通过 MAML 解决冷启动
MAML是非常适合推荐系统中的冷启动任务的 #card
冷启动显然属于小样本学习的问题,我们希望通过有限几次用户反馈就把新用户、新物料这些新任务学习好。
MAML用于用户冷启动时,每个用户算作一个任务。MAML用于物料冷启动时,每个物料算作一个任务。通过老用户/老物料学习出模型参数的最佳初值,应用于新用户/新物料,使其能够快速收敛至最佳状态。
应用范围改造
常规MAML假设,每个任务都拥有彼此独立的参数(但是共享一套初值)。当遇到新任务时,新任务模型的所有参数都需要初始化,所以,要学习的模板参数包括模型所有参数的初始值。但是这个假设对于推荐模型 :-> 显然是不成立的。
MAML应用于新用户冷启动时,每个用户当成一个任务;应用于新物料冷启动时,每个物料当成一个任务。以新用户冷启动场景为例,假设有新老两个用户,对应两个任务。#card

现代基于深度学习的推荐模型都遵循“底层特征先Embedding,再喂入上层DNN”的经典结构。因此,模型的参数可以划分为不同的部分,在面对不同任务时展现出不同的特性。
首先是上层DNN的各层权重。#card
这部分参数为所有用户、所有物料所共享,经过海量的训练样本的反复训练,可谓“千锤百炼、久经考验”。
新任务的最优选择是复用这些老任务已经训练好的DNN权重,而没理由重新初始化一套全新的参数。
否则,姑且不说闭门造出来的“轮子”质量差,只论每个新用户、新物料都独立拥有一套DNN权重也不经济。
其次,底层特征的Embedding也可以划分为两类,
一类是常规特征的Embedding,比如上面例子中的“性别”“爱好”和“App每天使用时长”都属于常规特征,其特点是,它们的Embedding为多个用户、多个物料所共享。#card
因此,与DNN权重类似,新任务对于常规特征的Embedding应该直接复用老任务已经训练好的,而非重新初始化一套新的,否则质量差,效率低,还不经济。
比如上面例子中的“电影”Embedding、“30~60分钟”Embedding已经被老任务T0充分训练好了,新任务Tn拿来直接用就可以了。
当然不排除新任务会引入一些之前从未出现过的常规特征,比如某新用户的爱好是“去火星吃烧烤”。
这里我们假设模型已经被海量的老任务调教过了,见识过99.999%的常规特征,碰上一两个罕见特征就当异常值直接忽略了。
另一类是特殊特征的Embedding,就是每个用户的User ID Embedding和每个物料的Item ID Embedding。
一来,这些ID Embedding独一无二,极其重要。虽然前面提到的DNN权重和常规特征的Embedding因跨任务共享而被充分训练,但也不可避免地要兼顾多个任务而顾此失彼。#card
- 而一个User/Item ID Embedding为某个用户/物料所独有,全心全意只为一个用户/物料服务,个性化信息保留得最为充分和完整。
二来,正是由于ID Embedding如此重要,新用户/新物料在ID Embedding上的缺失是造成模型冷启动性能不好的重要原因之一。#card
预测时新ID查询不到,预测程序拿一个全零向量当ID Embedding,其中信息含量为0,使模型表现差强人意;
