深入浅出 BERT 源代码之 BertModel 类
国庆节前突然对如何计算 BERT 的参数量感兴趣,不过一直看不明白网上的计算过程,索性下载 BERT 源代码阅读一番。这篇文章记录阅读 BertModel 类(核心代码实现)时写的一些笔记,反正我也是纸上谈兵,所以不需要太关注数据处理和 Finetune 相关部分,最后附上计算 BERT 参数量的过程仅供参考。
代码地址:bert/modeling.py at master · google-research/bert
BertConfig
1 | class BertConfig(object): |
BertConfig 类包含模型参数、几个读取和存储参数的方法。
@classmethod 代表类方法,不需要实例化就可以调用类中的方法。参考其他的文件可以发现它的使用是:
1 | bert_config = modeling.BertConfig.from_json_file(FLAGS.bert_config_file) |
主要参数有:
vocab_size: 词表大小hidden_size: Size of the encoder layers and the pooler layer. 词向量 embedding 大小num_hidden_layers: Number of hidden layers in the Transformer encoder. 层数num_attention_heads: Number of attention heads for each attention layer in
the Transformer encoder. 多头数量intermediate_size: The size of the “intermediate” (i.e., feed-forward)
layer in the Transformer encoder. FFN 中间层的大小hidden_act: The non-linear activation function (function or string) in the
encoder and pooler. 激活函数hidden_dropout_prob: The dropout probability for all fully connected
layers in the embeddings, encoder, and pooler. dropout 参数attention_probs_dropout_prob: The dropout ratio for the attention
probabilities.max_position_embeddings: position embedding 的最大值 (e.g., 512 or 1024 or 2048).type_vocab_size: next sentence prediction 中的 Segment A 和 Segment B,默认大小是 2initializer_range: The stdev of the truncated_normal_initializer for
initializing all weight matrices.
“””
embedding_lookup
根据 input_ids 生成词向量 embedding table 以及对应的 input_id_embeddings。简单一点理解就是向量从 [batch_size, seq_size] 到 [batch_size, seq_size,embedding_size]。
