@快手推荐算法工程师的1年半: 业务驱动的算法创新
链接: 快手推荐算法工程师的1年半: 业务驱动的算法创新 - 知乎
我的工作方法:持续思考,不盲从
第一,跨界学习,但有选择性。#card
我不会把自己局限在推荐算法这一个领域,而是广泛涉猎各种AI技术和理论基础。我会关注最新的NLP或CV领域里有突破性的论文,从中汲取灵感,但不怎么喜欢看推荐系统的论文——说实话,这个领域平均质量比较差,大家都在玩小数据集,都在搞自己的baseline,每篇论文都声称自己超越了前人,很难让人信服。
我更喜欢阅读经典书籍,比如《Probabilistic Machine Learning》《动手强化学习》,以及一些高质量的公开课,比如香港大学的信息论、UC Berkeley的CS285强化学习课程。这些系统性的理论知识比追逐最新论文更能给我带来深刻的理解和灵感。当然,需要写论文时我也会认真调研现有工作。
第二,问题驱动,从业务痛点出发。#card
- 每次解决问题,我不是先想”我要用什么酷炫的算法”,而是认真思考”业务的真正痛点是什么”。快手的用户体量巨大,行为异常复杂,理解业务比套用算法重要得多。通过分析用户行为数据,常常能发现被忽视的模式和优化机会。
第三,写作倒逼思考。#card
有了初步想法后,我喜欢尝试把它整理成论文形式。这个”倒逼”机制特别有用——它逼着我系统思考问题,找理论依据,设计合理实验,最终不断完善算法。
正是这种方法让我在一年半时间里完成了四篇算法研究,更重要的是在实际业务中创造了价值。
第四,小步快跑,迭代验证。#card
- 我在快手学到的另一个重要方法是”小步快跑”。不追求一步登天,而是先上最小可行版本验证思路,然后根据反馈不断迭代。这种方式让我能迅速试错,及时调整方向,大大提高了工作效率。
CQE算法:从”预测总是不准”到”建模整个分布”
动机:为什么watch time预测总不够准?#card
在快手,我最初负责多样性相关工作,这强烈依赖于各种PXTR(预测值)的准确性。日常工作中我发现一个有趣的现象:我们的模型在整体指标上看起来还不错,但对单个用户-视频对的时长预测却经常有很大偏差。有时候模型预测用户只会看几秒,结果他看完了整个视频;有时候预测会看很久,实际却几秒就划走了。
思考后我意识到问题的本质:我们一直在用一个点估计(单一期望值)来预测本质上充满不确定性的行为。我们无法完全获取用户的信息,导致用户的行为本身就是随机的。同一个用户在同一个时间看同一个视频的时长是一种分布,这种不确定性用单一值根本无法准确捕捉。
灵感:分位数回归的应用#card
解决思路的灵感来得很偶然。一天早上,我在会议室里看《Probabilistic Machine Learning》这本书,读到Quantile Regression(分位数回归)章节时,突然有种被闪电击中的感觉——分位数回归不就是描述分布的好方法吗?它能同时预测多个分位点,从而刻画整个分布的形状!
当天我就迫不及待地开始实现这个想法。基本思路是:不再预测单一的期望watch time,而是同时预测多个分位数(比如10%、25%、50%、75%、90%分位数),从而捕捉watch time的整个条件分布。这样,我们不仅知道用户可能观看多久(中位数),还能了解这个预测的不确定性范围(分位数间距)。
意外的发现:分布特性与预测准确性的关系#card
在论文的Rebuttal过程中,一位审稿人提出了一个尖锐问题:”有什么量化的数据支持分布建模的重要性吗?”。这个问题确实难倒了我。
为了回应这个问题,我进行了一项额外实验:研究分布特性(如IQR,即分布宽度)与预测准确性之间的关系。结果出乎意料地清晰:
1 | IQR范围 UAUC MAE 样本比例 |
+ 这张表告诉我们:分布不确定性越小(IQR越小)的样本,预测准确性越高(UAUC更高,MAE更低)。这个发现不仅回答了审稿人的问题,还让我对用户行为本质有了更深的理解:用户行为的可预测性是不均匀的,有些行为模式(如重度用户)更稳定可预测,而另一些(如新用户或探索行为)则充满不确定性。
+ 有了这个watch time分布建模方法后,我们就可以根据业务需求设计不同的推断策略了,比如保守估计、动态分位数融合等。最终,CQE算法在线上带来了可观的留存(LT)、时长、播放量(VV)和多样性收益。
AlignPxtr算法:从复杂因果推断到简单对齐
问题:学术界的方法为何如此复杂?
