Practical Lessons from Predicting Clicks on Ads at Facebook(gbdt + lr)
主题:Facebook 2014 年发表的广告点击预测文章。最主要是提出经典 GBDT+LR 模型,可以自动实现特征工程,效果好比于人肉搜索。另外,文章中还给出一个 online learning 的工程框架。
问题:
- GBDT 如何处理大量 id 类特征
- 广告类对于 user id 的处理:利用出现的频率以及转化率来代替
- id 特征放在 lr 中处理。
- GBDT+LR 和 RF+LR 的区别
- 选出能明显区分正负样本的特征的变换方式,转换成 one hot 有意义
- RF + LR 可以并行训练,但是 RF 中得到的区分度不高
收获:
- 数据支撑去做决策,收获和实验数量成正比。
- CTR click through rate,点击率
- 评价指标:
- Normalized Entropy:越小模型越好
- Calibration:预测点击数除以真实点击数
- AUC 正样本出现在负样本前面的概率。
- 数据新鲜度:模型天级训练比周级训练在 NE 下降 1%。
- GBDT 和 LR 模型采用不同的更新频率,解决训练耗时不同。但是 GBDT 重新训练之后,LR 必须要重新训练。
网络:
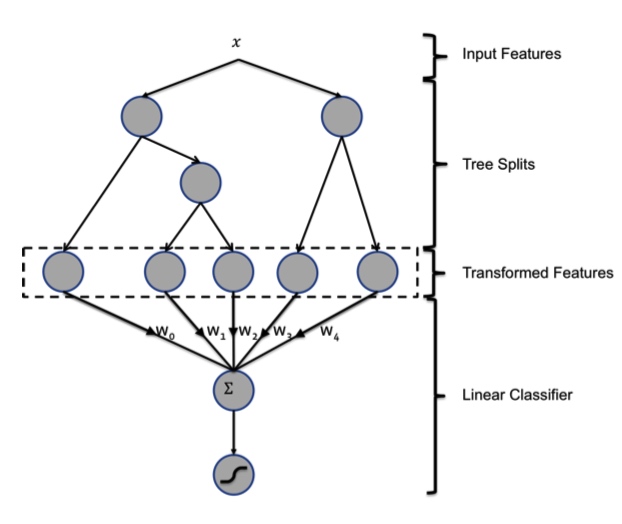
GBDT + LR
利用 GBDT 模型进行自动特征组合和筛选,然后根据样本落在哪棵树哪个叶子生成一个 feature vector 输入到 LR 模型中。这种方法的有点在于两个模型在训练过程从是独立,不需要进行联合训练。
GBDT 由多棵 CART 树组成,每一个节点按贪心分裂。最终生成的树包含多层,相当于一个特征组合的过程。根据规则,样本一定会落在一个叶子节点上,将这个叶子节点记为1,其他节点设为0,得到一个向量。比如下图中有两棵树,第一棵树有三个叶子节点,第二棵树有两个叶子节点。如果一个样本落在第一棵树的第二个叶子,将它编码成 [0, 1, 0]。在第二棵树落到第一个叶子,编码成 [1, 0]。所以,输入到 LR 模型中的向量就是 [0, 1, 0, 1, 0]
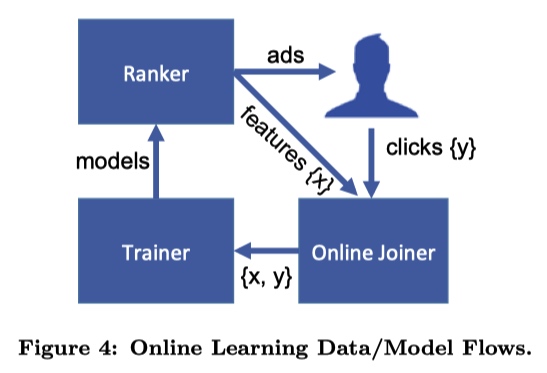
Online Learning
文章中提到的 Online Learning 包括三个部分:
