@9.3 探微参数与性能的关系,把点连成面
贝叶斯优化的核心 #card
- 设定一个先验分布,选择点进行探索,
- 根据观察的结果调整后验分布,
- 再从校正的分布里面选择下一个点。
点方法中有一套参数搜索算法是遗传算法,遗传算法的核心思想是模拟基因重组、变异过程+环境淘汰。假设把每一组参数都表示成一个0/1的字符串,那么遗传算法的操作过程如下。
- (1)生存模拟,得到当前所有点的奖励,按照某个比例淘汰最差的那一部分。
- (2)基因重组,选择一些“父母”,用0/1字符串表示它们,并从某个地方分开,两边互换,生成新的个体,把新的个体加入族群。比如父母分别是010000和100010,从中间位置分开,产出的个体就是010010和100000。
- (3)基因变异,以某个概率在字符串中将0/1互换。
- (4)重复上面的(1)~(3)直到生成的后代与父代相比不再有显著差异,遗传算法视为收敛。
不过在多任务融合权重上目前还没有看到遗传算法应用的例子,原因有两点:#card
- 其一是其淘汰得太慢了,调参时每一个参数要占据一组流量,很多在尝试的流量桶都不是高性能的点,这些点要承受损失。
- 好的点不尽快出现是很致命的,这也是CEM比遗传算法有的很大优势,出现了好的点,下一次迭代所有的点都会向它靠近;
- 其二是常见的遗传算法需要把参数编码到二进制字符串上,但是在多任务融合这里都是浮点数,还需要设计转换算法。
