@Embedding-based Retrieval in Facebook Search
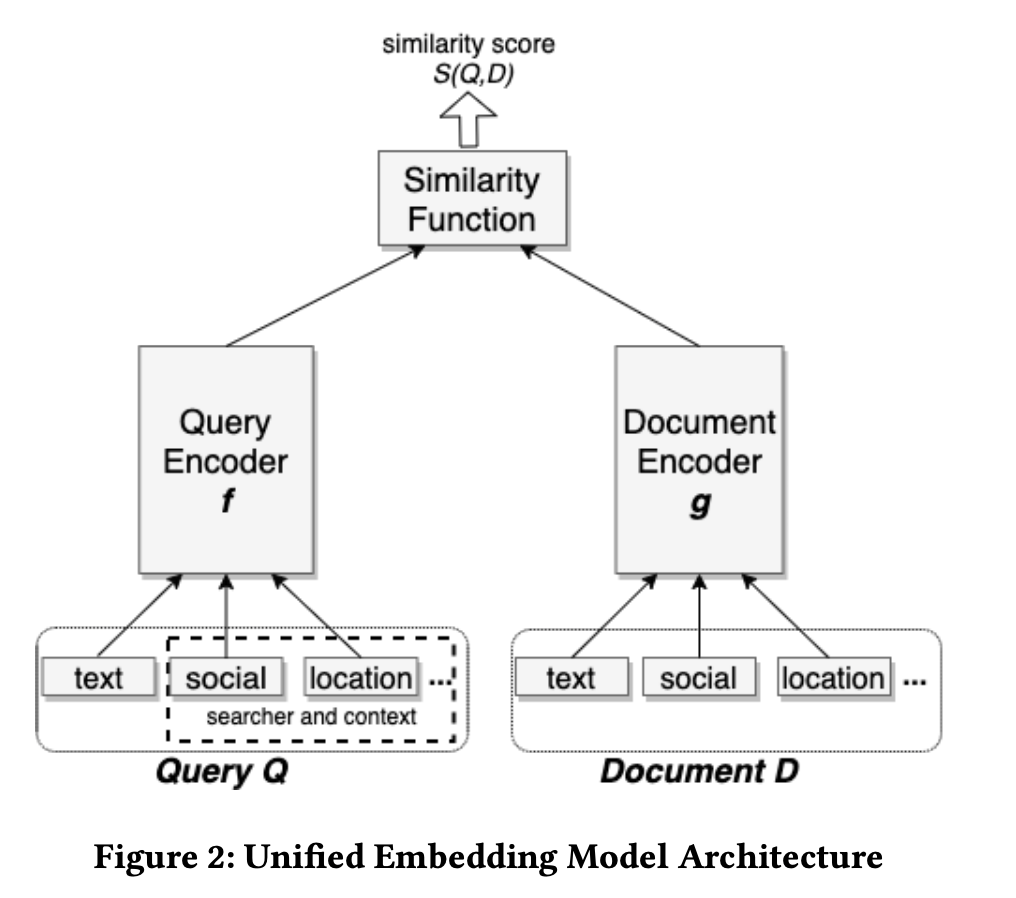
- 除了主要的文本特征,还增加了user和doc的位置、社交关系的side info增强 query和doc 的匹配能力。
- 模型的训练目标#card
为双塔输出向量的距离,使正样本对距离尽可能小(相似度分数尽可能大),负样本对距离尽可能大(相似度分数尽可能小)。
基线模型的样本构造也比较简单,使用query-doc的点击pair对作为正样本对,负样本有两种选择:#card
随机负采样:对每一个query随机从doc池中采样相应比例的负样本。
曝光未点击的样本:对于每一个query,随机从session内曝光未点击的样本作为负样本。
文中实验显示前者的效果明显强于后者,原因在于后者使得训练样本和后续预测样本有明显的分布不一致,即存在严重的样本选择偏差问题。
向量召回问题
候选集离线训练和线上服务的压力
matching 问题
[[新召回往往会存在后链路低估的问题,如何克服这个问题带来增量?]] #card
将召回生成的embedding作为ranking阶段的特征,可以直接将embedding作为特征或者计算query和doc的embedding各种相似度,通过大量实验证明,consine similarity有较好的结果。
为了解决向量召回准确率较低的问题,将向量召回的结果直接进行人工标注,然后再基于标注的结果进行训练。这种方法比较暴力并且效率比较低。
Ref
@Embedding-based Retrieval in Facebook Search
https://blog.xiang578.com/post/logseq/@Embedding-based Retrieval in Facebook Search.html