- 推荐系统中存在另一个关键挑战:偏见(bias)问题。在快手,最典型的就是时长偏见(duration bias)——用户自然会在更长的视频上花更多时间,但这并不一定反映真实兴趣。#card
当时学术界流行用因果推断来消除这类偏见。
我阅读了大量论文,发现它们都构建了复杂的因果图,用反事实推理或后门调整等高深技术。
这些方法理论上很优美,但实施起来较为复杂,让我不禁怀疑其在工业界的实用性。
- 推荐系统中存在另一个关键挑战:偏见(bias)问题。在快手,最典型的就是时长偏见(duration bias)——用户自然会在更长的视频上花更多时间,但这并不一定反映真实兴趣。#card
洞察:简化的力量
- 有一天,我突然意识到一个关键点:不管这些方法多复杂,最后的结果,本质上它们不都是在对预测值做某种形式的”标准化”或”对齐”吗?核心就是将原始预测值除以或减去与偏见相关的后验统计量(均值或分位数)。#card
我开始质疑:这些复杂方法的核心价值到底在哪?它们真能细化到用户ID级别吗?在实际业务环境下,会不会有更简单直接的方法效果一样好甚至更好?
带着这些疑问,我尝试了最简单的方法:直接对齐预测值(PXTR)的均值。具体做法是,对于每个偏见因素(如视频时长),计算不同条件下的预测均值,然后从原始预测中减去这个条件均值的偏差。
令我惊讶的是,这个简单方法在线上测试中带来了显著收益!这让我对学术界复杂方法的必要性产生了深刻质疑。
- 有一天,我突然意识到一个关键点:不管这些方法多复杂,最后的结果,本质上它们不都是在对预测值做某种形式的”标准化”或”对齐”吗?核心就是将原始预测值除以或减去与偏见相关的后验统计量(均值或分位数)。#card
理论突破:从均值对齐到分布对齐
- 后来我系统学习了信息论知识,并做了一系列可视化分析,才恍然大悟:原来对齐PXTR的均值,本质上是在降低变换后的PXTR与偏见因素之间的互信息。而如果能对齐整个分布(所有分位数),理论上可以让这个互信息降为零,达到完全独立。#card
这个洞察让我把前面的CQE与新的对齐思想结合起来,形成了AlignPxtr(Aligning Predicted Behavior Distributions)算法。它的核心是:通过条件分位数映射,将不同偏见条件下的行为分布对齐,从而消除偏见影响。
AlignPxtr的成功让我深刻认识到:在算法设计中,简单往往是一种力量。有些问题看似需要复杂的理论框架,但仔细思考后可能发现有更直接、更有效的简化方法。正如爱因斯坦说的:”Everything should be made as simple as possible, but not simpler.”(一切应该尽可能简单,但不能过于简单)。
