Multi-Task Learning
基本网络框架 [[底层共享法]]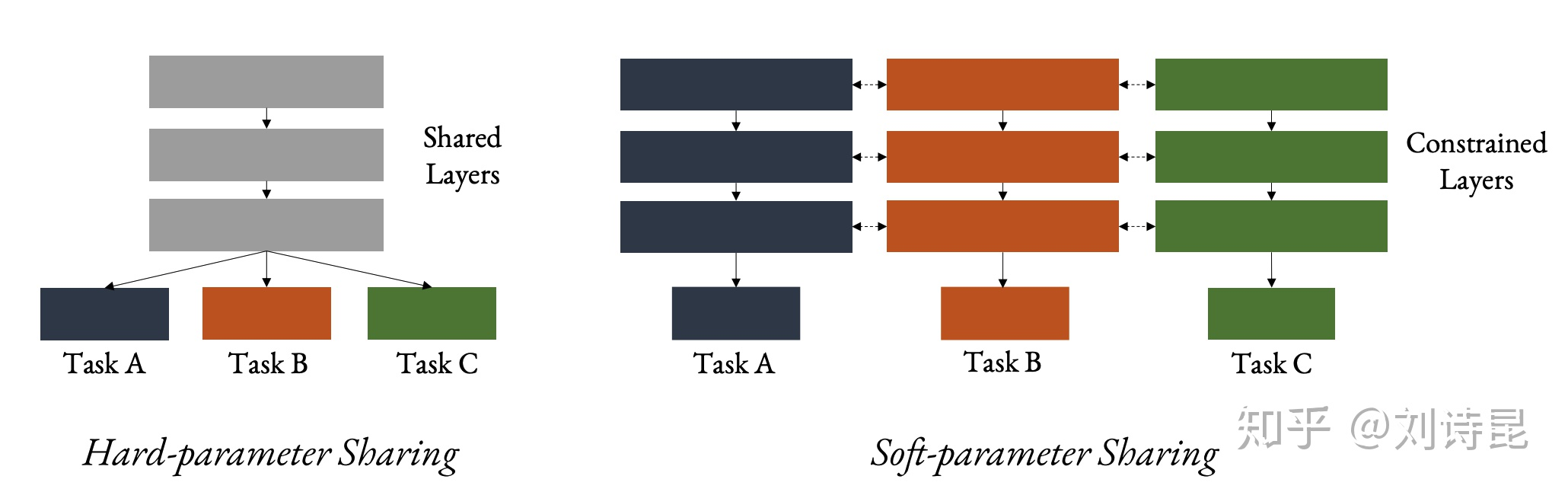
occlusion:: eyIuLi9hc3NldHMvaW1hZ2VfMTczNjE3NTMyNDk1N18wLnBuZyI6eyJjb25maWciOnt9LCJlbGVtZW50cyI6W3sibGVmdCI6MjY3Ljk5MzU1MDM0NDkxNjksInRvcCI6NjAyLjM4MzAxMDkzMDM5MjIsIndpZHRoIjozNDEuMTMyNDgzNDEzNjAxLCJoZWlnaHQiOjg3LjIzMzk3ODEzOTIxNTc2LCJhbmdsZSI6MCwiY0lkIjoxfSx7ImxlZnQiOjEyODcuMTM3ODQyNzI5Nzg5LCJ0b3AiOjYwMy44MTA5NTY5NDUzNjkzLCJ3aWR0aCI6Mjk5Ljk5MDY0NDI5MTI0MjIzLCJoZWlnaHQiOjg0LjM3ODA4NjEwOTI2MTI4LCJhbmdsZSI6MCwiY0lkIjoxfV19fQ==
结构
[[MMoE]]
CGC
ESSM
[[PLE]]
Optimization
Gradnorm
考虑 Loss 量级和考虑不同任务的速度
Label loss 和 Gradient loss
Dynamic Weight Averaging
两大分支:”网络设计” 以及 “损失函数设计”
关键点
任务需要有相关性
任务之间可以共享低层表示
网络设计
TODO 参考 [[神经网络与深度学习]]
网络如何小巧轻便,如何最大幅度的让不同的任务去共享信息。
Hard parameter sharing 底层共享参数,最上层有不同的任务。
Task 越多,单任务越不容易拟合
底层难以学到试用于所有任务的表达,比如多任务:猫狗分类,猫汽车分类
Soft parameter sharing
- 不同任务的参数空间需要添加限制,不然容易变成 single task learning
层次共享
- 图像中不同层次的表达能力不同:结构提取、语义提取
共享-私有
Cross-Stitch Network、Multi-Attention Network、AdaShare、MTL+NAS 可以参考 “综述性质的文章Multi-task Learning and Beyond: 过去,现在与未来 - 知乎“
损失函数设计
- 如何分配不同任务损失函数的权重?
类似方向 [[Auxiliary learning]]
[[Ref]]
DONE [[@深度学习的多个loss如何平衡?]]
[[@蘑菇街首页推荐多目标优化之reweight实践:一把双刃剑?]]
综述 Multi-Task Learning for Dense Prediction Tasks
[[@推荐精排模型之多目标模型]]
Multi-Task Learning
https://blog.xiang578.com/post/logseq/Multi-Task Learning.html