Parameter Server
什么是 PS ?
- 分布式进行梯度下降的计算完成参数的更新与最终收敛
- 和 [[Spark MLib]] 一样数据并行训练产生局部梯度,再汇总梯度更新参数权重的并行化训练方案
参数服务面临的挑战
- 访问参数需要的大量带宽
- 算法需要有序更新参数,不同服务器之间同步带来的时延
- 训练容灾
PS 重要特征
- 异步同行
- 灵活的一致性模型
- 弹性扩展
- 容灾
- 方便使用
并行梯度下降流程
- 任务管理器
- 分发数据到 workder
- Worker
- 初始化
- 加载训练数据
- 从 server 节点拉取参数
- 迭代
- 根据本节点训练数据计算梯度
- 将计算好的梯度 push 到 servers 节点
- pull 最新需要用到的参数
- Servers
- 汇总 m 个 worker 计算出的梯度成总梯度
- 利用总梯度和正则化项梯度,计算新参数

- 初始化
物理架构
- server group 管理,每个 server 维护部分参数
- 支持自定义梯度更新方式
- Range Push 和 Pull
- 小批量更新参数
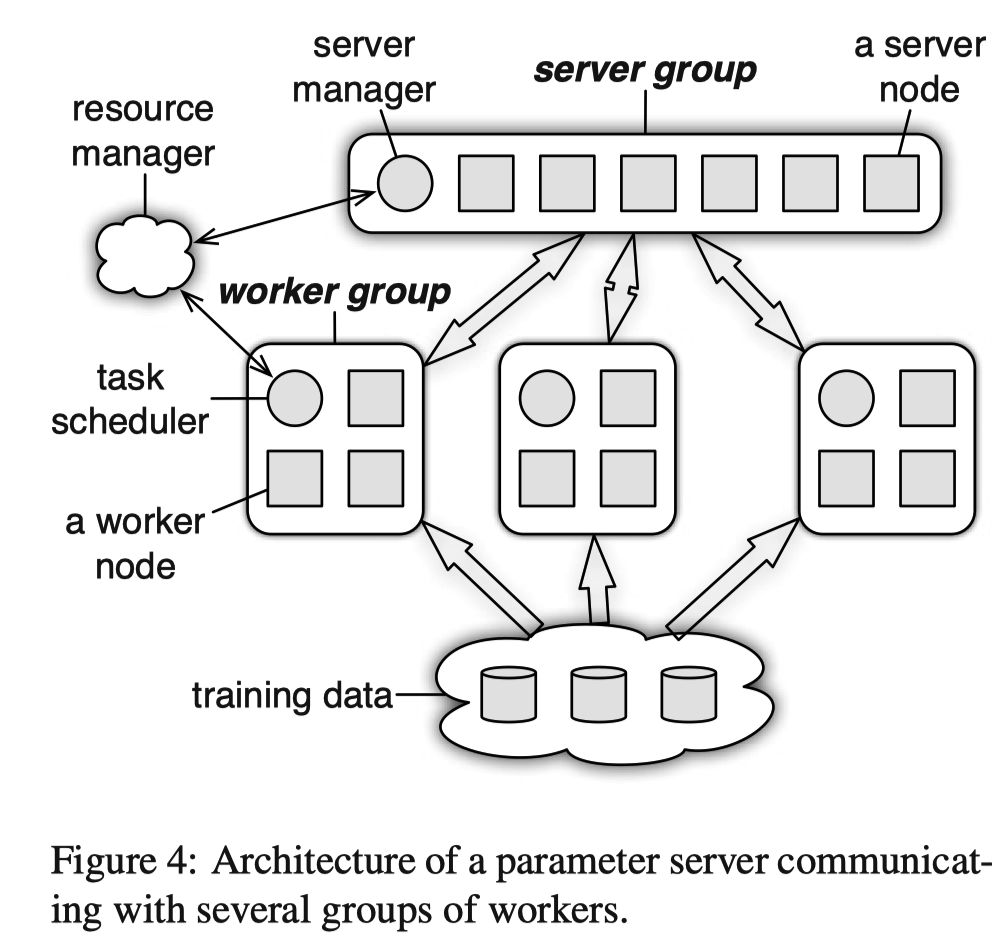
- 小批量更新参数
一致性和并行效率之间的取舍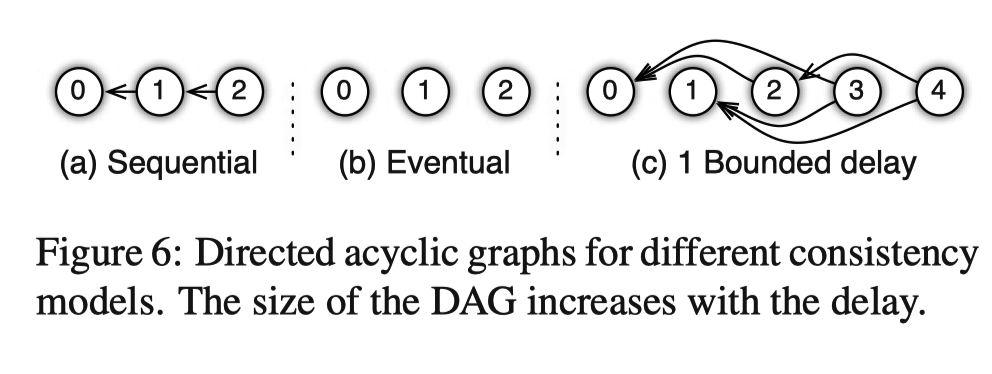
- 同步阻断式
- 等 master 汇总全部梯度,重新计算模型新参数后才开始下一轮计算
- 异步非阻断式
- 每一轮更新没有关联
- 最大延迟
- 新的参数没有获取到时,使用旧的参数计算梯度
- 指定 X 轮迭代必须等待更新参数
Vector Clock
- 记录每个 worker 每个 range 对应的参数时间
