Spark
[[Resilient Distributed Datasets A Fault-Tolerant Abstraction for In-Memory Cluster Computing]]
一个用来实现快速而通用的集群计算的平台
Spark 任务
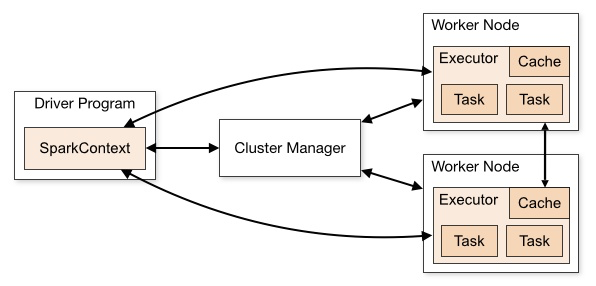
应用程序(Application): 基于Spark的用户程序,包含了一个Driver Program 和集群中多个的Executor;
驱动(Driver): 运行Application的main()函数并且创建SparkContext;
执行单元(Executor): 是为某Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的Executors;
集群管理程序(Cluster Manager): 在集群上获取资源的外部服务(例如:Local、Standalone、Mesos或Yarn等集群管理系统);
操作(Operation): 作用于RDD的各种操作分为Transformation和Action.
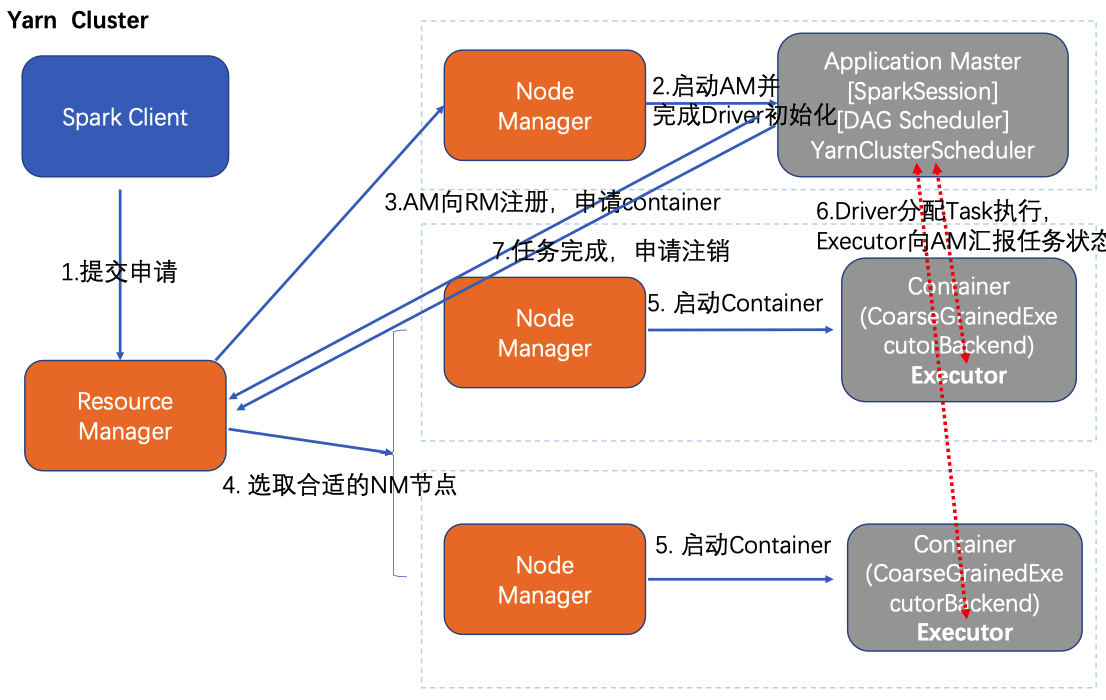
Spark on yarn
- yarn-cluster
- yarn-client
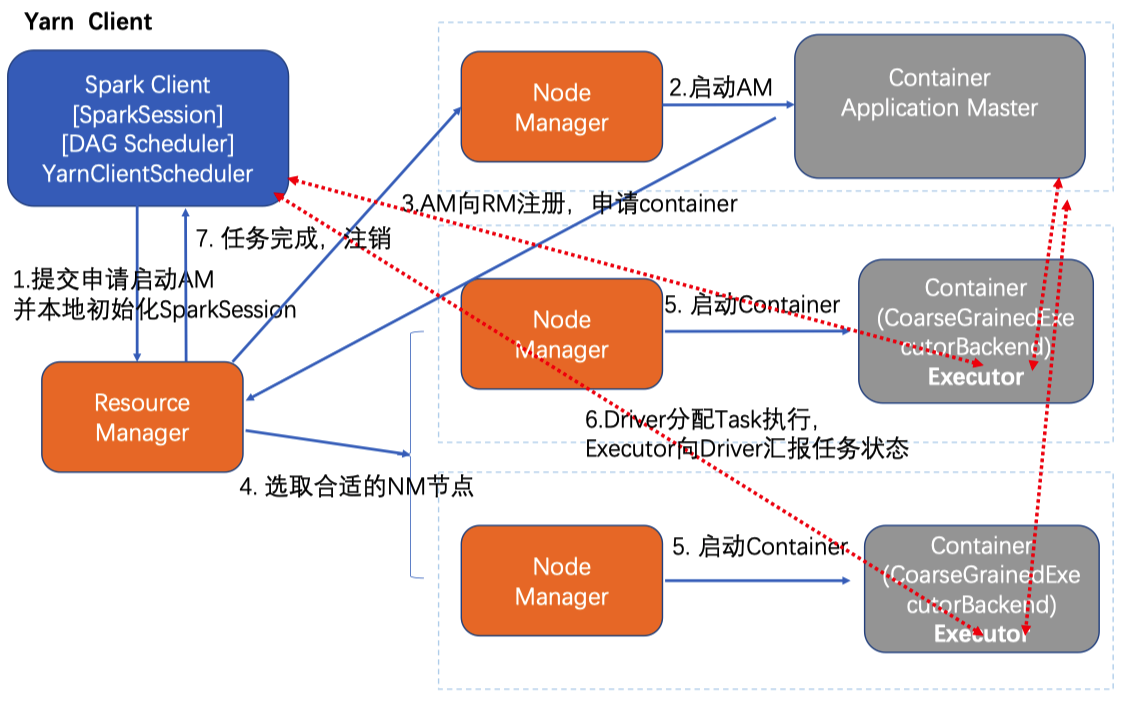
区别 Application Master 作业级别
参数
--deploy-mode cluster/clientcluster 模式 driver 运行在 AM 中
- 关掉 Client,作业会继续在 YARN 上运行,适合生产
client 本地运行,会和 container 进行通信。交互式查询和调试模式
Client 客户端不能退出
AM 向 YARN 请求 executor
