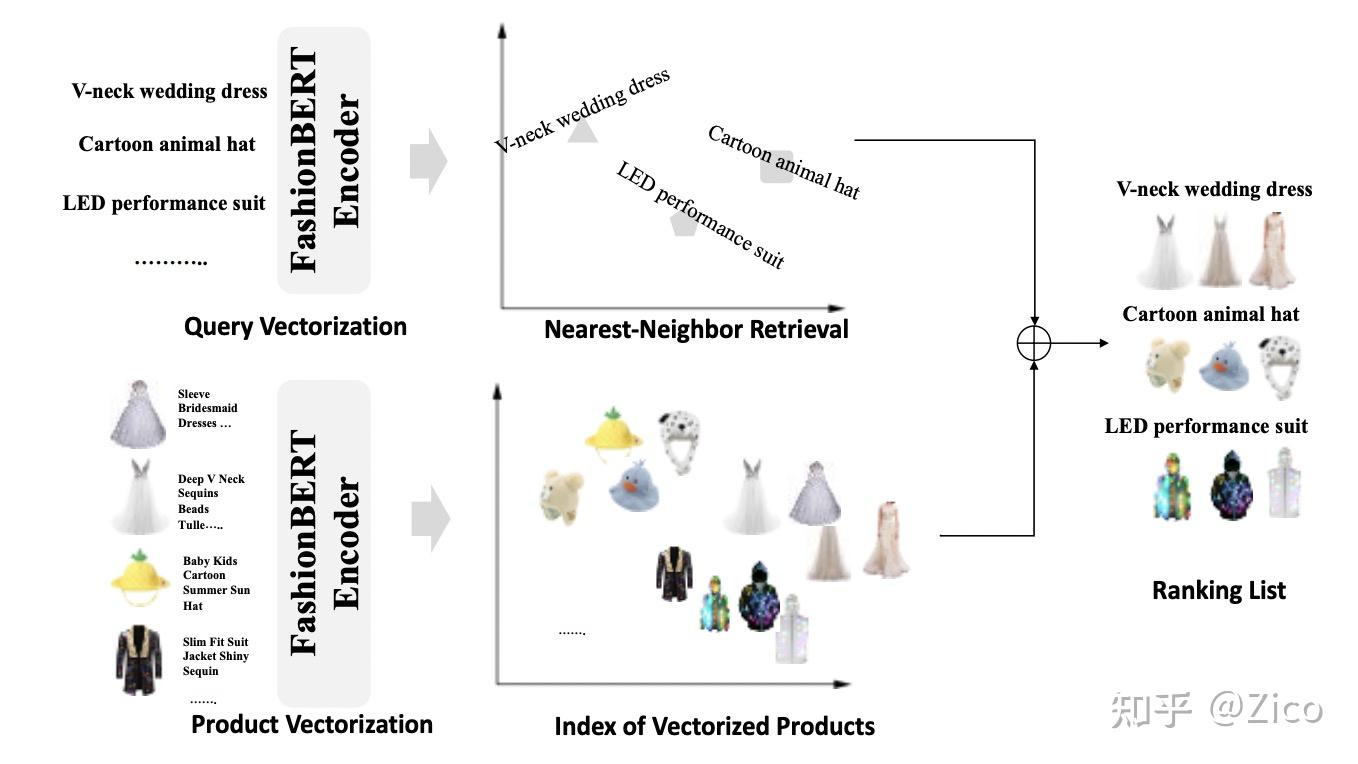
FashionBert
FashionBert和文本模态下的BERT一样,分为预训练和微调两个阶段,为了适应<query, title+image>的匹配,FashionBert在微调之前又增加了triple input的微调。
预训练阶段:#card
和常规的多模态BERT一样,以BERT结构作为encoder,文本模态为商品标题,Tokenize后输入到模型。
视觉模态为商品图片,先通过CNN网络提取成Patch Embedding输入到BERT。
文本和视觉特征输入以[SEP]分隔。
预训练任务包括图文匹配、Mask预言模型任务、Mask视觉特征任务。数据则使用商品维度的<title,image>对即可。
Triple Input微调:在检索任务微调之前,FashionBert先经过了一个<query, titel, image> 三元组输入的微调,以进一步适应<query, title+image>的跨模态匹配任务,训练数据为搜索点击日志构造的query-item信息对,整体结构如下:#card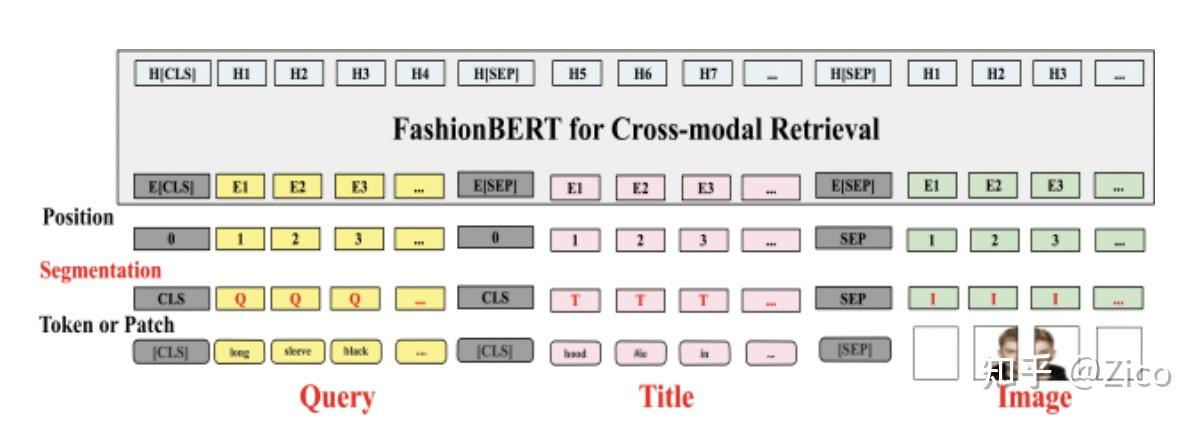
跨模态匹配微调:跨模态微调任务与经典的DSSM架构一致,只是doc端的输入升级为图文特征。query、title、image可以共享同一个BERT模型,以Segment Id区分。训练数据同样为搜索点击日志构造的<query, item>pair对。#card