1 | def embedding_lookup(input_ids, |
从 embedding_table 取 input_ids 对应的 embedding 有两种方法:
- 矩阵乘法:先通过 input_ids 构造出 one_hot 矩阵,然后和 embedding_table 相乘得到结果。
tf.gather根据 input_ids 取 embedding_table 对应行的结果。和tf.nn.embedding_lookup方法类似。具体原理可以参考 python - What does tf.nn.embedding_lookup function do? - Stack Overflow
看网上的解释,定义两种方法主要是不同设备(CPU、GPU、TPU)运算速度导致的。
embedding_postprocessor
embedding_postprocessor 将 token embeddings segmentation embeddings position embeddings 三个向量相加得到最终的输入向量。
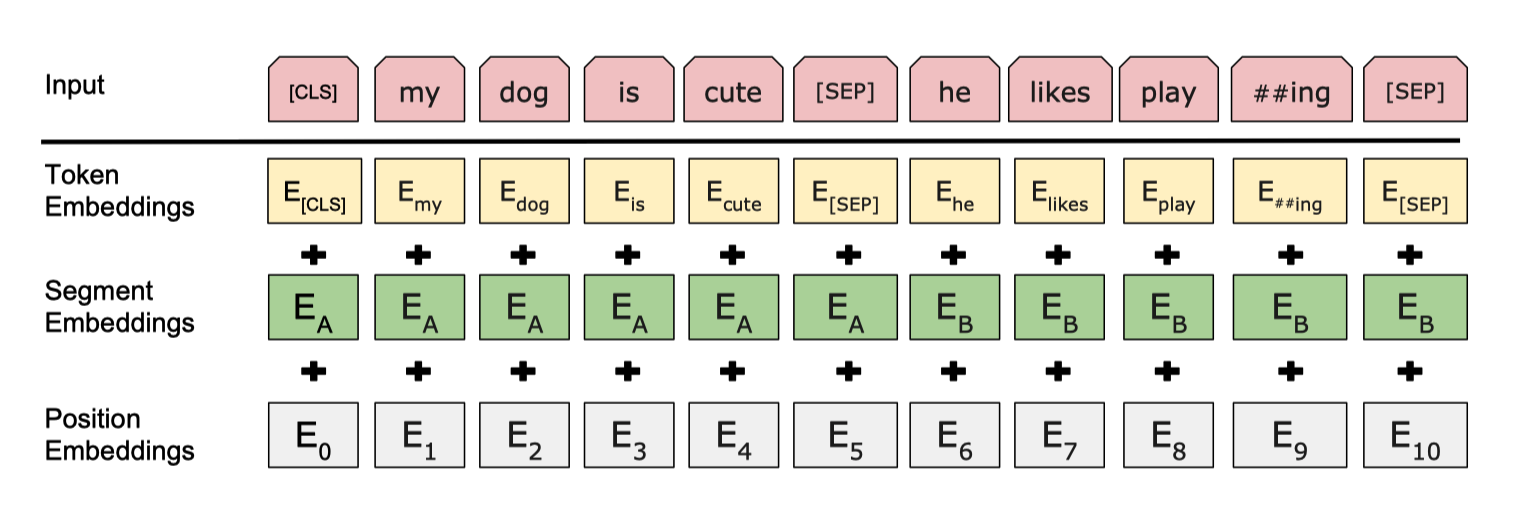
token embeddings对应单词 embeddingsegmentation embeddings代表单词来自哪个句子,在 Next Sentence Prediction 任务中使用。position embeddings位置 embedding。在「Attention is all your need」论文中,Google 生成 position embedding 的方法是一个花里胡哨 cos/sin 公式,这一次换成训练 position embedding。猜测在之前的论文中,输入的 seq len 可能长短不一,导致部分 position embedding 训练不充分。BERT 中强行定死 seq len。- 最后直接将三个 embedding 相加,可能对新人来说也有点迷惑。我自己的理解是,物理中多个不同波长的波叠加,是可以通过方法区分的。所以三个 embedding 相加,模型也能学到差异。
- 知乎这个问题为什么 Bert 的三个 Embedding 可以进行相加可以提供更加严谨的理由。
1 | def embedding_postprocessor(input_tensor, |
三个 embedding 向量相加后,还会过一个 layer_norm_and_dropout 层,都是标准的,没有什么特殊。
1 | def dropout(input_tensor, dropout_prob): |
create_attention_mask_from_input_mask
create_attention_mask_from_input_mask 用来构造 attention 时的 mask 矩阵(padding 的单词不参与计算 attention socre)。输入向量 [batch_size, from_seq_length, ...] 和 [batch_size, to_seq_length] 输出向量 [batch_size, from_seq_length, to_seq_length]。
偷个例子来举:
1 | from_tensor = tf.constant([[1,2,3,0,0], [1,3,5,6,1]]) # 中间的 0 代表 padding 的结果 |
