@第3章 精排之锋
3.1 逻辑回归模型
为什么逻辑回归中激活函数使用了Sigmoid,是因为它的值域在0~1。但是仔细思考一下:是不是只要输出在0~1,什么激活函数都可以呢?比如可不可以先用tanh函数把输出范围约束在[-1,1],再线性变换到[0,1]呢?#card

为什么推荐的本质是“复读机”,而CV、NLP就不是吗?#card
对,因为推荐存在不确定性,必须要试错才能知道真值,而且很难归因。
CV、NLP中的真值(或者也可以说标注)是固定且显然的。以图像识别任务为例,一幅图像里面的主体是猫就是猫,是狗就是狗,很清晰,不存在偶然性;
而在推荐中,对于某用户和某物料的组合,人工判断是否点击是很难的,只有试试才知道。
这样必须试错的机制不但造就了推荐“复读机”的本质,还造就了它探索与利用及冷启动的问题。当点击发生时,归因也很难,观测到了一个点击,是因为用户的点击倾向高,还是因为物料的质量好,还是因为某种巧合呢?
模型也无法归因,在上面的例子中用户1对物料1也许只是随手一点,而模型也只能增大物料1的权重(认为它更好)。
3.2 工业逻辑回归模型的稀疏性要求
截断梯度(Truncated Gradient,TG)法,2008, Yahoo
前向后向分离(FOBOS)法[插图]是谷歌发表的工作
正则化对偶平均(Regularize the Dual Average,RDA)法[插图],即RDA算法由微软亚洲研究院提出
谷歌提出的Follow The(Proximally)Regularized Leader([[FTRL]])算法
3.3 FM
20世纪90年代左右开始到21世纪10年代,支持向量机(Support Vector Machine,SVM)都占据着核心位置,但在推荐算法领域它却很少被提及,这是为何呢?#card
SVM是一个二阶的方法,有特征做基础,再去拟合分类面;
而逻辑回归模型和FM则不是,与其说是在学习特征的权重,倒不如说可以把权重看作特征本身。
在在线学习的过程中,如何得到特征的表示其实不太明确,而且表示随时在变化。
如果想使用SVM,没有一个既定的特征表示,用SVM就很别扭。
另外,随着新样本的加入,如何移动分界面也是一个需要解决的问题。有一些文章试图在推荐场景下使用SVM,但是都没有给出特别漂亮的形式。
为什么在DNN为主的时代,SVM消失了,逻辑回归模型几乎消失了,但是FM还在呢?#card
本质原因是点积不能被DNN很好地替代,
[[Neural Collaborative Filtering vs. Matrix Factorization Revisited]] 这篇文章做了详细的实验来验证。实验中,点积的效果都好于MLP,这说明点积的信息不容易被MLP覆盖。
#card FM向高阶的自然扩展就是Higher-Order Factorization Machines[[HOFM]],在原来的FM中二阶的特征是两个特征乘起来,再乘上它们嵌入的内积,以此类推,可以设计出第n阶的交叉关系
- $$
\sum_{i, j, k, \cdots \in S} \operatorname{sum}\left(v_i \odot v_j \odot v_k \odot \cdots\right) x_i x_j x_k \cdots
$$
- $$
3.7 树模型
很少在实际业务的精排中看到树模型的身影,这是为什么呢?#card
因为树模型不能很好地处理在线学习过程中源源不断出现的新的ID类型的特征。
虽然XGBoost和LightGBM都谈了对未训练的值如何处理,但在实际场景中,这种特征的量可能会非常夸张。树模型处理新出现的ID特征有点进退两难:如果把没出现的值都用默认值填充,随着时间推移,默认值的占比会越来越大,模型会逐渐劣化;而如果出现新值就重新训练,又和在线学习的精神相违背,怎么处理都不自然。从冷启动的角度来想,如果希望我们的平台是富有活力的平台,就理应源源不断地出现新物料,那么冷启动的规模就更大。在现在的大平台上,新物料的比例可能远远超过50%,在这么大的未见过的样本面前,树模型就显得捉襟见肘了。不能很好地解决这个问题,树模型就不能负担得起精排的重任。
在前一节“Practical Lessons from Predicting Clicks on Ads at Facebook”中其实就说了,他们的树模型是一天一更新的[插图]。这个方案当然体现了他们对问题的深入思考,但也不是完美的解法。#card
如果树模型后面接的环节是一天的重新训练不能收敛的,同样的方案还能用吗?
