GNN的收益来源是什么?
推荐系统优化效果的收益来源 #card
收益总是来源于样本、特征和模型三个方向的一个或多个。
可以再精炼成两个方面,收益要么来源于信息的增加(样本、特征),要么来源于信息利用能力的增强(模型)
例子
- 比如说,一个电影推荐系统,从来没有利用过电影中的演员信息,这时候把演员的信息加入到推荐系统中,很大概率能够带来效果的提升,因为这部分信息是新鲜的,系统从未学习过的知识,这就是 增量信息 带来的收益。
- 我们的推荐模型本来是一个简单的MLP模型,把所有特征通过MLP进行交叉。但用户的行为是一个时间序列,是有前后关联性的,那么改成sequence model就能够更好的表达用户的行为及背后兴趣的变化,这部分的收益就是 信息利用能力 增强带来的。
我们拿一个电影阿甘正传的knowledge graph来说,它的相关导演,演员,风格的信息肯定是重要的。但对于一个成熟推荐系统来说,肯定是已经通过其他形式学习过这些信息了,比如直接把这些side information进行Embedding化之后喂给模型。我们没有必要一定使用GNN来学习这些知识,所以GNN的收益不来自于增量信息。#card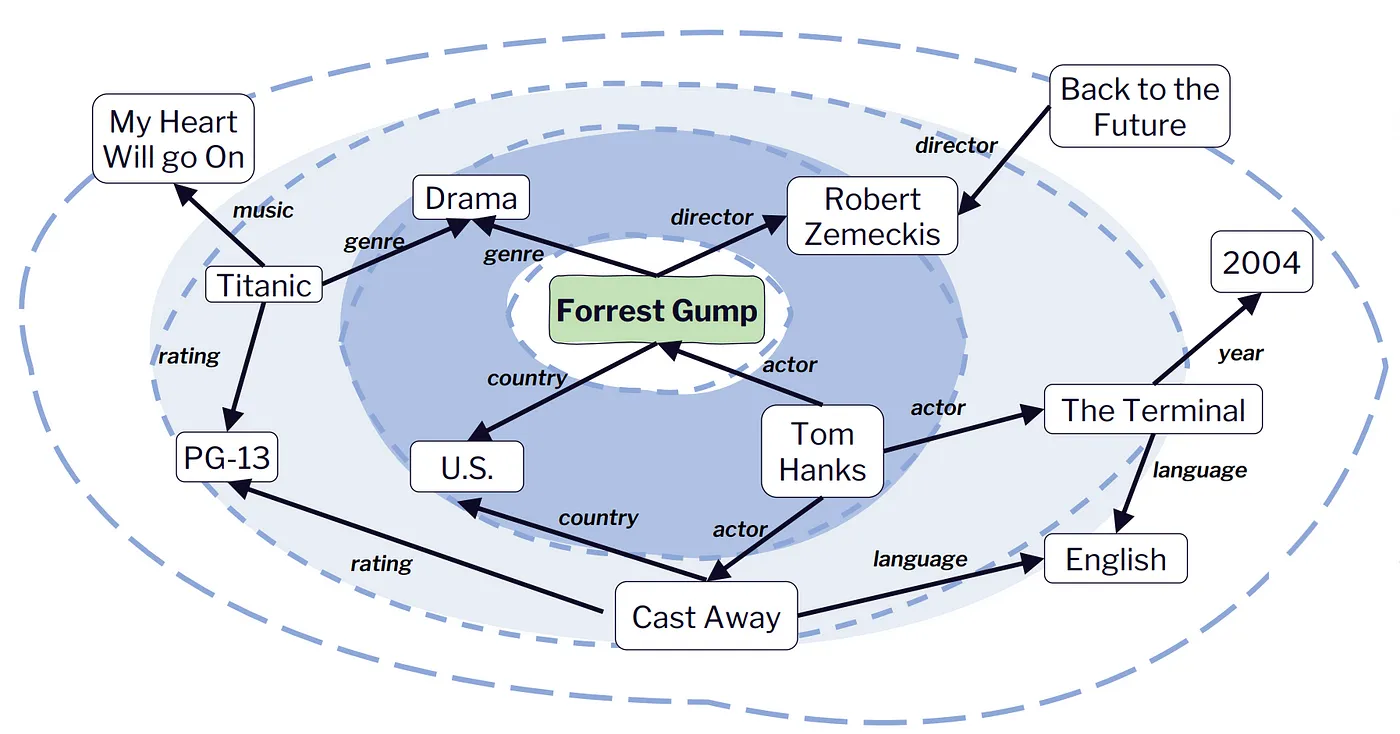
