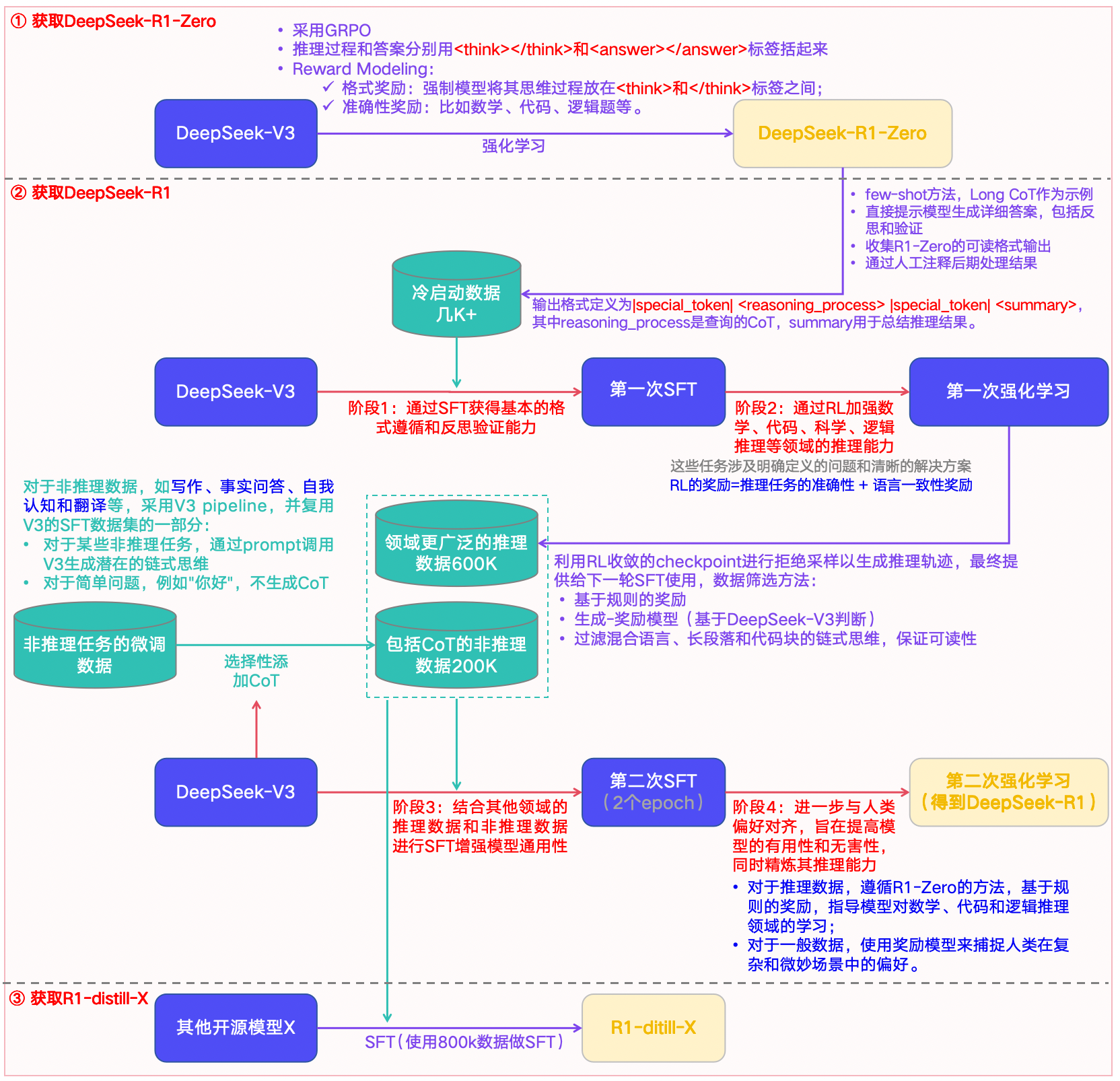
图1-1:DeepSeek-R1生成的完整流程
occlusion:: eyIuLi9hc3NldHMvaW1hZ2VfMTc0MzI1ODU1MzY2N18wLnBuZyI6eyJjb25maWciOnt9LCJlbGVtZW50cyI6W3sibGVmdCI6ODUzLjM4NDgxNDg0MDkyMSwidG9wIjo4Ni42ODQ4NjM4NjA1OTUxLCJ3aWR0aCI6ODUyLjA3NDA4NzI2OTgyOTYsImhlaWdodCI6MTE4LjM2NTcyODE1MzY4NTYxLCJhbmdsZSI6MCwiY0lkIjoxfSx7ImxlZnQiOjE0NTcuNTYzNTUwMjAxNzkyLCJ0b3AiOjMzNS4yOTkxODEwOTk5MDczNCwid2lkdGgiOjM2Ni4wOCwiaGVpZ2h0IjoxMzQuMTU2MTY2OTgxMTY3MywiYW5nbGUiOjAsImNJZCI6Mn0seyJsZWZ0IjoxMjA1LjE4OTI3MjQyODkwODcsInRvcCI6NDY1LjQ4MjgzOTU1NzM3NzgsIndpZHRoIjo4MzQuODYxNDU2NzgxMzcyNiwiaGVpZ2h0Ijo2Ny4wMDM4MjU3MjY5Njc3NiwiYW5nbGUiOjAsImNJZCI6M30seyJsZWZ0Ijo2NzMuMzUwNzE0MDk2MDY5OSwidG9wIjo2MjcuMzc1NzA1NDU3MTg2Nywid2lkdGgiOjMxMi40OTY2NzI5MDY5NTkyNSwiaGVpZ2h0Ijo4My4wMDk5NDc2NzU1NTAxNywiYW5nbGUiOjAsImNJZCI6NH0seyJsZWZ0IjoxMjQzLjQ2NjE2NjgwNTQyOSwidG9wIjo2NjkuNTY4OTAwNTY3NzEwMiwid2lkdGgiOjQyNS4xMDU1ODgwODI5MzQ0NSwiaGVpZ2h0IjoxNDUuMjAwNDM1NTQxOTYxODQsImFuZ2xlIjowLCJjSWQiOjV9LHsibGVmdCI6MjczLjAzODM4MTMwNDgwNjIsInRvcCI6Nzk1Ljk0MDY5MzM3NzY2MDUsIndpZHRoIjo0NzMuMzczMzQ0OTk0MzIzNjUsImhlaWdodCI6MTg1LjYxMDYwNjA5Njk3OTM4LCJhbmdsZSI6MCwiY0lkIjo2fSx7ImxlZnQiOjExODYuNDI4NzU5NTg5ODY3MiwidG9wIjo4OTguNjM5NjU2NzA2NTg3LCJ3aWR0aCI6NzMyLjQzNzYwODg4MjM4ODIsImhlaWdodCI6MTgwLjA5MDI0MDQ2NzQ3OTcsImFuZ2xlIjowLCJjSWQiOjd9LHsibGVmdCI6NzAyLjcyNjA0ODUxMzU0MjUsInRvcCI6MTIyMi40MjYwOTU5NjY1NjM3LCJ3aWR0aCI6MjgwLjQwMjE3MDQ2NzY0NTMsImhlaWdodCI6OTguODM3MTE4MTk0NTI2MjgsImFuZ2xlIjowLCJjSWQiOjh9LHsibGVmdCI6MTMzOS42ODAwNTk1NTU3NDEsInRvcCI6MTMwOS42OTkyMzAxMzg4MzczLCJ3aWR0aCI6NTEyLjU2NzU0OTczNjQ0NDMsImhlaWdodCI6MjU3LjQyMDExODIzMDU2NzYsImFuZ2xlIjowLCJjSWQiOjl9XX19
1)获取DeepSeek-R1-Zero:#card
- 通过”纯”强化学习(无任何监督数据)去生成一个新模型,即R1-Zero,然后用它生产几千+带CoT的冷启动数据,作为后续R1模型的燃料之一。
2)获取DeepSeek-R1:主要包括四个核心训练阶段(阶段1、2、3、4)和2个数据准备阶段(阶段0、2.5):
- 阶段0 :-> 即获取DeepSeek-R1-Zero。
- 阶段1 :-> 基于R1-Zero的几千+数据,在V3-Base上执行第一次SFT,获得基本的格式遵循和反思验证的能力。
- 阶段2 :-> 然后执行第一次强化学习,加强模型在数学、代码、科学、逻辑推理等领域的推理能力。
- 阶段2.5 :-> 基于阶段2的模型,获取领域更广泛的600K数据;基于V3-Base,获取包括CoT的非推理数据200K。
- 阶段3 :-> 基于阶段2.5获取的800K数据,在V3-Base上执行第二次SFT,增强模型的通用性。
- 阶段4 :-> 执行第二次强化学习,进一步对齐人类偏好,提升模型的可用性和无害性,并精炼推理能力。
获取R1-Distill-X的流程,#card - X是指任何”其他模型”,比如qwen。在800K数据的微调后,将大幅提升原模型的效果。
图1-1:DeepSeek-R1生成的完整流程
https://blog.xiang578.com/post/logseq/图1-1:DeepSeek-R1生成的完整流程.html