多 server 节点的协同和效率问题
- ((7627aee6-0ca0-40b7-a649-0ed86482eb01))
- 通过[[一致性哈希]]计算参数位置以及分配对应的服务器
- 服务器 S1 会计算 S1 对应的参数,也会备份之后几个 server 对应的参数
- 增加节点相当于将 range 分裂
- 删除节点可以让临近节点负责
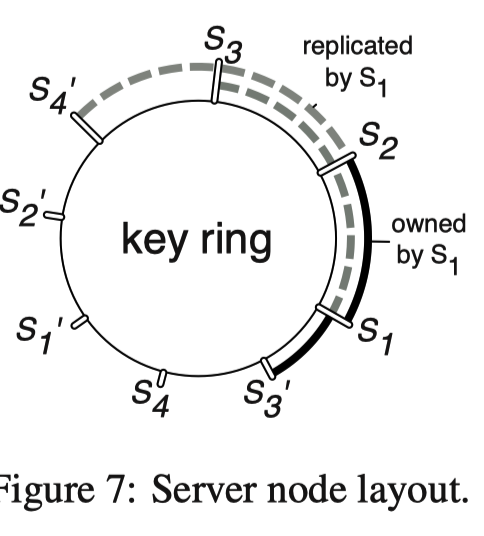
- server 在汇总多个 workder 的结果之后广播
总结
- 用异步非阻断式的分布式梯度下降策略代替同步阻断式的梯度下降策略
- 实现多 server 节点的架构,避免单 master 节点带来的带宽瓶颈和内存瓶颈
- 使用[[一致性哈希]],range pull 和 range push 等工程手段实现信息的最小传递,避免广播操作带辣的全局性网络阻塞和带宽浪费
问题
- 各 worker 之间如何同步?
+ - 如何解决 DNN weight
- AllReduce 完成 dnn weight 在各 worker 节点同步
- feature embedding 使用纯异步 ASP 模式,dnn weight 使用纯同步 SSP 模式
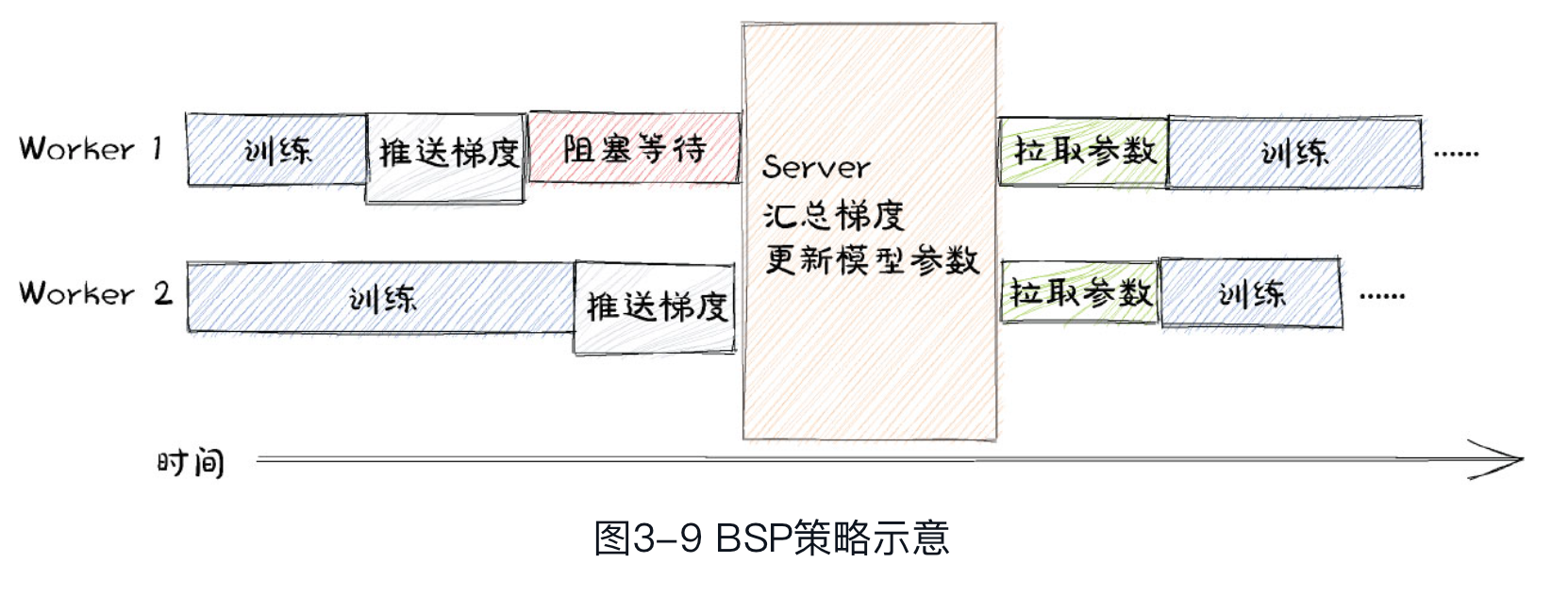
worker 之间的并行策略
- BSP(Bulk Synchronous Parallel) #card

- SSP(Stalness Synchronous Parallel) #card


- ASP(Asynchronous Parallel) #card
实现
- 基于ps-lite实现分布式算法
- 阿里巴巴的XDL
- 快手的Persia
Ref
Parameter Server