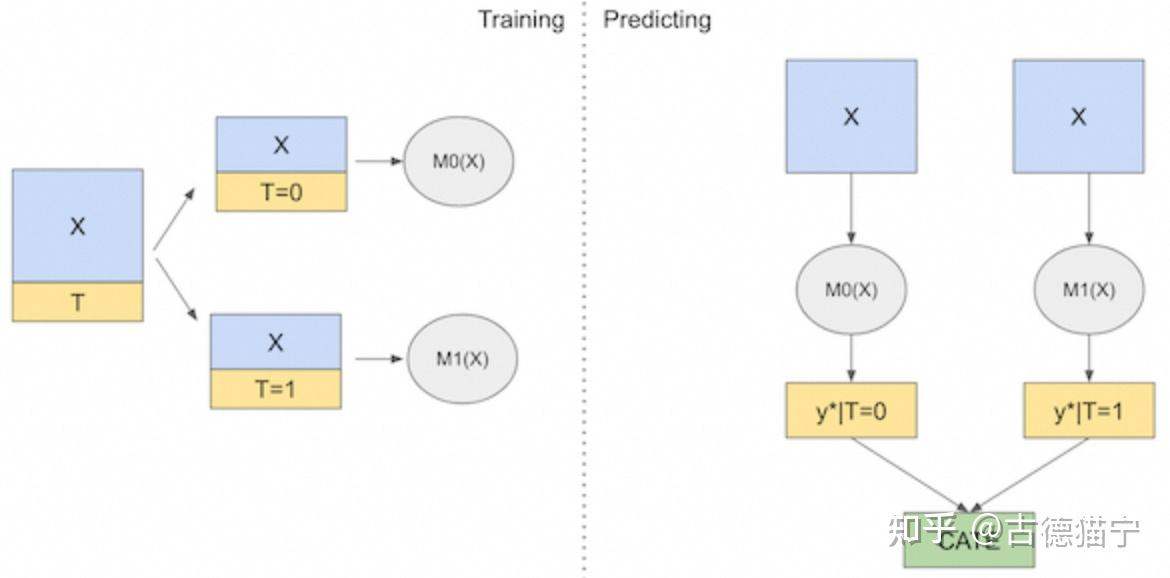
T-Learner
+
训练模型方式 #card
- 将控制组样本和干预组样本分别用于训练模型 $M_0$ 和 $M_1$ (Two,T 的由来),分别学习 $M_0(X) = E(Y|T=0,X)$ 和 $M_1(X) = E(Y|T=1,X)$ 。
如何预测 #card
- 在预测时对于同一份样本分别经过 $M_0$ 和 $M_1$ ,最终的 CATE 估计为 $\hat{\tau}(x)_i=M_1(X_i)-M_0(X_i)$
优点:#card
- 对干预组 / 控制组样本分别建模,充分考虑了干预变量的影响。
缺点:#card
两个模型训练 bias 不一致,容易有累积误差
干预组样本较少可能导致 $M_1$ 过拟合,因此只能降低 $M_1$ 的复杂度,这会导致 $M1$ 和 $M_2$ 存在差异,影响最终的因果效果估计准度。
对于拥有较多 ID 类特征,或者连续特征离散化,采用了 Embedding Layer,可以参考多任务学习的架构,共享底层 Embedding 参数,仅对上层 DNN 参数独立学习,这样可以利用控制组样本的信息。