@第9章 非梯度场景
非梯度场景定义 #card
- 反馈不以样本为单位,也不直接以梯度的形式。
非梯度场景的解决方案:#card
广泛地搜索每一个任务的参数,根据线上的反馈调整到更好的结果。
一个字,“探”;
两个字,“投针”;
四个字,“蒙特卡罗”;
五个字,“探索与利用”。
集成排序:只参考排序不参考数值 $y=\sum_i w_i \operatorname{Rank}\left(\mathrm{XTR}_i\right)$ #card
假设有两个候选在两个队列的原始分数分别是0.9、0.8和0.2、0.1。
先把分数变成序号,再取倒数,4个值的Rank函数的输出分别变为1、0.5、1、0.5,
这样就把值域变化很大的几个任务放到同一个空间里,即Rank函数相当于做了归一化处理。
[[cross entropy method]] #card
把所有任务的权重综合起来,可以组成高维空间中的一个点,而每个点都有其对应的线上性能。
先随便用几个来探测一下,之后根据它们所表现出的性能来决定下一次探测哪里,这样一步一步调整到最好的位置。
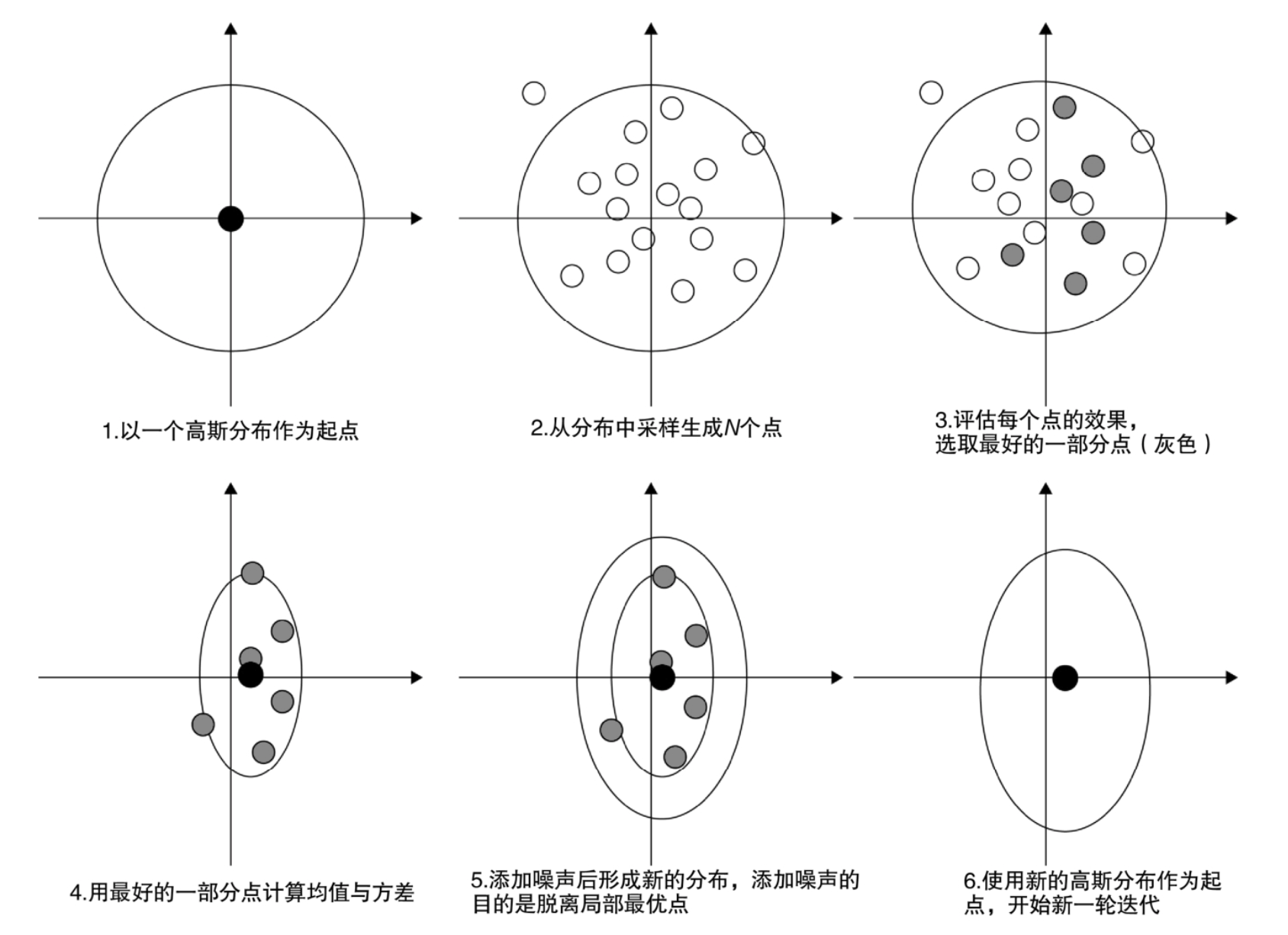
(1)以一个高斯分布作为起点,在一开始可以随机生成一个。
(2)从上述分布中采样生成N个点。
(3)给每个点都分配一些流量,然后去探索。比如在线上实验时,CEM整体使用10%的流量,这里用5个点来探测,那么每个点就分到2%的流量。经过一段时间的观察,挑出表现最好的若干个点。这里的“表现最好”就按照我们指定的线上目标来体现,这就把线下和线上联系起来了。
(4)从所有点中挑出表现最好的几个点再拟合一个新的高斯分布。
(5)加点噪声,使它们有机会脱离局部最优点。
(6)用新拟合出来的高斯分布重新开始下一轮迭代。
CEM 算法注意事项 #card
(1)CEM每次生成的几个点都是在同期比较的,同期比较可以避免被推荐系统的时变性干扰(如昨天的结果和今天的结果不具备可比性),但同期探测的点太多会让每一个点的流量变少从而使结果波动变大,需要权衡。
(2)这个方法只考虑线上表现(相当于强化学习中的奖励)的优劣关系,不对数值建模,更不建模高阶量,因此非常鲁棒。
(3)虽然自己拟合了一个高斯分布,但也考虑了建模过程中的误差,可以施加扰动继续探索。
从整体上看CEM算法,它是否接受反馈?#card
是的,它根据线上的表现来调整下一次生成的参数。但是,它既不是以梯度的形式反馈的,也不是以样本级的形式反馈的,这就是非梯度场景的一种解决方案。
虽然线上和线下的鸿沟有复杂的对应关系,弄清楚其中的联系非常难,但我们可以把CEM当作一个黑盒子,按照不停地试+调整的路线从大体上去掌控。
还有很多经典的场景都属于非梯度场景,#card
如出价策略。设想我们开发的一款App要去做推广,这时就要有一套策略,但是反馈一定是积累了足够长时间才能拿到的,这就已经脱离了样本级的优化。
类似地,像冷启动广告的定价应该如何制订策略,在自然结果中插入广告的频率如何调整等问题都属于非梯度场景。