那么现在主流的精排模型怎么解决这个问题呢?答案就是嵌入,每当新出现了ID,都可以开辟一段新的空间来存储,让这段嵌入保留该特征的信息。
一个新嵌入的加入,虽然会引发冷启动问题,但是对于训练、部署的流程结构没有任何改动。因此,基于嵌入的Embedding+DNN范式几乎无往不利。
当触发以下两个条件时,可以优先考虑树模型。#card
(1)特征中没有不断新增的ID类特征,且类别型特征可以穷举,如年龄、城市等。
(2)当输入的特征混有各种各样的类别型、数值型(Numeric)等类型的特征时,尤其对于像计数类特征(如用户在App上的行为次数)等类型很有效果。
3.8 再论特征与嵌入生成
在阅读论文时,判断其中所讲的算法适用于学术界还是工业界,有两个参考问题:#card
①该论文的特征机制如何处理源源不断的新的特征或新的ID?
②该论文的训练机制是否与在线学习的习惯冲突?
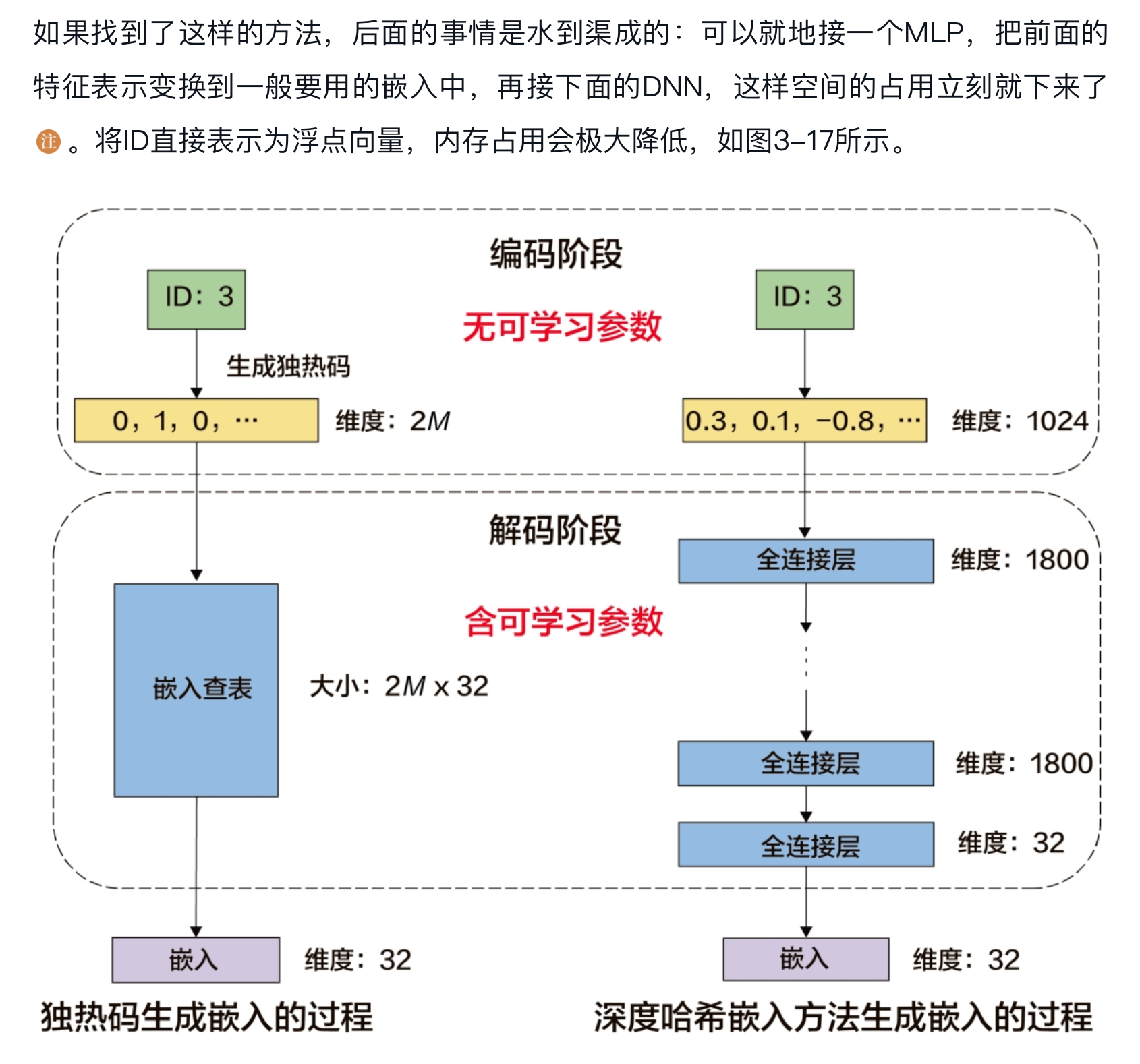
Facebook发表在KDD 2020上的方案,它把一个大的ID拆解成商+余数的组合 #card

将ID直接表示为浮点向量,内存占用会极大降低#card
- 如果我们有一个非学习性的方法一开始就把特征ID表示成浮点数会怎么样?如果能表示成一段浮点数的向量会怎么样?