最后的结果是
1 | [[[1. 1. 1. 0. 0.] #第一个词可以和前三个词计算 attention |
1 | def create_attention_mask_from_input_mask(from_tensor, to_mask): |
transformer_model
顾名思议 BERT 最核心的 Multi-headed, multi-layer
Transformer 实现过程。Attention is all you need 中的实现在 链接
一个 Transformer 的示意图:
![]()
1 | def transformer_model(input_tensor, |
attention_layer
attention_layer 中实现 self-attention 和 multi-head,细节在 「Attention is all your need」里面有。query_layer 由 from_tensor 得到,key_layer 和 value_layer 由 to_tensor 得到。由于是 self-attention-encoder,from_tensor 和 to_tensor 相同。
示意图:
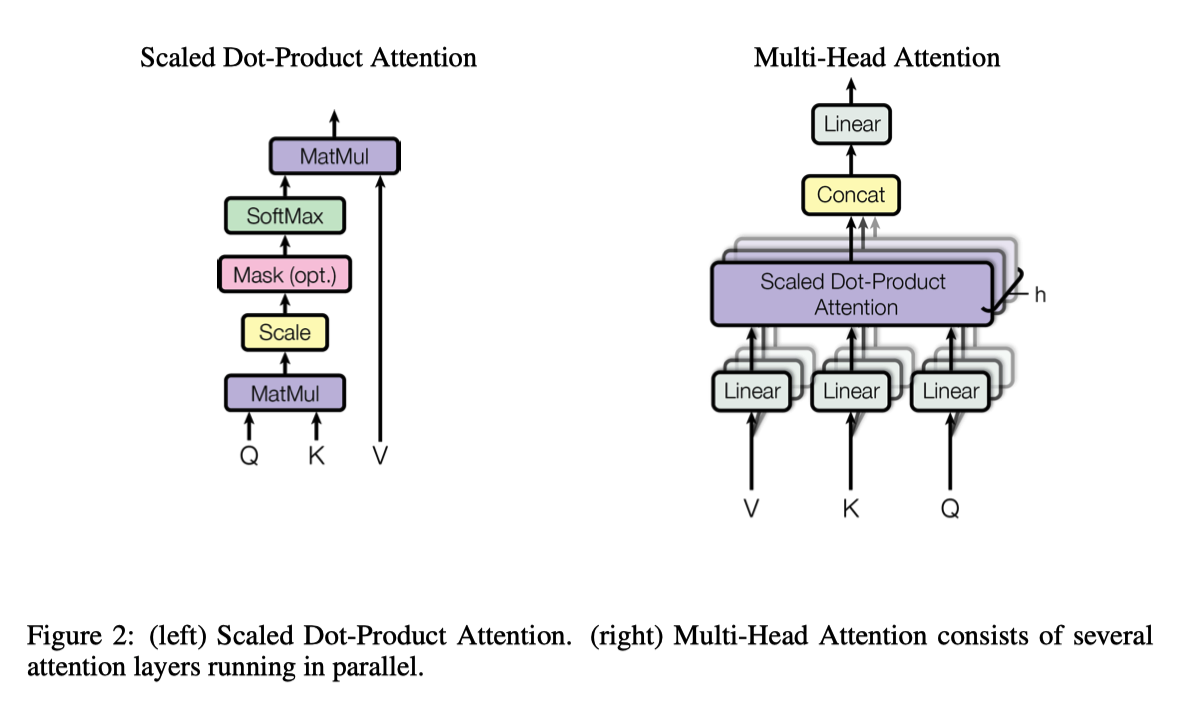
1 | def attention_layer(from_tensor, |
BertModel 构造类
init 方法就是将上面的内容串联起来。
1 | def __init__(self, |
模型使用
1 |
|
Bert 参数量计算
回到写这篇文章的起点,最后通过计算 $BERT_{BASE}$ 的参数量,加深对模型的理解。论文介绍 Layer = 12,Hidden Size = 768,multi head = 12,参数量是 110M 左右。
总的计算公式为 (30522 + 512 + 2)*768 + 768*2 + (3*768*64*12 + 3*64*12 + 64*768*12 + 768 + 768 + 768 + 768*3072 + 3072 + 3072*768 + 768 + 768 + 768) * 12 = 108891648
- embedding 部分
(30522 + 512 + 2)*768 + 768*2- embedding size = 768
- 单词数仅有 30522,比起 CTR 几千万的物品还是少很多。
- position size = 512
- sentence size = 2
- 三个 embedding 相加后 Norm 的参数 2
- multi attention 部分
(3*768*64*12 + 3*64*12 + 64*768*12 + 768 + 768 + 768 + 768*3072 + 3072 + 3072*768 + 768 + 768 + 768) * 12- 一共是 12 层,对应 12 个 Transformer
3*768*64*12 + 3*64*1212 个 multi-head 对应的 Q K V 参数64*768*12 + 768 + 768 + 768multi-head 结果 concat 之后接的全连接层参数以及后面的 norm768*3072 + 3072 + 3072*768 + 768 + 768 + 768FFN 以及 norm 的参数
Ref
深入浅出 BERT 源代码之 BertModel 类