embedding 和 ont 如何对比?
基于词向量的固定表征:word2vec、fastText、glove
基于词向量的动态表征:elmo、GPT、bert。
[[DSSM]] 保证 user 和 item 在同一个向量空间,之后可以进行计算。
基于 embedding 的召回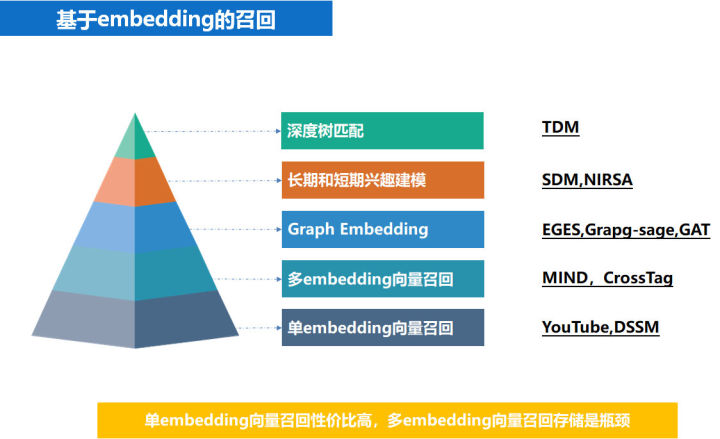
- [[i2i 召回]] 算法
- tag2vec:取文章的部分标签向量代表文章的向量(对应多个 embedding 如何处理)
- item2item 计算:faiss 计算每篇文章的相似文章
- content i2i
- 其他召回和这个套路类似,就是训练 embedding 向量的时候,略有差异。tag2vec 是训练中文词语的向量,而 item2vec 是训练文章 ID(aid)所对应的向量,media2vec 训练的是文章的作者 ID(mid)所对应的向量,loc2vec 是训练地域名称所对应的向量,title2vec 是用 LSTM 训练得到的文章标题向量,doc2vec 是用 bert 计算出的文章正文(或者摘要)的向量。entity2vec 是利用我们自己构建的知识图谱通过 transE 得到的