3.11 注意力机制的几种写法
关于注意力机制,我们要解决两个问题:#card
①怎么做,在哪个层面上做?
②注意力系数如何得到,由谁来产出?
注意力机制在推荐系统中可能得作用 #card
(1)凸显用户的兴趣峰。
(2)特征进一步地细化/抽象。
(3)对模块进行分化。
- 注意力机制下的常见操作是根据输入的不同,生成不同的权重,来决定后面模块中突出的是谁,抑制的是谁。反过来说,只要注意力系数的分布不是一成不变的,后续的模块也会对输入产生特殊的倾向。某种输入产生了大的注意力系数,那么对应位置的模块相当于更多承担了这种输入的预测。久而久之,不同的模块会对不同的用户/任务有所专注,这就是所谓的分化。
注意力机制应用广泛的本质原因是 #card
求和的普遍存在,只要是有求和的地方,加权和就有用武之地。
注意力机制的本质可能是极其紧凑的二阶“人海战术”,或者是极其高效的复杂度置换提升的方法。
为什么“人海战术”有用 #card

注意力机制总是有用的?#card
有读者可能会说,因为它具有更高程度的个性化/非常符合人的认知。这样的道理当然没错,但是要注意,这些说法只能说明注意力机制可能有用,或者大概率有用,不能推导出它如此有用。现在的现状是什么呢?太多地方都在用注意力机制,有点太好用了,这不是上面的浅显道理能解释的。从CV领域的SENet到NLP领域的MHA,似乎注意力机制是哪里都能用的。而且最奇怪的点是,自我注意力机制(作用的对象和生成注意力系数所用的特征都由相同的输入决定)也是很有效的,如SENet这样的做法。这不是很奇怪吗?没有添加额外的信息就能取得提升,看起来简直像是天上掉馅饼了?
笔者有两点假说,供大家讨论:
