DIN
Embedding & MLP 模型
embedding layer (for learning the dense representation of sparse features)
MLP (for learning the combination relations of features automatically).
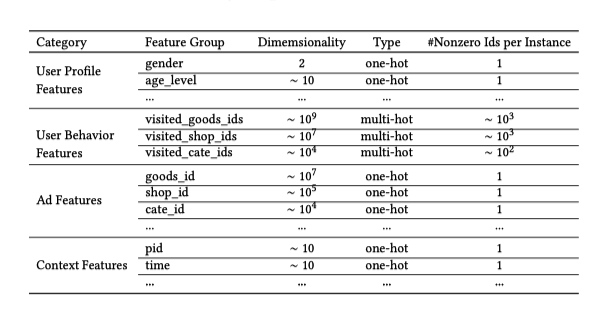
Feature Representation
所使用的特征如下图,没有使用组合特征,所以避免了特征工程。
multi-hot 经过 embedding 层组成一个 embedding list,然后通过 pooling 层(sum pooling or average pooling)变成固定长度的向量。
损失函数:$$L=-\frac{1}{N} \sum_{(x, y) \in S}(y \log p(x)+(1-y) \log (1-p(x)))$$
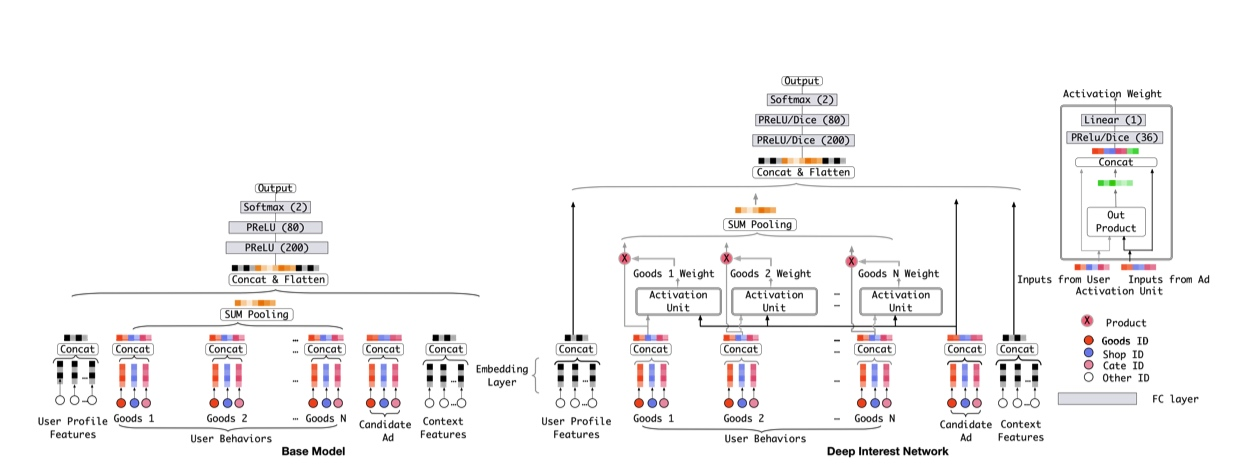
Deep Interest NetWork
base model 中所有的历史行为最后通过 sum pooling 得到固定长度的向量,没有考虑 和候选商品的关系 。固定长度的向量表达能力有限。
用户特征的特点:diverse and locally activated
User Behaviors 通过 SUM Pooling 转化成为定长的向量。
考虑到用户兴趣不是 严格时间关系 ,所以 User Behaviors 没有考虑序列关系。
通过 local acvtivation unit 学习用户历史行为和候选广告的权重 [[target attention]]
$v_{U}(A)=f\left(\boldsymbol{v}{A}, \boldsymbol{e}{1}, \boldsymbol{e}{2}, \ldots, \boldsymbol{e}{H}\right)=\sum_{j=1}^{H} a\left(\boldsymbol{e}{j}, \boldsymbol{v}{A}\right) e_{j}=\sum_{j=1}^{H} w_{j} \boldsymbol{e}_{j}$
- 历史行为和候选广告做叉乘反映两者的 相关性 ,早期版本使用 embedding 差。
- 和传统的 attention 相比,没有使用 softmax 去进行归一化,用来表达用户信息的强烈程度? #card
- 赋予和候选广告相关的历史兴趣更高的weight
商品特征包括 goods_id shop_id cate_id(分类)
网络结构 #card
[[mini-batch aware regularization]]
[[data adaptive activation function]]
Attention 权重可视化 #card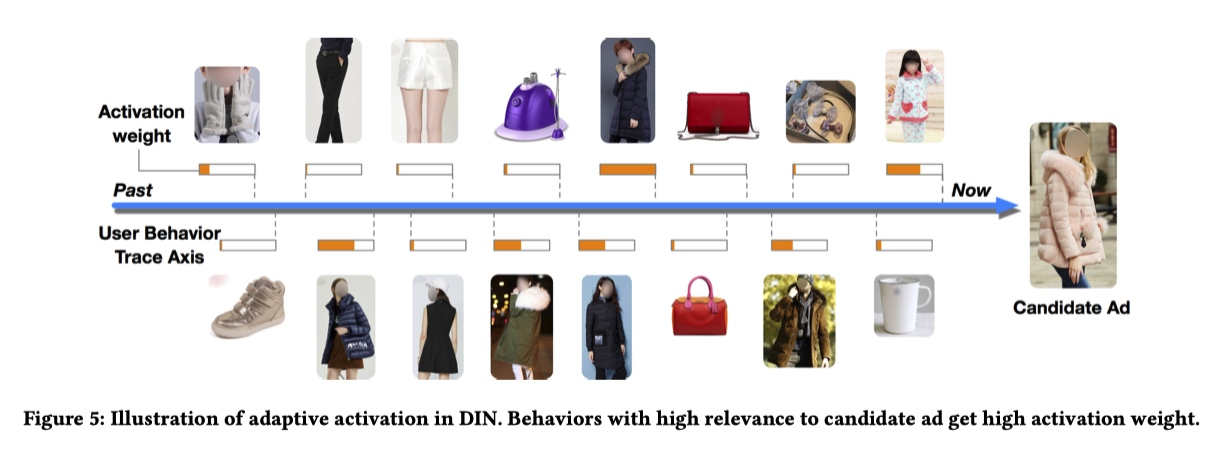
[[Group AUC]]
问题
DIN 模型提出的动机是什么?是否适合自己公司当前的场景和数据特点?#card
DIN 模型的模型结构是什么?具体实现起来有那些工程上的难点?#card
- 用户对应行为序列的获取
DIN 模型强调的注意力机制是什么?#card
- 候选商品和用户行为序列的关系
[[为什么在推荐系统中引入注意力机制能够有效果上的提升?]]#card
动态权重分配,替代平均池化。长短期分配
引入行为序列表达用户兴趣
可解释性与鲁棒性
DIN 模型将用户和商品进行了 Embedding,在实际使用中,应该如何实现 Embedding 过程?#card
与DIN类似的模型有哪些,是否适合当前的使用场景。#card
[[Ref]]