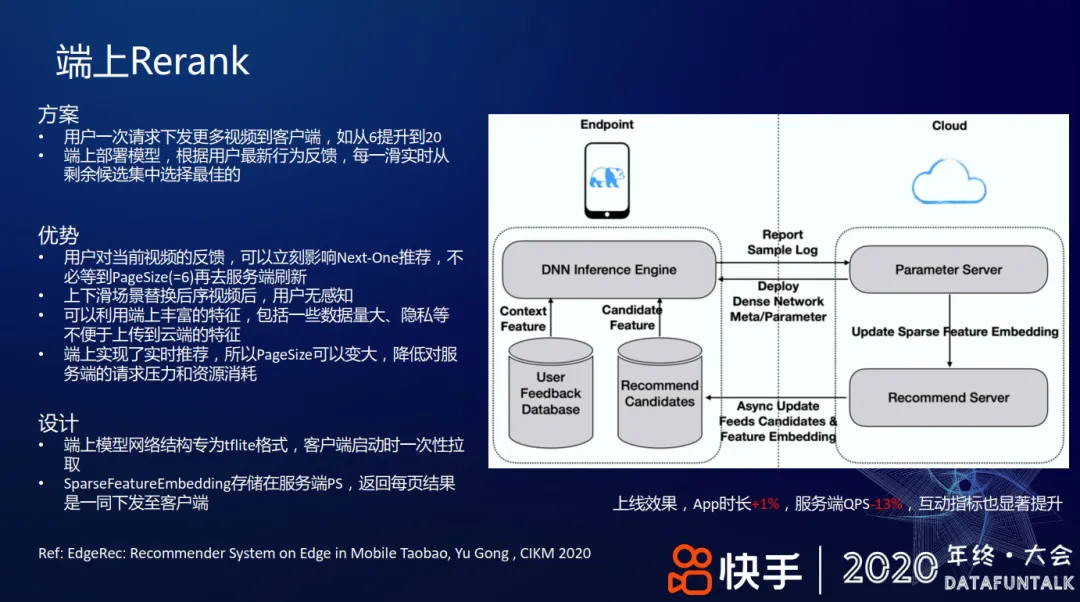
+ 模型特征和结构
+ Transformer 建模用户实时反馈和各种序列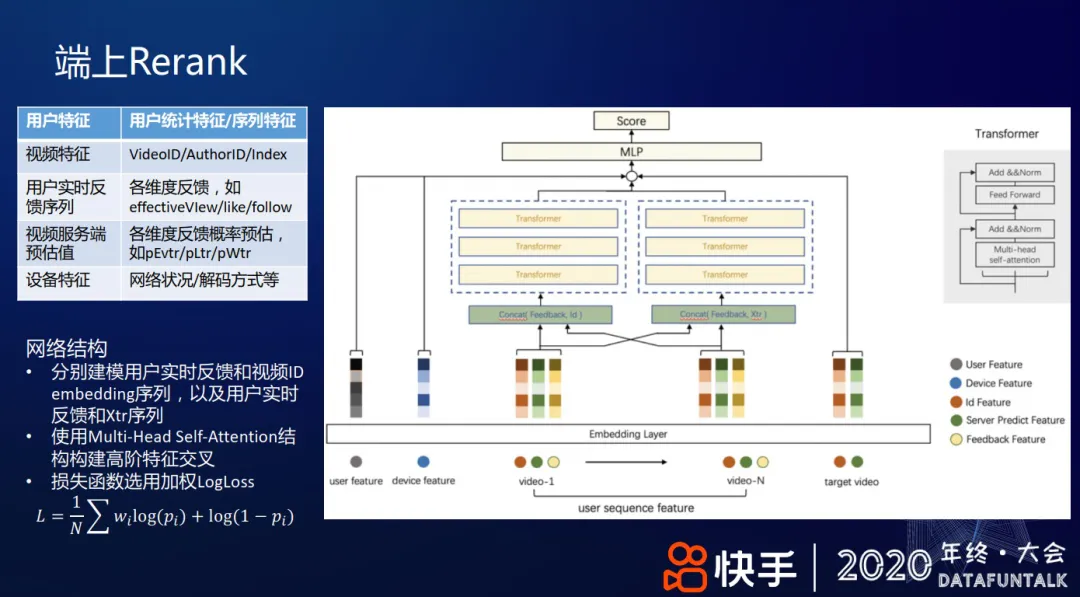

@多目标排序在快手短视频推荐中的实践