那么GNN如果有收益的话,就一定来自于信息利用能力的增强。
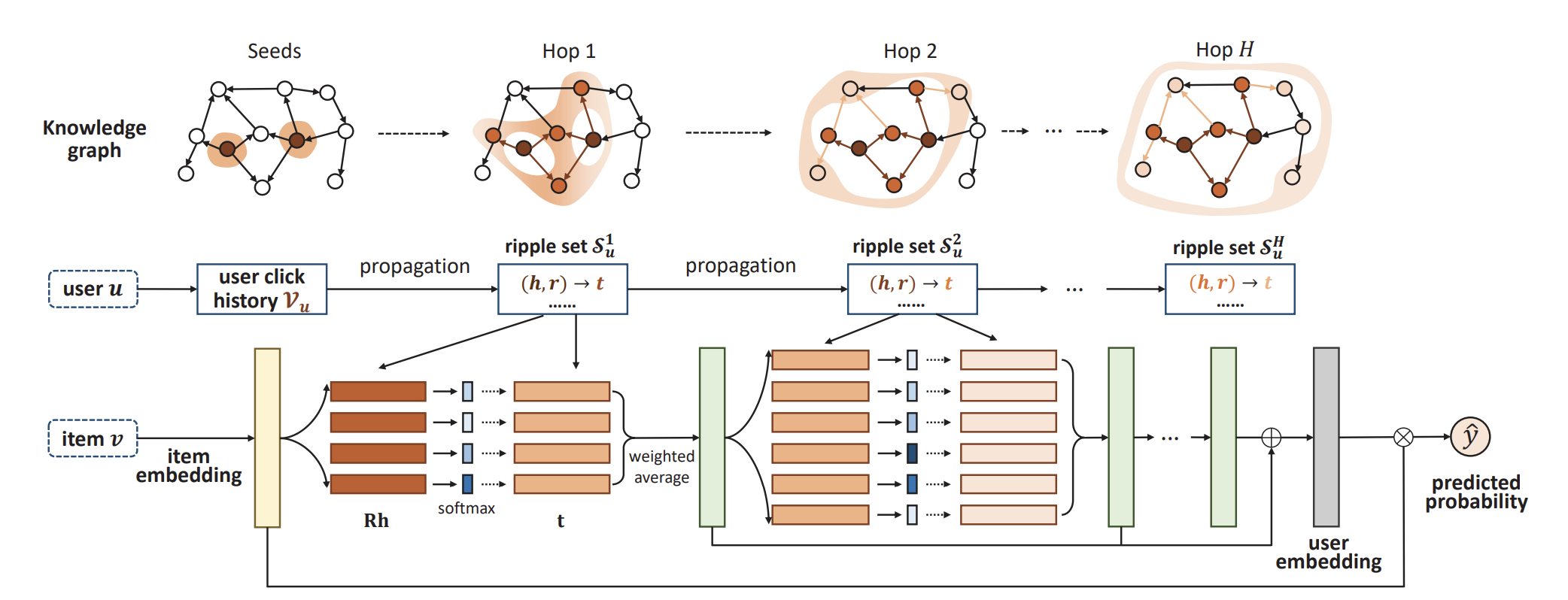
我们拿一个比较经典的GNN方案[[RippleNet]]来说,它一层层的从中心节点扩展学习到周围节点,有二跳、三跳关联关系的学习能力。本质上来说,它利用了knowledge graph点与点之间的拓扑结构,并把拓扑结构中蕴含的关系信息编码到Embedding中去,可以说GNN增强了对知识图谱中关系结构的利用能力,这才是GNN的主要收益来源。#card
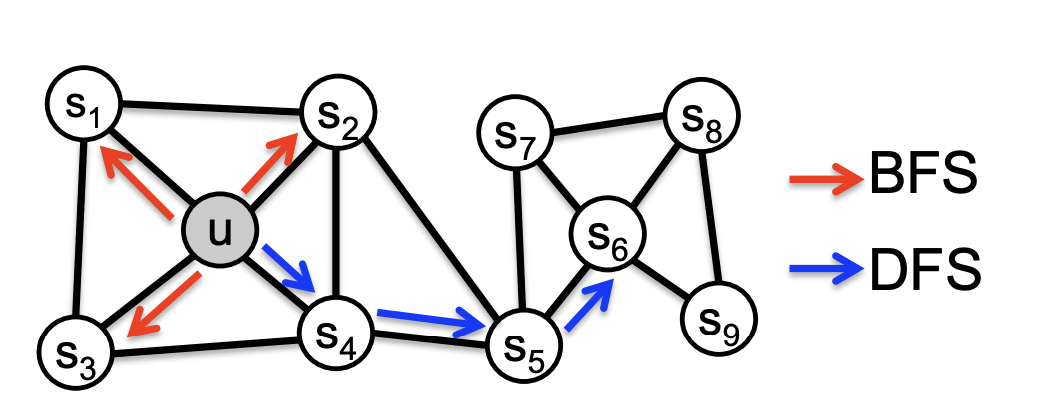
早期基于Random Walk的Graph Embedding生成方案更加纯粹的利用了节点间的拓扑结构。比如Node2vec分别基于BFS和DFS随机游走生成序列后,再进行Embedding编码。所以本质上,Node2vec没有引入任何新的知识信息,而是增强了对关系结构的利用能力。 #card