机器学习模型设计五要素
{x,y}
- 根据业务特点提取数据
f(x)
参数量
- 通过[[VC维]]衡量模型复杂度
结构,都有自己的 [[inductive bias]]
objective
产品的 KPI 转换成模型的损失函数
P(model|data) = P(data|model) * P(model)/P(data) —> log(d|m) + log(m)
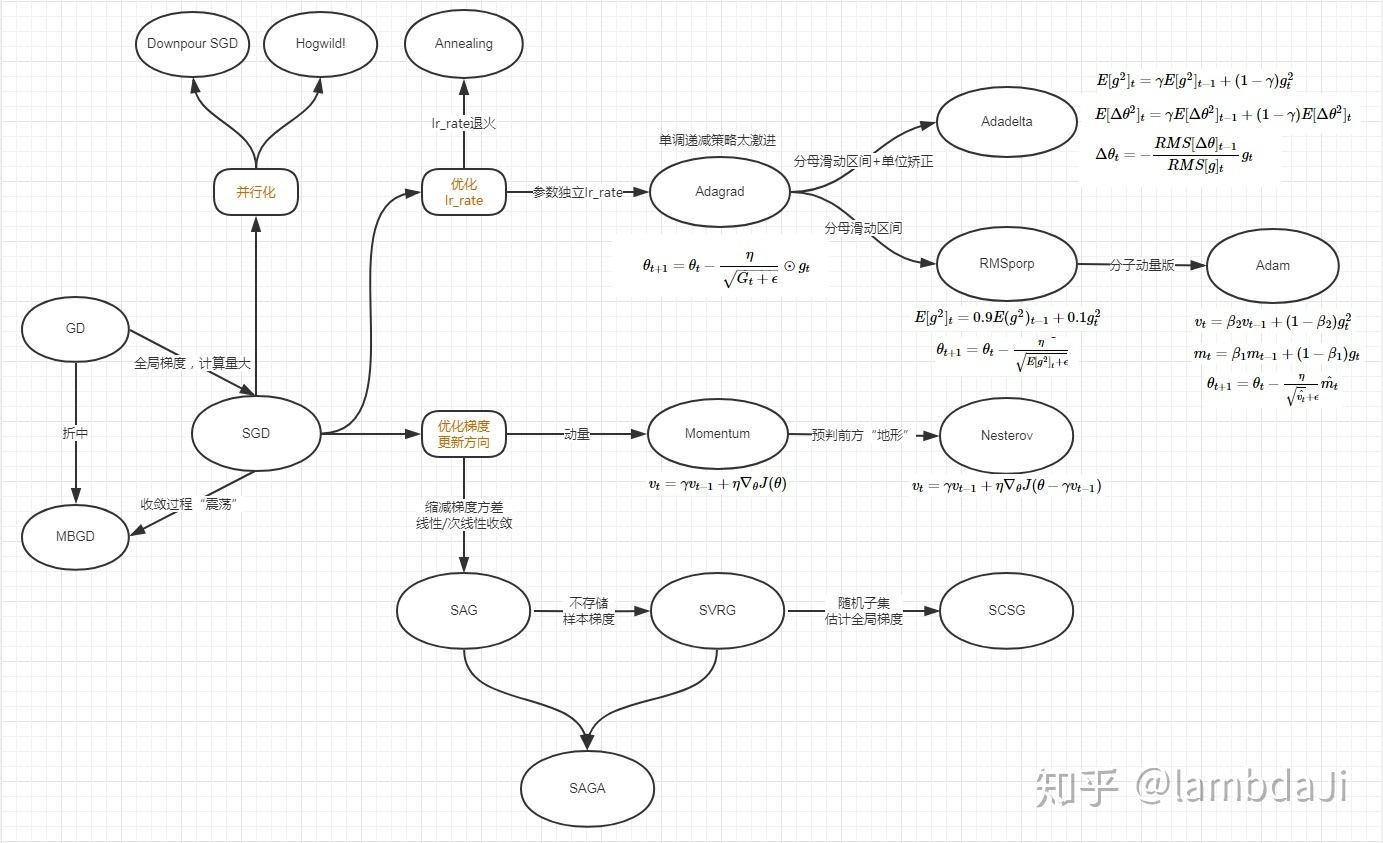
[[Optimization]]
- [[SGD]] 家族
达尔文式
启发式算法,仿达尔文进化论,通过适应度函数进行“物竞天择,适者生存”式优化
比较有代表性的:遗传算法GA,粒子群算法PSO,蚁群算法AA;
适合解决复杂,指数规模,高维度,大空间等特征问题,如物流路经问题;问题是比较收敛慢,工业界很少用。
拉马克式
拉马克进化论,获得性遗传,直接修改基因(w);
比较有代表性的分两类:
sgd variants(sgd/Nesterov/Adagrad/RMSprop/Adam/…)
newton variants(newton/lbfgs/…)
evaluation
一个好的模型需要覆盖的层面
算法层面:准确率,覆盖率,auc,logloss…
公司层面:revenue,ctr,cvr…
用户层面:用户体验,满意度,惊喜度…
模型调优思路
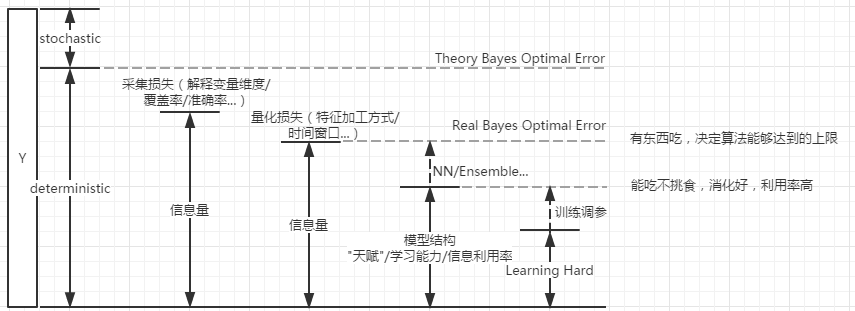
模型效果 ∝ 数据信息量 x 算法信息利用率
扩充“信息量”,用户画像和物品画像要做好,把图片/文本这类不好量化处理的数据利用起来;
改进f(x)提高“信息利用率”,挖到之前挖不到的规律;