注意力机制的本质可能是极其紧凑的二阶“人海战术”,即注意力机制有效的本质原因其实是“人海战术”十分有效。可以把注意力机制看作只有两个成员的“人海战术”,一个成员组成特征图,另一个成员组成注意力得分,并且相互交叉乘起来的形式是只有两个成员情况下的最优(或者极优)形式。
注意力机制是一种效率极高的复杂度置换性能的方法。虽然注意力机制的量级很轻,但它终究还是加了东西的。这些东西加在特征维度上、加在通道上,都不如做成掩码效率高。这个假说和上面的不是互斥的,而是存在重叠的。
3.12 Transformer的升维打击
- 在推荐系统中,用户特征大于物料特征,行为特征大于 画像特征 ,用Transformer实际上是“大炮打巨人”。
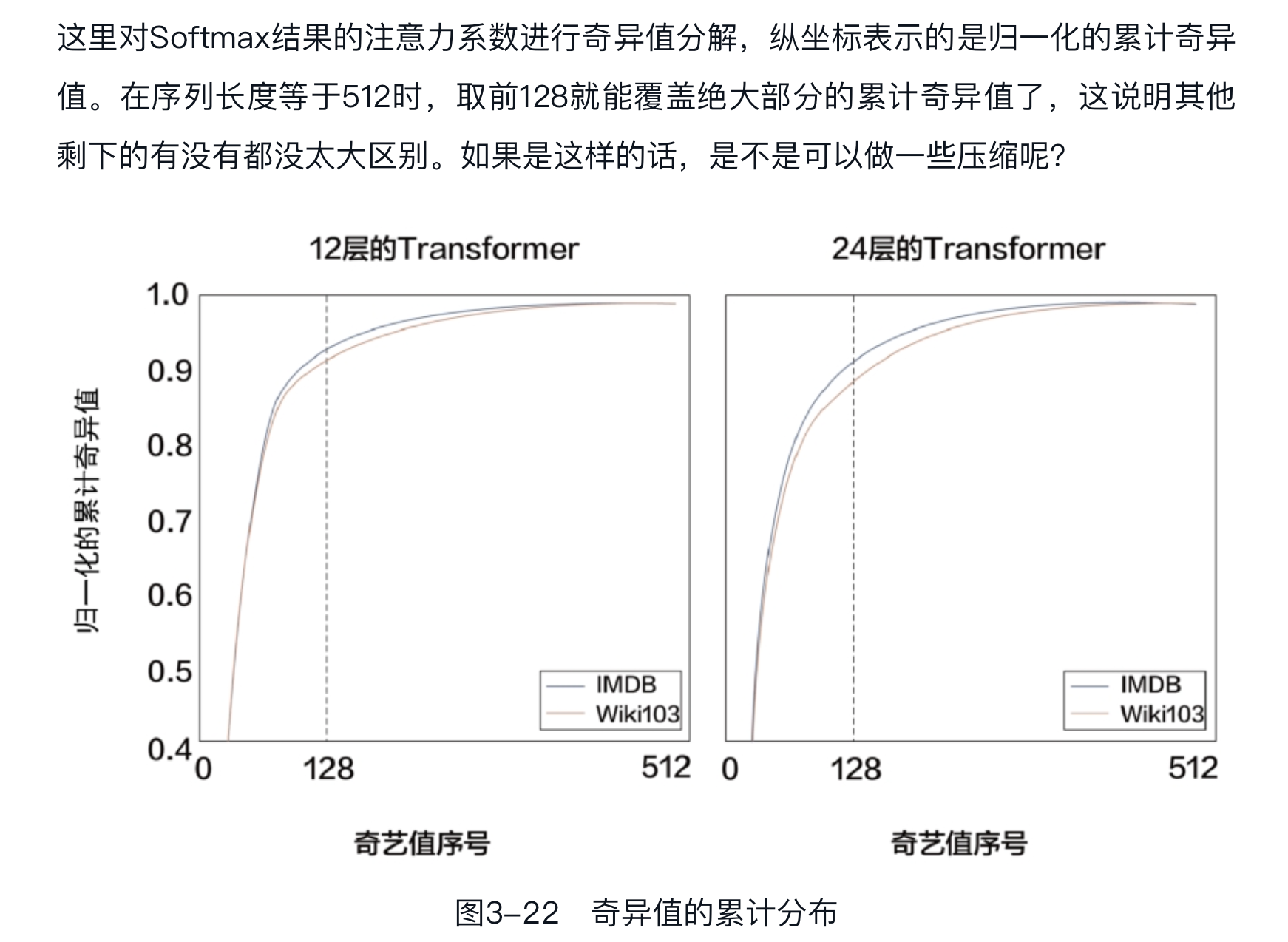
- 在序列长度较长时如何加速计算成了一个课题,这方面目前比较新的工作是Linformer[插图],这篇文章中最重要的知识是低秩的观察,奇异值的累计分布如图3-22所示。#card

Transformer已经席卷机器学习的各个领域了[插图],甚至连CNN都有抵挡不住的趋势。我们前一讲所介绍的各种注意力机制的做法都没有这么厉害,似乎种种证据都表明MHA就是比它们好,这是为什么呢?#card
重新观察MHA的结构,第一个区别是它的注意力系数是由两个部分组成的,而不是像传统做法一样由输入直接生成。再加上后面的V,Transformer是由三个部分综合得到的。
所以如果3.11节关于“注意力机制是极其紧凑又极其高效的二阶‘人海战术’”的假说是成立的,那么就可以类比来说MHA是高效的三阶“人海战术”,多了一个成员,形成了“升维打击”。
此外,在MHA中,注意力系数作用的对象和输入之间还加了一层变换,对输入的改变更加抽象。
最后MHA通过加入多头还达到了“人海战术”的效果,总体看下来,MHA比上一节我们介绍的其他注意力机制的环节多了2.5个维度。