- Joiner 将每次广告展示结果(特征)是否用户点击(标签) join 在一起形成一个完成的训练数据;
- Trainer 定时根据一个 small batch 的数据训练一个模型;
- Ranker 利用上一个模块得到模型预测用户点击。
注意的点:
- waiting window time:给用户展示广告之后,我们只能知道用户点击的广告,也就是模型中的正样本。负样本需要设置一个等待时间来判断,即超过某一个时间没有观测到用户点击某一个广告,就认为这是一个负样本。另外设置这个时间也是一个技术活,时间过短导致click没有及时join到样本上,时间太长数据实时性差以及有存储的压力。最后,无论如何都会有一些数据缺失,为了避免累积误差,需要定期重新训练整个模型。
- request ID:人家的模型是分布式架构的,需要使用 request ID 来匹配每次展示给用户的结果以及click。为了实现快速匹配,使用 HashQueue 来保存结果。
- 监控:避免发生意向不到的结果,导致业务损失。我们的实时模型也在上线前空跑了好久。
实验:
有无 GBDT 特征对比
训练两个 LR 模型,一个模型输入样本经过 GBDT 得到的特征,另外一个不输入。混合模型比单独 LR 或 Tree
学习率选择
5 种学习率,前三个每一个特征设置一个学习率,最后两种全局学习率。
结果:应该给每一个特征设置一个不同的学习率,而且学习率应该随着轮次缓慢衰减。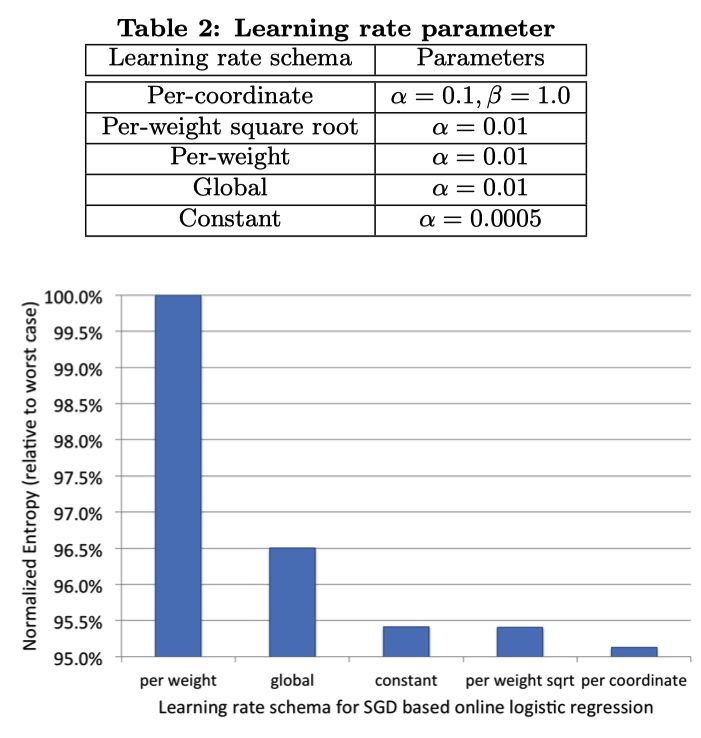
GBDT 参数相关实验
- 前面的树会带来大量的收益,但是树越多训练越慢。
- 特征重要程度,累加不同树上某个特征的得分减少贡献。
- 两种特征:
- 上下文,冷启动的时候比较重要,与数据新鲜度有关。
- 历史史特征,权重比较大,关键在于长时间积累。
采样
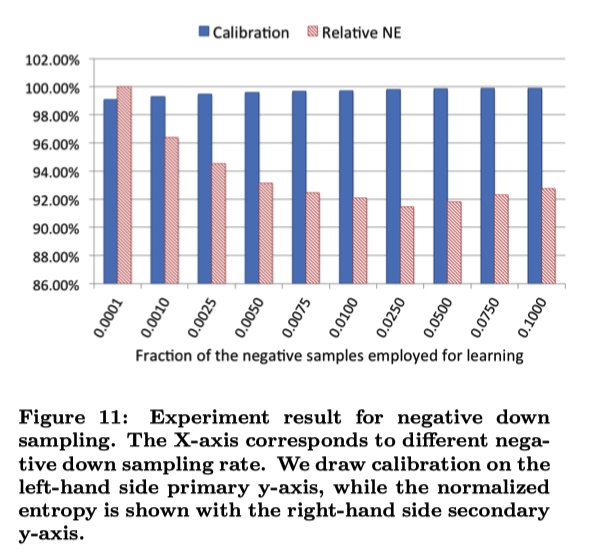
训练数据大多,需要进行采样。
uniform subsampling :无差别采样。使用 10 % 的样本,NE 减少 1 %
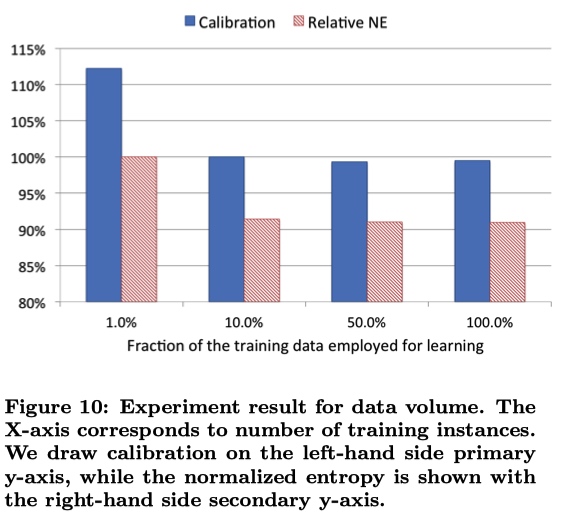
negative down subsampling :对负样本进行下采样。但不是负采样率越低越好,比如下面的图中0.0250就可能是解决了正负样本不平衡问题。最后的CTR指标结果需要重新进行一次映射。