训练时新ID查询不到,训练程序随机初始化ID Embedding,这个随机向量可能需要很多数据,经过多轮训练才能迭代至一个较好的状态,而新用户/新物料又提供不了这么多的训练数据。
将MAML应用于推荐场景时所要做的第一个改进,就是修正其应用范围。#card
对于推荐模型的大部分参数,包括DNN权重和常规特征的Embedding,新任务(即新用户/新物料)应该直接复用老任务(即老用户/老物料)已经训练好的,这样既能保证参数的质量,又能节省资源。所以,MAML完全没必要学习这些参数的最优初值。
对于每个新任务,只有ID Embedding是为这个任务所独有的,无法复用老任务,希望能够从一个最优初值出发,只经过少量数据就快速迭代至最优状态。而这个最优的User ID Embedding或Item ID Embedding的初值,是唯一需要MAML学习的模板配置。
优化目标改造
[[用户冷启动]] 两个阶段
第一个阶段是Cold-Start(为了和通篇所指的广义冷启动相区别,这里称之为“纯冷启动”)。#card
用户第一次向本推荐服务发出请求,预测程序在线上服务的模型的 Embedding层找不到该用户User ID对应的Embedding,就代之以 $\phi$ 喂进模型进行预测。
此时,$\phi$ 直接影响了新用户的初体验。
第二个阶段是Warm-Up(热身)。#card
第一个阶段的用户反馈回传至在线学习(Online Learning)程序,训练程序在Parameter Server中查不到新用户User ID对应的Embedding,就拿 $\phi$ 当初值,利用新用户的反馈数据,通过一次梯度下降就得到了该新用户User ID Embedding的最新值 $\theta^*$ 。
$\theta^*$ 被打到线上,作为新的 User ID Embedding为该用户的第"二"次(理想了一点,假设在线更新足够及时)请求服务。此时,$\phi$ 通过影响 $\theta^{\star}$ 间接影响了用户的第二次体验。
传统 MAML 只关注 warm-up 阶段放弃 cold-start 阶段的优化 #card
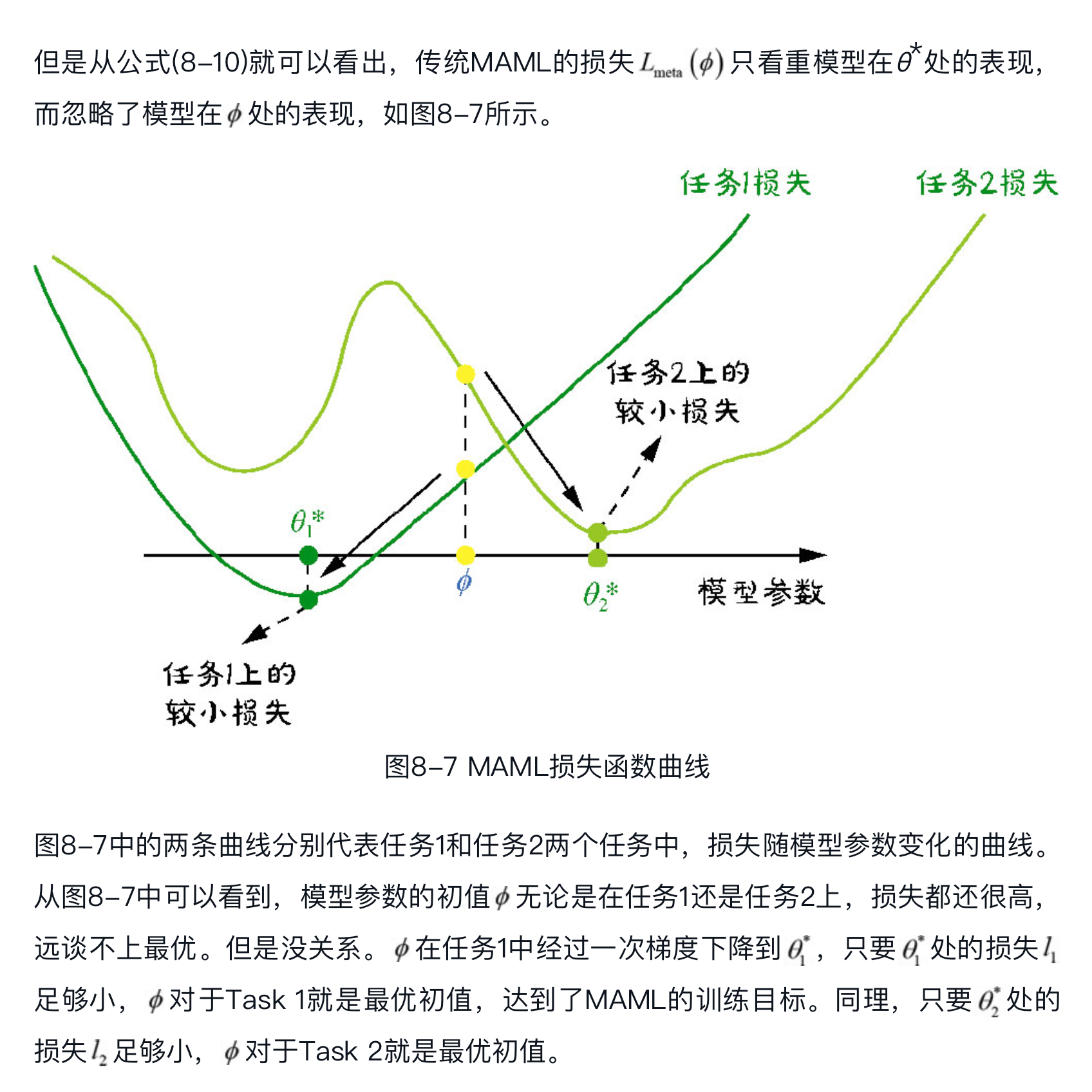
所以,将MAML应用于推荐场景所要做的第二个改进:需要同时关注模型在 $\phi$ 和 $\theta^*$ 处的性能,也就是要兼顾Cold-Start和Warm-Up两阶段。
生成方式改造
- 希望User/Item ID Embedding的初值不再是全局共享的一个向量,而是用户/物料基本信息的函数。使用“个性化”初值对不同用户/物料的ID Embedding进行初始化,将“个性化”进行到底。#card
如果使用传统MAML来学习ID Embedding的最优初值,就只是生成一个全局向量为所有任务共享。
但是在推荐场景下,即使是冷启动,我们也并非对新用户/新物料一无所知。
对于新用户,通过弹窗问卷调查的方式,我们可能获得用户的一些基本属性(如性别、年龄)和兴趣爱好。
对于新物料,通过内容理解算法给物料分类、打标签更是家常便饭。