@基于超网络的实时可控重排模型
链接:淘宝推荐场景的利器:融合复杂目标且支持实时调控的重排模型 如何灵活调节多目标之间的权重。
对应论文:[[2023]] Controllable Multi-Objective Re-ranking with Policy Hypernetworks
摘录
动机
- 强化学习的 reward function 由多个指标线性加权求和得到,加权参数 w 代表对各个目标之间的倾向。
- 动态指定 preference weights,给定任一一个 w,都能生成最好的序列。
- 准备多套 w,对应不同的业务目标。

方法
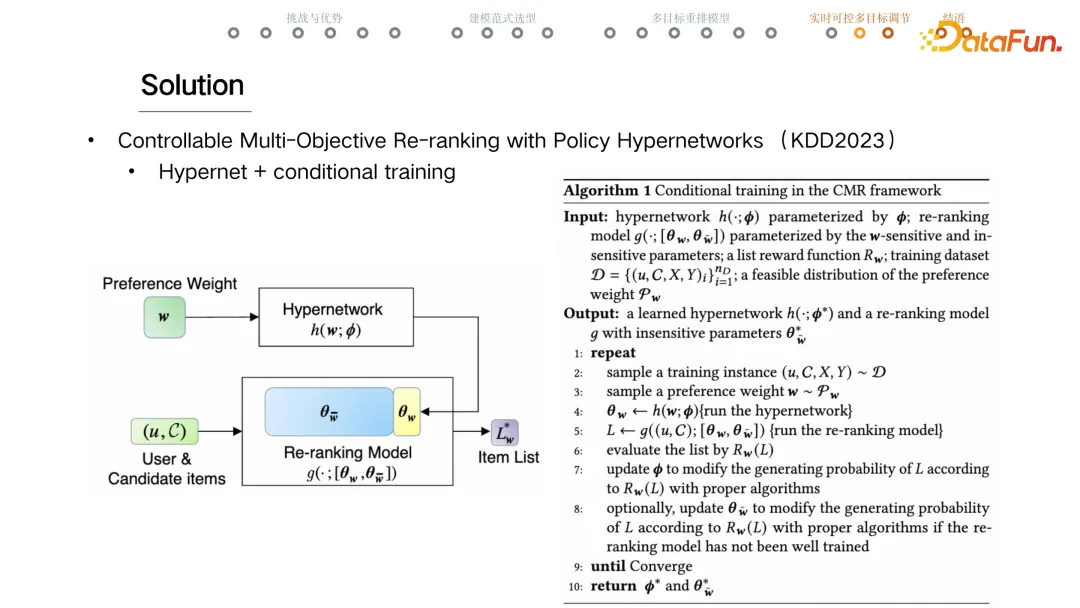
- 核心 Hypernet 和 conditional training
- 预测
- 根据用户 和 candidate item 信息实时指定 w,Hypernetwork 根据 w 生成参数给重排模型(DNN 最后几层的 w 和 b)。
- 图中重排模型黄色参数对 w 敏感,蓝色参数对 w 不敏感。
- 训练
- 每一个 sample 或 batch 从事先指定的 distibution 中随机采样一个 w。
- 重排模型生成序列给 evaluator 评估,reward 转化成一个 gradient,同时更新 hypernet 和重排模型相关的参数。
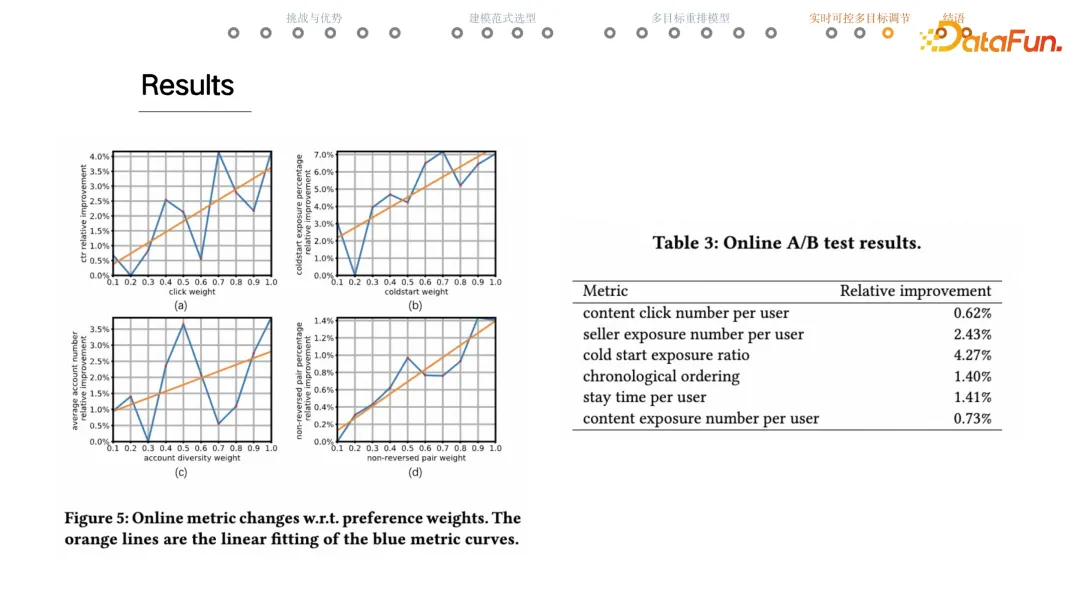
结果
- a
- x 轴点击 utility 的权重,y 轴是线上真实回收出来的样本的点击平均值。
- 蓝色折线真实值,橙色一次拟合。
- utility 权重增大,点击率明显上升。重排模型能够依据给定的 w 生成不一样的序列。
- b 冷启内容占比
- c 店铺多样性
- d 组间排序的 utility,表示来自不同 group 的内容,大致要按照 group 的优先级排序。
- 右边是 ab 结果,实验方案线上超参调节,指标有提升。
- a
@基于超网络的实时可控重排模型