- 后来我系统学习了信息论知识,并做了一系列可视化分析,才恍然大悟:原来对齐PXTR的均值,本质上是在降低变换后的PXTR与偏见因素之间的互信息。而如果能对齐整个分布(所有分位数),理论上可以让这个互信息降为零,达到完全独立。#card
效果 #card
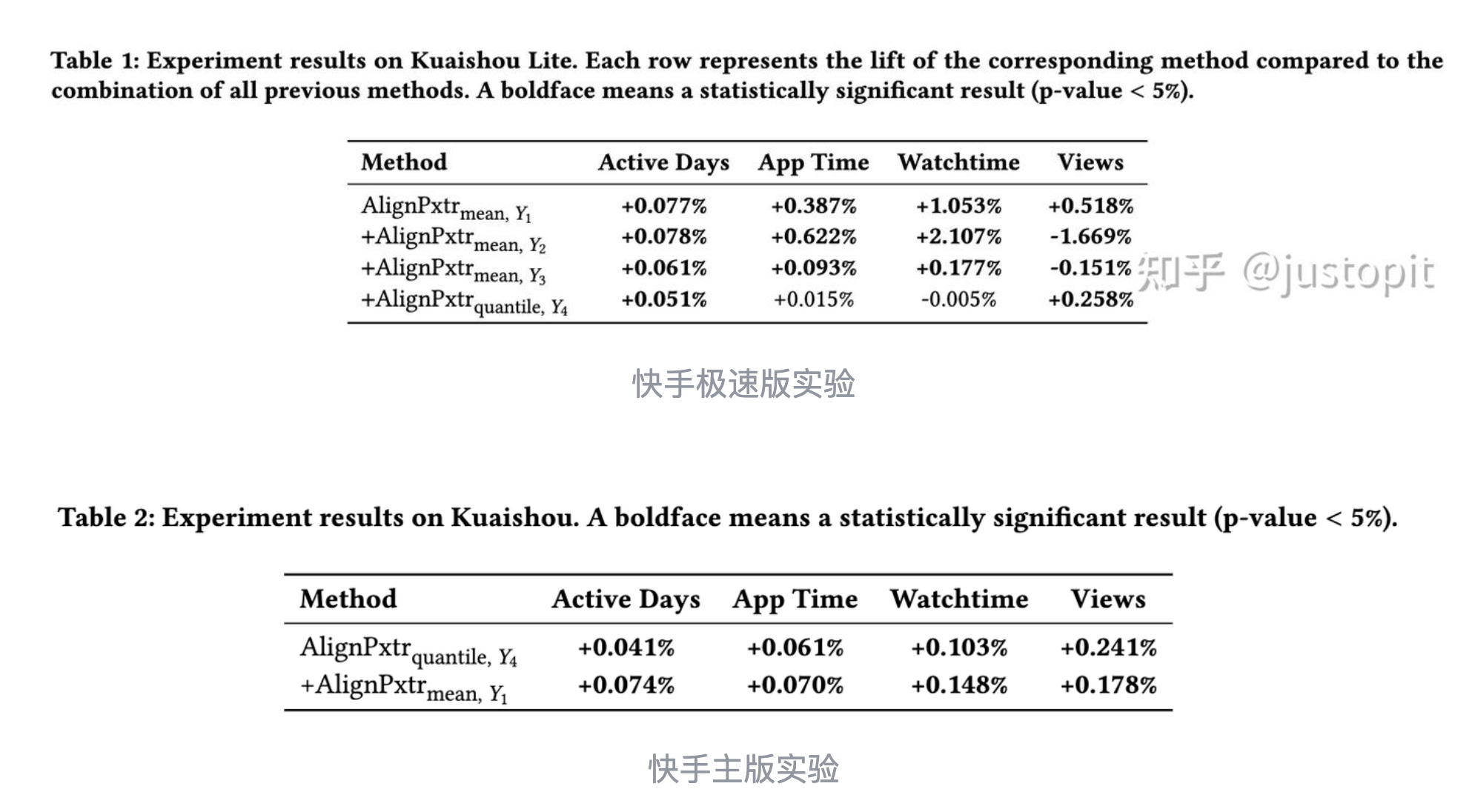
SEC算法:从强化学习到行为克隆的思维跃迁
问题背景:如何优化长期用户留存?#card
- 我的第三个研究方向来源于对用户留存(retention)问题的思考。推荐系统的最终目标不仅是提高短期参与度,还要确保用户长期留存。传统的基于点击率、观看时长的优化可能带来短期收益,但不一定有利于长期留存。
灵感源泉:卧室里的强化学习书籍#card
当时我正躺在床上翻阅《动手强化学习》这本书,思考如何将RL应用到留存优化中。传统的强化学习方法需要设计合适的reward函数,并通过试错学习找到最优策略。但在实际业务中,这面临两个巨大挑战:一是如何设计与长期留存挂钩的reward函数;二是在线探索可能带来负面用户体验。
正当我为这些难题发愁时,翻到了书中关于行为克隆(Behavior Cloning)的章节,突然灵光一闪:快手有海量用户数据,其中不乏高留存用户,何不直接克隆这些”专家”用户的行为模式?相比复杂地设计reward和冒险的在线探索,这种方法直接得多!想到大语言模型的Pretrain和SFT(监督微调)阶段本质上也是行为克隆,我更加确信这个思路的可行性。
创新点:多层次专家与策略多样性
进一步思考后,我发现单纯的二分法(专家/非专家)太过简化。用户活跃度有多个层次,从超高活跃到高活跃再到中等活跃,每个层次可能有不同的行为模式。#card
- 同时,研究中我还注意到一个严重问题:简单的行为克隆容易导致策略崩塌(policy collapse),即模型只学到非常有限的行为模式,缺乏多样性。这在推荐系统中尤其危险,因为用户兴趣本身就是多样的。
结合这些思考,我设计了SEC(Stratified Expert Cloning)算法,它包含三个关键创新:#card
多层次专家分层:根据活跃度将专家分为多个层级,分别学习不同层级的行为模式
熵正则化:借鉴LeCun的工作,引入熵正则化防止策略崩塌,促进多样性