[[粒子群算法]]
区分搜索参数的过程。把所有参数空间均匀分,打成网格是一种搜索参数的方法;先随机选点,再调整也是一种方法(CEM及上面介绍的其他方法)。#card
- 上面的算法都是基于点的,根据某几个点的性能决定如何迁移到下一个点上去。
- 这样的认知不够全面,有没有方法把参数和性能直接挂钩建模成一个函数关系,从而知道整个面上的性能表现呢?
- 在点方法中每个点是一个随机变量,而在面方法中需要建模一个随机函数,也就是随机过程。
一个高斯过程+贝叶斯优化搜索参数的方法 #card
- 一句话概括就是设定一个先验分布,选择点进行探索,根据观察的结果调整后验分布,再从校正的分布里面选择下一个点。
- 在每一步执行之前我们对函数的认知都是先验分布的,然后在这个分布上找出收益最好的点进行探测,得到新的奖励。
- 结果反过来帮助我们修正分布,也就是后验分布。
- 什么时候是先验、后验也不重要,只要明确我们总是不停地在修正认知就好。
- 在上述过程中需要3个工具:
- ①被拟合的对象的基本假设和模型,称为替代模型;
- ②根据新的采样点修正函数形式的手段;
- ③根据当前结果选择下一轮要搜索的点方法,设计一个采集函数,函数最大值对应的位置是下一个要采集的点。
- 高斯过程和贝叶斯优化总是成对出现的,前者是随机函数的选型,后者是矫正随机函数形式的手段。采集函数会在下面介绍。
用一维随机函数做例子的示意图来可视化贝叶斯优化的执行过程
