召回双塔和排序双塔的区别
相同点 #card
训练时,都需要用户塔、物料塔隔离,解耦建模。不允许使用Target Attention这样的交叉结构,也不允许使用“用户与当前物料在标签上的重合度”之类的交叉特征。
部署时,得益于双塔解耦的结构,面对一次用户请求,用户向量都只需要生成一遍。而物料向量都可以离线生成好,缓存起来,被不同的用户请求复用。
区别
部署时物料向量存储方式 #card
由于召回的候选集规模是百万、千万这个量级,拿用户向量与这么多物料向量逐一计算相似度是不现实的。所以召回双塔在离线生成众多的物料向量后,还要将这些向量喂入Faiss之类的向量数据库建立索引,以方便在线通过近似最近邻(ANN)搜索算法快速找到与用户向量相似的物料向量。
由于候选集至多只到万量级,因此粗排双塔在离线生成物料向量后,无须喂入Faiss建立索引,直接存入内存缓存起来,Item ID当“键”,物料向量当“值”。在线预测时,粗排线性遍历召回返回的候选集,逐一从缓存中取出物料向量,与唯一的用户向量做点积就能得到粗排得分。如果某个新物料的向量离线时没有生成,在线预测时从缓存中取不到,就由“物料塔”实时在线生成,并插入缓存中。
第二个不同点在于样本选择。
以点击场景为例,#card
对于正样本的选择没有什么争议,
都是以“用户点击过的物料”当正样本。
而对于负采样,两个双塔有着不同的选择策略。
召回#card
绝对不能(只)拿“曝光未点击”作为负样本,
负样本的主力必须由“随机负采样”组成。
粗排 #card
- 可以和精排一样,拿“曝光未点击”当负样本。
粗排这里存在样本选择偏差(SSB):
体现在#card
训练时用的都是曝光后的数据,经过了精排的精挑细选;
而在线预测时,面对的只是召回后的结果,质量远不如曝光数据。
尽管训练与预测存在着较大的数据偏差,但是拿“曝光未点击”作为负样本仍然“约定俗成”地成为业界的主流做法,效果也经受住了实际检验。#card