- u2i 召回
- 分群召回
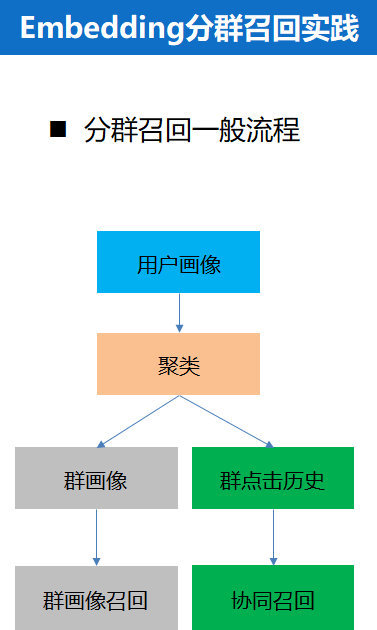
- 方法
- 簇召回,用户 tag 用聚类算法聚成若干个簇
- 方法
- 增量聚类
其他
- [[Youtube DNN]] 是开山之作
- 所有特征(无论离线连续,单值多值)全部转化为 embedding,
- 把各种 embedding 拼接在一起构成一个向量送入 dnn。
- Airbnb 在稀疏样本构造上有所创新。
- 分群 embedding
- 用户和 item 混合训练
特征 embedding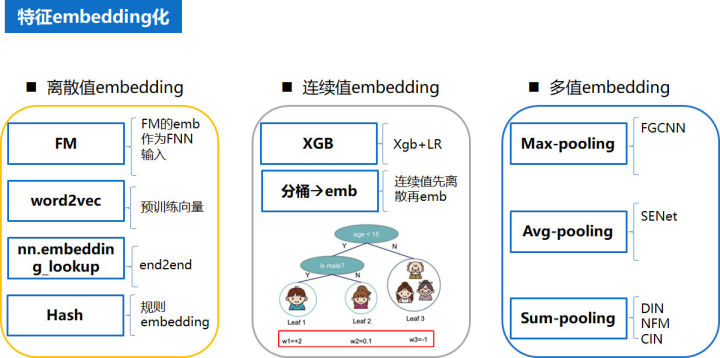
+
embedding 运算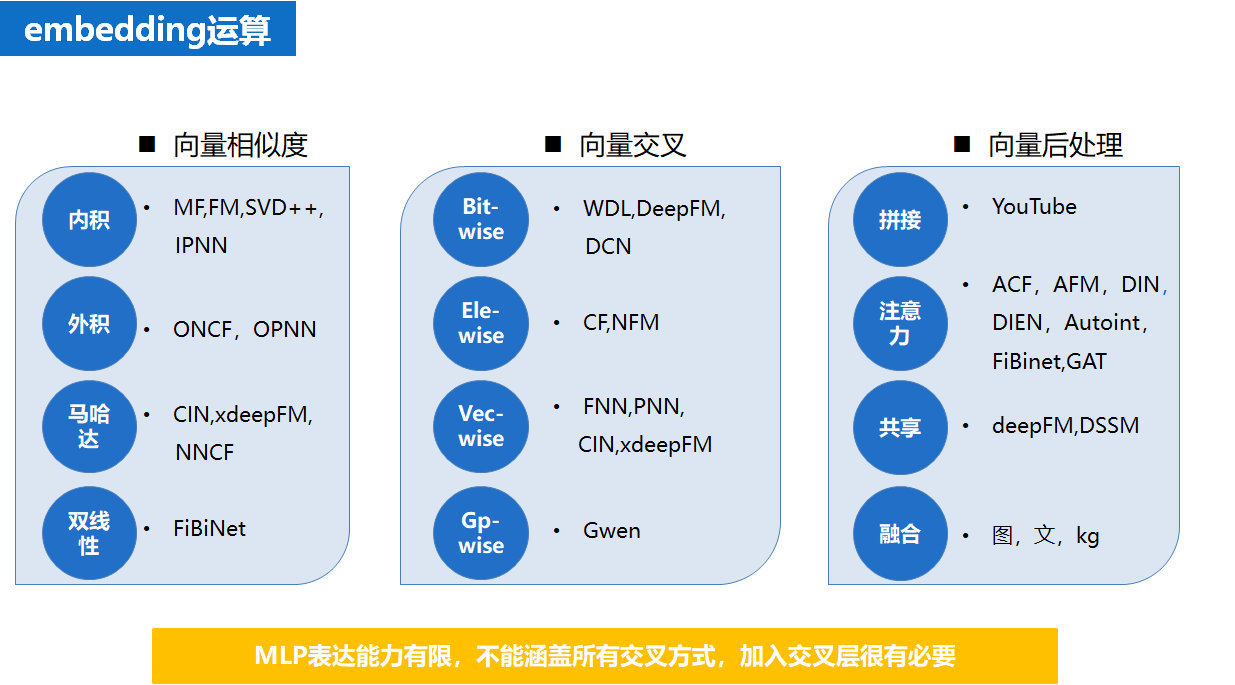
embedding 痛点
- 增量更新的语义不变性
- 很难同时包含多个特征
- 长尾数据难以训练
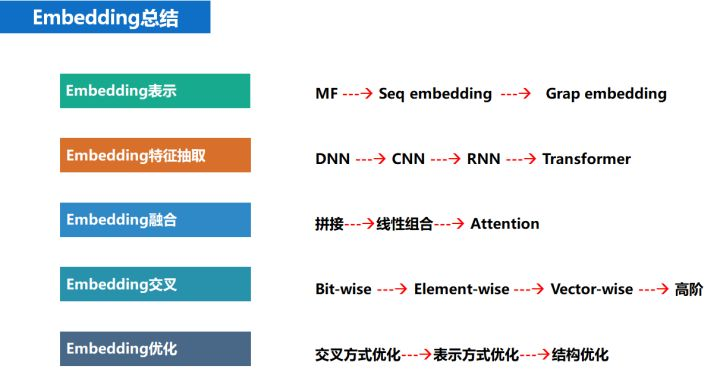
embedding 总结 #card