@推荐精排如何加特征?
关注问题#card
第一、特征是重要的先验知识,但是有时我们自认为加入了一个非常重要的特征,但是模型效果却没有提升,这是特征无用呢?还是加的位置不对呢?
- 第一个话题,就讨论如何将“先验重要”的特征加到合适的位置。
第二、在多目标的场景下,如果某个目标比较稀疏,我们如何利用先验知识辅助它,使其能学得更好呢?
信心满满地设计了特征,感觉非常有业务sense,吭哧吭哧打通了上下游数据链路,模型预测一看,离线指标却稳如泰山。造成这种情况的原因有很多,其中一个可能就是,如果你的特征确实有用,但他没发挥作用的原因,很可能是特征的位置不对。#card
第一,如果你先重要的特征加到DNN底部,层层向上传递,恐怕再重要的信息到达顶部时,也不剩下多少了。
第二,DNN的底层往往是若干特征embedding的拼接,动辄五六千维,这时你新加入一个特征几十维的embedding,被“淹没”恐怕也不会太奇怪。那么,特征究竟要如何加才能发挥效用呢?这正是本文探讨的话题。
[[重要特征加得浅]]
-
- wide侧就是一个LR,或者我们稍微扩展一下,就是一个一层的NN网络。#card
- wide侧的特征离Loss近,避免了自DNN底部层层传递带来的信息损失,更有机会将我们的先验知识“一步到顶”。
- wide侧就是一个LR,或者我们稍微扩展一下,就是一个一层的NN网络。#card
那么,哪些特征要进wide侧,哪些特征要进deep侧?:-> wide侧负责记忆,因此要将“强业务背景,显而易见的特征,喂入Wide侧”。
在推荐领域加入wide侧#card
特征及特征对上的统计数据,<女性,20~30岁,商品类别是‘裙子’>上的点击率、加购率等;
或者,我们已经发现了非常明显的用户分层,比如登录用户 VS 未登录用户、高频VS低频,用户行为完全不同。为了提升模型对“用户是否登录”、“高频低频”这样强bias特征的敏感度,这些特征也。
这里多提一个扩展性案例、与用户分层类似,淘宝的STAR《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》也是将domain-id这样的强bias特征,喂入一个非常简单的dnn,得到的logits再叠加到主网络的logits上,算是wide&Deep的一个变种。#card
- 论文最后坦言,“the auxiliary network is much simpler …… The simple architecture makes the domain features directly influence the final prediction”,有兴趣或者相似场景的同学可以去试一下。
重要要特征当裁判
对于一些强bias特征(eg:用户是否登录、来访天数),除了将它们加浅一些,离目标Loss更近,还有一种方法能够增强它们的作用,避免其信息在dnn中被损失掉,就是采用结构 :-> [[SENet]]或[[LHUC]]
SENET就相当于用户站在输入特征旁边,亲自下场辨认哪个特征有多重要,这其实也是一种变相的 self_attention 机制(如果SENET的输入是所有特征的话,可能就更接近self_attention的思想了)