spark 作业流程
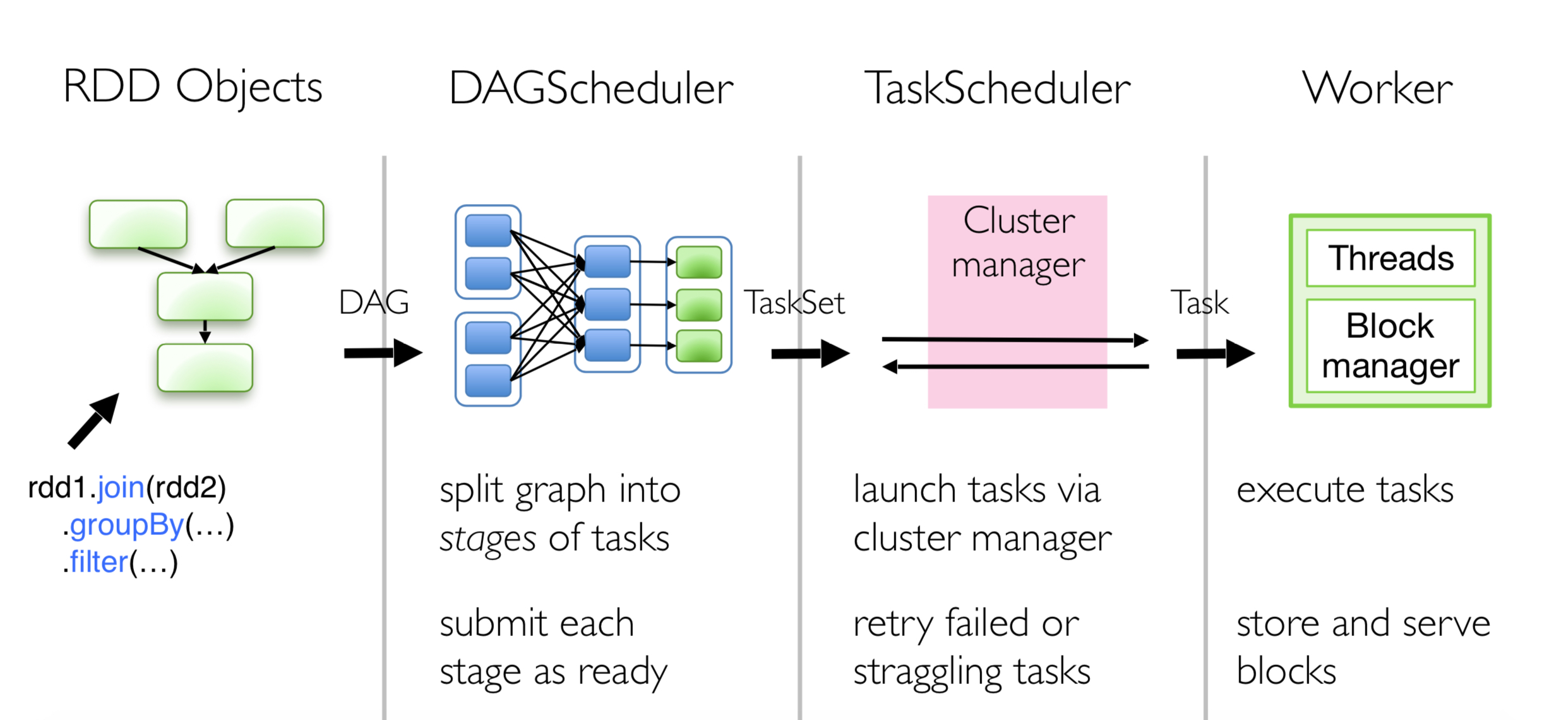
- spark-submit 提交代码,执行 new SparkContext(),在 SparkContext 里构造 DAGScheduler 和 TaskScheduler。
- jar 和 py 上传到 hdfs
- TaskScheduler 会通过后台的一个进程,连接 Master,向 Master 注册 Application。
- Master 接收到 Application 请求后,会使用相应的资源调度算法,在 Worker 上为这个 Application 启动多个 Executer。
- Executor 启动后,会自己反向注册到 TaskScheduler 中。 所有 Executor 都注册到 Driver 上之后,SparkContext 结束初始化,接下来往下执行我们自己的代码。
- 每执行到一个 Action,就会创建一个 Job。Job 会提交给 DAGScheduler。
- DAGScheduler 会将 Job划分为多个 stage,然后每个 stage 创建一个 TaskSet。
- TaskScheduler 会把每一个 TaskSet 里的 Task,提交到 Executor 上执行。
- Executor 上有线程池,每接收到一个 Task,就用 TaskRunner 封装,然后从线程池里取出一个线程执行这个 task。(TaskRunner 将我们编写的代码,拷贝,反序列化,执行 Task,每个 Task 执行 RDD 里的一个 partition)
- 一个 stage 所有 task 执行完毕后,会在节点本地磁盘文件中写入中间结果。
RDD(Resilient Distributed Dataset) 即弹性数据集
Job action 算子划分
Stage 划分