- 而纠正这个样本选择偏差,也成为业界改进、提升粗排模型的一个重要技术方向
第三个不同点在于“损失函数”的设计。#card


- 第四个不同点在于用户向量与物料向量的交互方式。#card
由于召回的在线服务要调用ANN算法快速搜索近邻,受ANN算法所限,召回双塔中的用户向量和物料向量只能用点积来实现交叉(cosine也可以转化成点积形式)。
排双塔由于不需要调用ANN算法,自然不受其所限。在分别得到用户向量和物料向量之后,粗排依然可以拿这两个向量做点积来计算用户与物料的匹配度,而且这是主流做法。但是,粗排也可以将这两个向量喂入一个DNN的实现更复杂的交叉。当然,这个DNN要简单、轻量一些,以保证粗排能够实时处理较大规模的候选集。
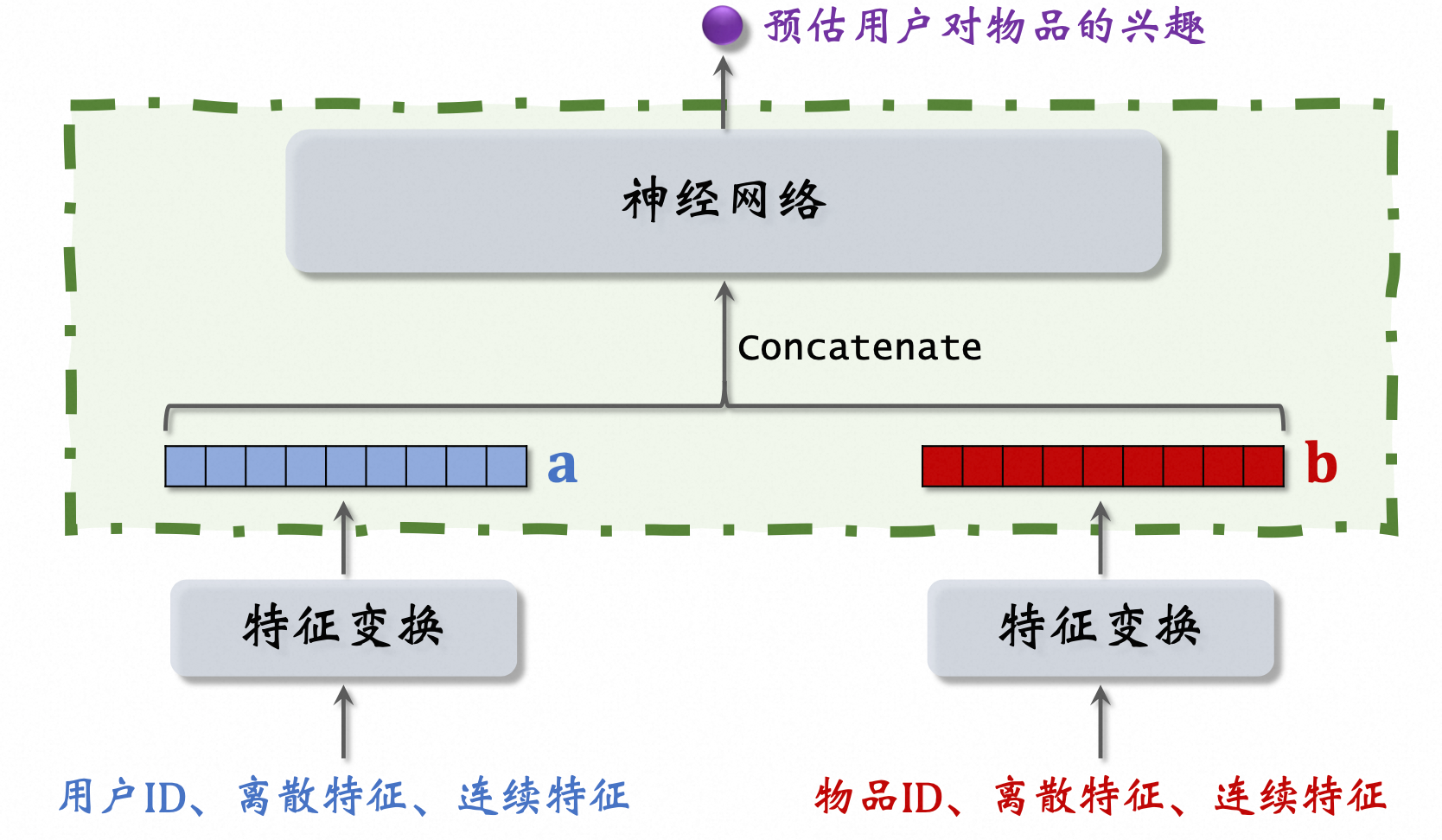
上图模型特点 #card
这块结构跟双塔模型是一样的,都是分别提取用户和物品的特征,得到两个特征向量。
但是上层的结构就不一样了,这里直接把两个向量做conatenation,然后输入一个神经网络,神经网络可以有很多层,这种神经网络结构属于前期融合,在进入全连接层之前就把特征向量拼起来了。
这种前期融合的神经网络结构跟前面讲的双塔模型有很大区别,双塔模型属于后期融合,两个塔在最终输出相似度的时候才融合起来。
为什么这个模型不能用来做召回双塔 ?#card
看一下图中的神经网络,这个神经网络最终输出一个实数作为预估分数,表示用户对物品的兴趣。再看一下这个部分,把两个特征向量拼起来输入神经网络。
这种前期融合的模型不适用于召回。
假如把这种模型用于召回,就必须把所有物品的特征都挨个输入模型,预估用户对所有物品的兴趣。
假设一共有1亿个物品,每给用户做一次召回,就要把这个模型跑1亿次,这种计算量显然不可行。如果用这种模型,就没办法用近似最近零查找来加速计算。
这种模型通常用于排序,从几千个候选物品中选出几百个,计算量不会太大。