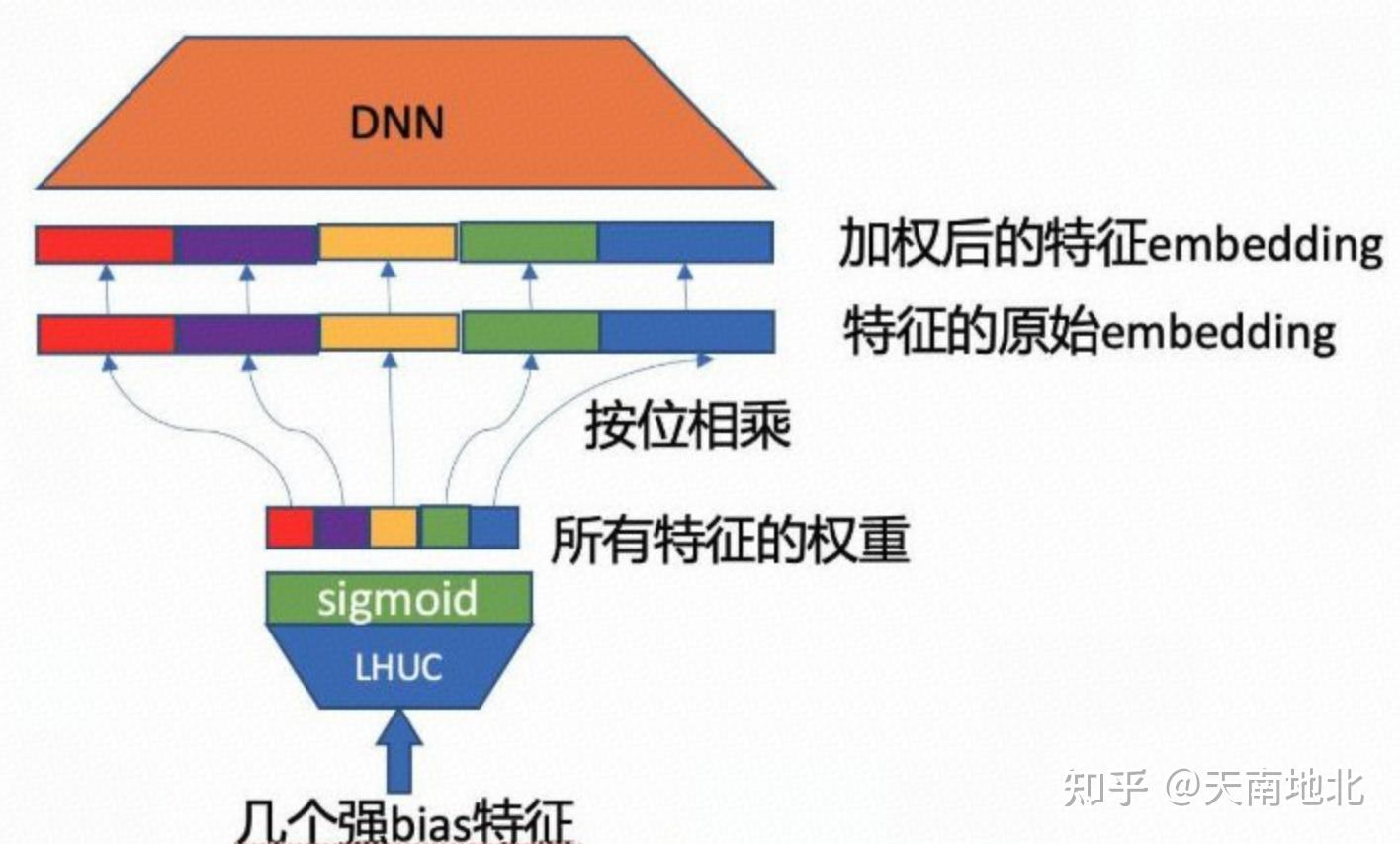
强bias特征作为LHUC的输入,经过sigmiod激活函数后,输出是一个N维度向量。#card
- N是所有fileld的个数N维向量就是各field的重要性,将其按位乘到各field的embedding上,起到增强或削弱的作用加权后的各field embedding再拼接起来。
当然,如果SENET的输出维度N直接是input_layer的维度也可以,这就从vector_size变成 element_size 。
喂入上层DNN这种结构,将一些先验认为重要的强bias的特征,放到裁判的位置,决定其他特征的重要性。#card
比如,如果产品设计不允许未登录用户购买商品,那么显然“用户未登录”这个特征值,就“应该”将转化相关特征的权重置为0,因为它不能代表用户的真实意图。
这样做,相比于将所有特征“一视同仁”、直接全部喂入DNN最底层,更能发挥重要特征的作用,将“先验知识”(比如这里的产品设计限制)深入贯彻。
一般都有哪些重要特征呢?
表征用户本身bias的,#card
- 比如用户的活跃程度、消费等级、性别、圈子等。
表征上下文场景的bias的,#card
比如用户几点来APP啊;
用户当天有没有显著表露意图,比如淘宝上搜索了,加购了,购买了;
商品位置信息等等。
表征样本bias的,#card
比如快手之前将快手APP、极速版上同一个场景的样本合并在一起训练,
那么样本来自哪个APP也就是一个至关重要的特征了。
链路前节点信息帮后链路稀疏目标学习
当前,多目标在推荐领域已经是屡见不鲜,以商品推荐为例,我们曝光透出的商品,不仅要让用户点击,用户点击代表着用户愿意花时间和APP一起玩,这直接代表着APP的生态;而点击之后还要尽可能地加购,当然最终目标是转化,转化直接关系公司营收。因此,我们从来不做选择,我们全都要!#card
- 多目标之间往往存在前后依赖关系(比如先点击,才有可能转化),这样意味着,链路越靠后的环节,正样本就越稀疏,训练收敛也就越困难。因此,一个自然的想法就是多目标之间能否互助,或者一个稍微牺牲一点点去辅助另外一个而达到整体更优。
信息从前往后迁移
- 典型的案例有ESMM模型,pCTCVR=pCTR*pCVR。CTR任务的数据更多,预测精度更高,会给CTCVR的预测任务以提示。或者DBMIT模型。他们都是“拿链路前端环节的输出,作为链路后端环节的输入”,即“利用先验知识显式制订信息迁移规则”的典型手段,#card
以商品推荐为例,点击环境的训练数据丰富、他的隐层输出,将极大帮助转化这个靠后环节的训练,当然这也符合一般认知,我们可以认为用户一旦点击了,他就朝着购买这个终极目标前进一步,用户加购了,则再进一步,
因此,将点击、加购信息直接显示迁移到转化上,是符合产品设定下用户真实习惯的。
- 典型的案例有ESMM模型,pCTCVR=pCTR*pCVR。CTR任务的数据更多,预测精度更高,会给CTCVR的预测任务以提示。或者DBMIT模型。他们都是“拿链路前端环节的输出,作为链路后端环节的输入”,即“利用先验知识显式制订信息迁移规则”的典型手段,#card