Transformer
[[Abstract]]
- The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 Englishto-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
[[Attachments]]
模型结构
![]()
Encoder and Decoder Stacks
![]()
![]()
[[Transformer/Encoder]]
每层包含两个子层,分别是 multi-head self-attention mechanism 以及 positionwise fully connected feed-forward network(其实就是一维卷积)
每一层间通过 residual connection 以及 [[Layer Normalization]]。表示成
LayerNorm(x+Sublayer(x))。 [[Post Norm]]- 和 [[ResNet]] 对比 Add 和 Norm 的顺序
所以内部连接层的大小都是 $${d_{model}=512}$$
[[Transformer/Decoder]]
第一个子层是 multi-head self-attention,与 encoder 不同的地方在与为了避免数据泄漏,计算位置 i 的 self attention 时,需要 mask 位置 i 之后的序列。
- q,k,v 是上一层的输出
第二个子层是 multi-head attention,用来捕获 encoder 的 output 和 decoder 的 output 之间的注意力关系。
- k 和 v 是来自 encoder,q 来自上一层 decoder
第三个子层和 Encoder 一样,是 positionwise fully connected feed-forward network
训练和预测
- 使用 teacher forcing 机制训练的 seq2seq 结构
Input Embedding
为什么获取输入词向量后需要对矩阵乘以 embedding size 的平方?意义是什么?
- embedding matrix 的初始化方法是 [[Xavier Initialization]],方差是 1/embedding size,通过 scale 更有利于matrix收敛
为什么不直接使用标准正态分布?
tied-embedding 输入词向量层和输出词向量层(softmax 前的线性层)共享参数
线性层需要用 [[Xavier Initialization]] 初始化
Attention 是 :-> [[scaled dot-product attention]]
[[Position-wise Feed-Forward Networks]]
Embeddings and Softmaxweight typing
seq2seq 语言模型中绑定 embedding 权重和 docoder softmax 之前的线性层权重矩阵。
可以减少参数量,压缩模型大小,embedding 训练更加充分,缓解每次更新少数词 embedding 的情况。
权重共享
- decoder 和 encoder embedding 层
- 原始任务是 English-German 翻译,词表使用 bpe 处理,最小单元是 subword。两种语言有相同地 subword
- 不同语言之间可以共享对数词或符号的建模
- decoder 中 embedding 层 和 fc 层权重
embedding 层通过词的 one-hot 去取对应的向量
fc 层通过向量去得到可能是某个此词的 softmax 概率最大,和词相同的那一行对应的点积和softmax概率会是最大的。
- 两数和相同的情况下,两数相等对应的积最大。
- decoder 和 encoder embedding 层
每个权重放大 ${\sqrt{d_{model}}}$
[[Xavier Initialization]] Embedding 的方差是 1/d_model,当 d_model 值非常大时,矩阵中的每一个值都会减小。
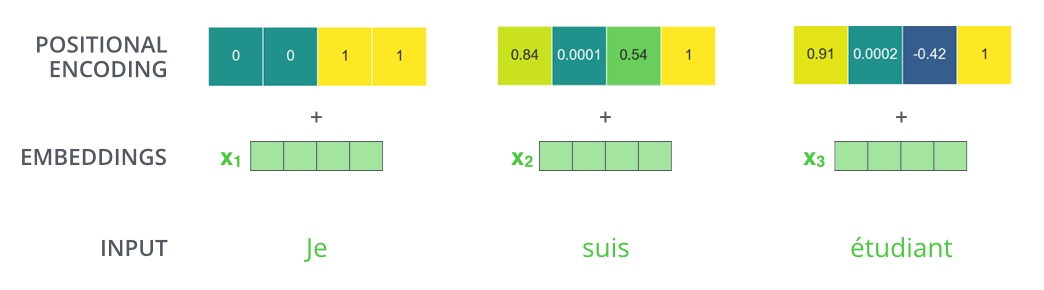
- [[Positional Encoding]] 是通过三角函数算出来的,值域为 -1 到 1。需要放大 embedding 数值,否则规模不一致相加后会丢失信息。 [[BERT]] 中不需要调整
使用 self-attention 相当于处理[[词袋模型]],忽视单词之间位置关系,通过引入 [[Position Representation]] 弥补模型缺陷。
[[Positional Encoding/Sinusoidal]]
实现
tensor2tensor/layers/common_attention.pyget_timing_signal_1d
Positional Embedding
将位置转化成 embedding,然后当成参数学习
论文中的实验表明两种方式的效果相差不大
参数数量增加,模型学习难度增大,需要使用更多数据训练
无法解决预测文本长度超过训练文本长度的情况, [[BERT]] 强制文本长度 512
单词 embedding 和对应位置表示直接相加
[[Transformer/why self-attention]]
[[Transformer/train]]