自适应专家选择:为每个用户动态选择最合适的专家策略
惊人的效果:改变数十万用户的留存 #card
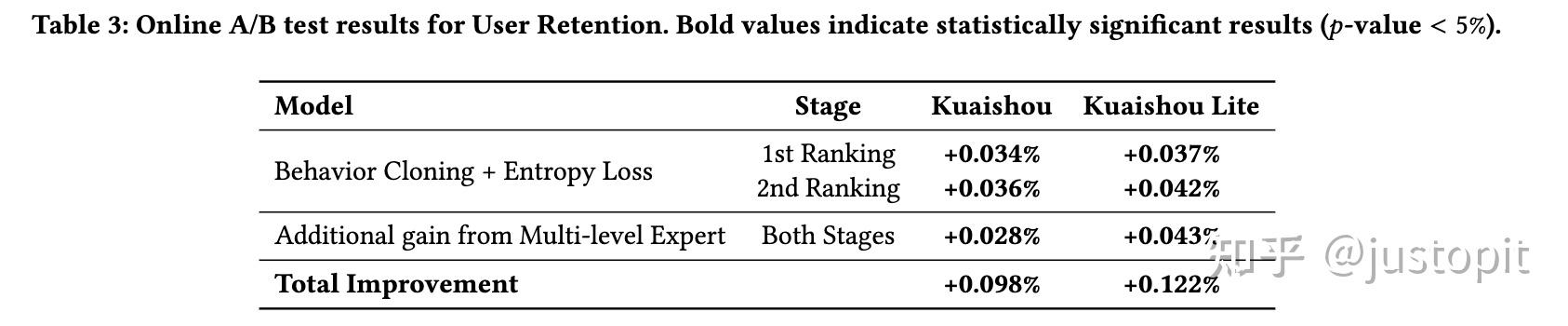
- SEC还可以用在用户兴趣拓展:

算法工程师的元认知:我的思考方式
这一年半的工作经历,让我对算法创新的本质有了更深的思考:
复杂与简单的权衡#card
在算法设计中,我常陷入一个两难选择:是追求理论上完美但实现复杂的方案,还是选择实用简单但可能次优的方案?
经过反复实践,我的结论是:理论洞察很重要,但最终方案应该尽可能简单。好的算法像冰山,水下是深厚的理论思考,水上却是简洁易懂的实现。我的三个算法都体现了这一点——它们背后有深入的理论分析,但最终实现却相对直观简洁。
AlignPxtr可能是最典型的例子——我直接用简单的对齐方法取代了复杂的因果推断框架,不仅实现更简洁,效果还可能更好。这正是我经常提醒自己的:不要被复杂性迷惑,真正的优雅往往是简洁中蕴含深度。
理论与实践的循环提升#card
我发现,理论思考和实践验证之间存在一种奇妙的正反馈循环。好的理论指导实践方向,而实践中的反馈又能纠正和完善理论。
比如在SEC研究中,起初我只考虑了行为克隆的基本思路,但实践中发现策略崩塌问题,这促使我引入熵正则化;而熵正则化的效果又让我进一步思考多样性在推荐系统中的理论意义。这种”理论-实践-再理论”的循环迭代,让我的思考不断深入、算法不断完善。
在反复实践中,我意识到:创新不是一蹴而就的灵光乍现,而是在这种循环中渐进式产生的。每次迭代都在我的思维中植入新的种子,最终生长为有价值的算法创新。
结语:算法创新的本质#card
经过一年半的实践,我对算法创新的本质有了更深理解:它不是为了创新而创新,而是为了解决实际问题;它不仅仅是数学和代码,还包含对业务的深刻理解;它的价值不在论文发表数量,而在于给用户和业务带来的实际改进。
回想起写这三个算法的初衷,我都是从一个简单的业务问题出发:CQE源于”为什么watch time预测总不准”的困惑,AlignPxtr源于对复杂因果推断方法的质疑,SEC则是想避免复杂的强化学习探索。每次,都是从实际问题出发,通过深思熟虑和反复验证,最终发展成一个完整的算法框架。
这告诉我:真正有价值的创新,往往源于对实际问题的深刻洞察,而不是为了创新而创新。
@快手推荐算法工程师的1年半: 业务驱动的算法创新
https://blog.xiang578.com/post/logseq/@快手推荐算法工程师的1年半: 业务驱动的算法创新.html