根据 RDD 之间的依赖关系,形成一个 DAG,DAGScheduler 遇到 宽依赖 wide dependency/shuffle
就划分 stage
Task 最小执行单元
运行时的一些概念
mapper
- 加载数据源或[[Shuffle Write]]阶段Task数(默认256M split,数目>=文件个数)
reducer
- Shuffle Read阶段Task数(默认spark.sql.shuffle.partitions=1000,由于开启了AE Shuffle 64M合并,实际数 目<=1000,union创建会N倍增加)
任务并发数
- 默认Executor数*Core数
Spark 划分逻辑图从而生成物理执行图
DAG 有向无环图
从逻辑图最后方开始创建 Stage
遇到完全依赖加入当前 Stage
遇到部分依赖新建一个 Stage
Pipeline 的计算方式
Stage 内部操作只有完全依赖
一个分区数据计算失败或者丢失,可以从父 RDD 对应的分区中恢复
[[Spark/Broadcast]] 数据共享
广播变量:
每个 Executor 节点上复制一份。各个节点可以直接访问本地数据进行计算而不需要通过网络获取。
数据在 Driver 上分块,BlockManager 记录保存在那个节点
Executor 从Driver 上查询数据信息,并拉取。防止同时从 Driver 上拉取信息。
Spark 和 MapReduce 的区别?[[Question]]
[[Hadoop]]一个 task 启动一个进程
MapReduce 过于抽象,高级 API (SQL vs. pandas numpy)
shuffle 的数据集不需要通过读写磁盘来交换,直接保存在内存中。
Hadoop 多轮作业之间无交互,磁盘文件进行数据交互
[[Scala]] 实现
task 如何通过序列化方法发送到远端
运行在 JVM 虚拟机上
Ref