- [[贝叶斯优化过程的第一次迭代]]
- 贝叶斯优化过程的第二次迭代
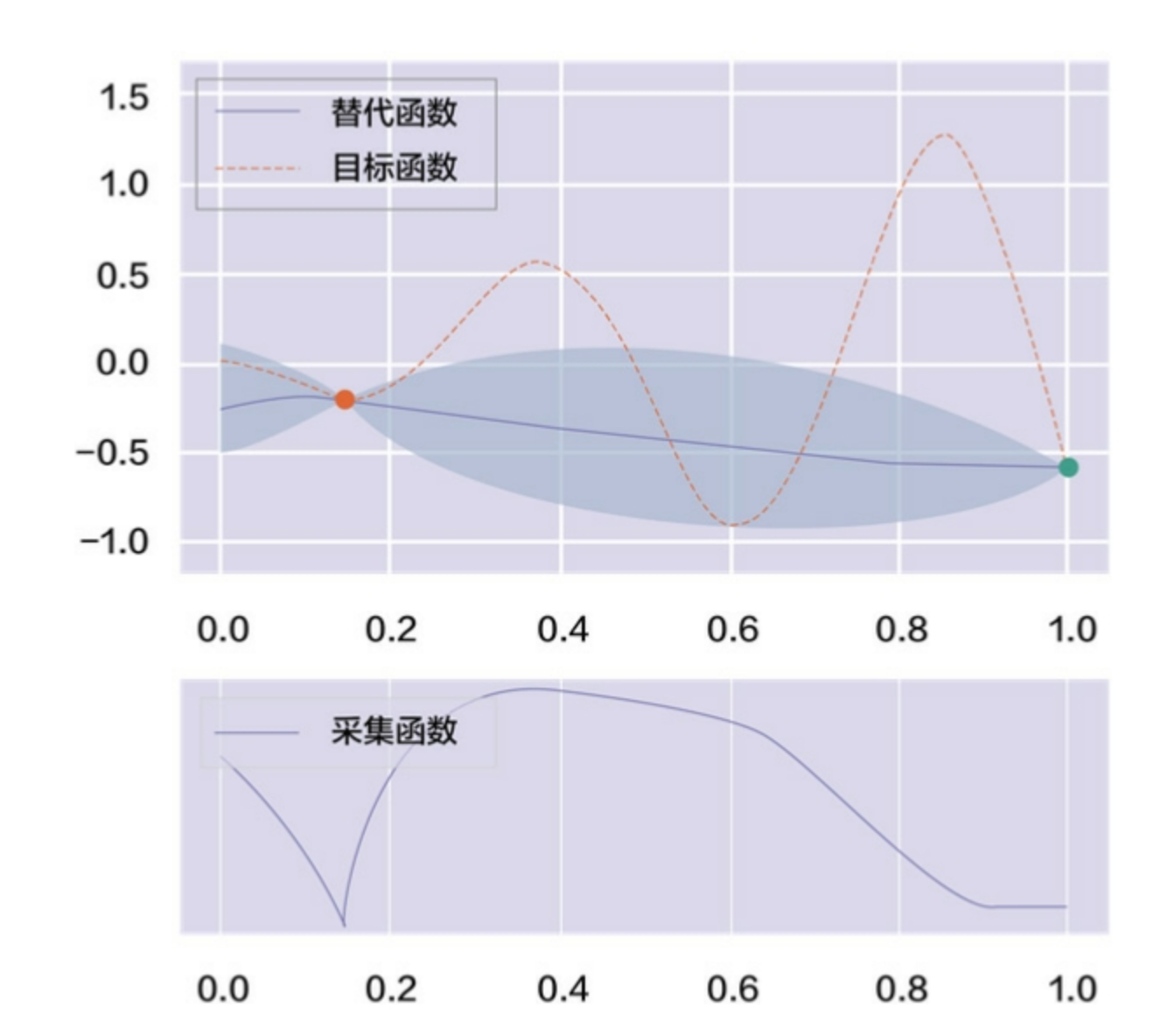 #card
#card- 按照采集函数的指示,探索了1.0附近的点,得到它的性能是-0.6,据此更新预估函数形式和采集函数形式。注意现在已经有两个点的方差缩小到一个点上了,蓝色阴影变成了纺锤形。继续在采集函数中选择最大值,在0.4附近。
- 贝叶斯优化过程的第三次迭代如图9-6所示。
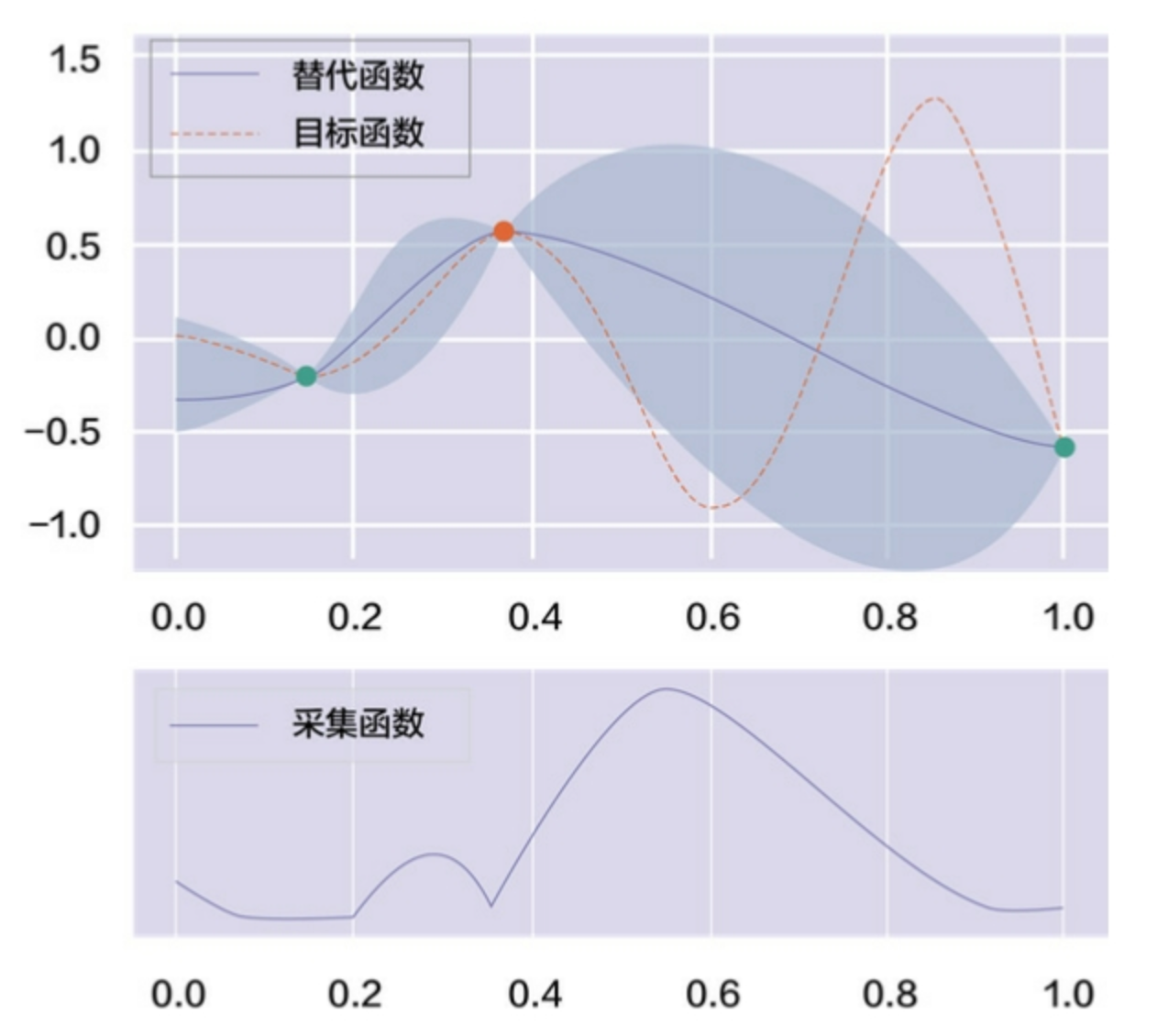 #card
#card- 随着迭代的进行,函数形式会越来越接近真实结果,最终到达全局中性能比较好的位置。
替代模型和采集函数
- 这里的替代模型不再是一个普通函数,而是具有随机性的。之前的CEM,每套参数是一个点,它的性能是一个随机变量,但现在我们要建模参数和性能之间的函数映射,这是一个随机函数,也就是随机过程。最典型也最好用的随机过程是高斯过程,它假设任意一个点处的随机变量符合高斯分布,变量之间的联合分布也符合高斯分布。协方差矩阵可以写为 #card

- 到这里把高斯过程、贝叶斯优化等名词都抛掉再看,这个算法很符合直觉:在已有点的基础上,新的点是与已有点距离有关的性能的插值。#card
- 虽然算法有概率上的各种考虑,但本质上还是这样的。
- 那么采集函数,也就是选择点的时候以什么准则呢
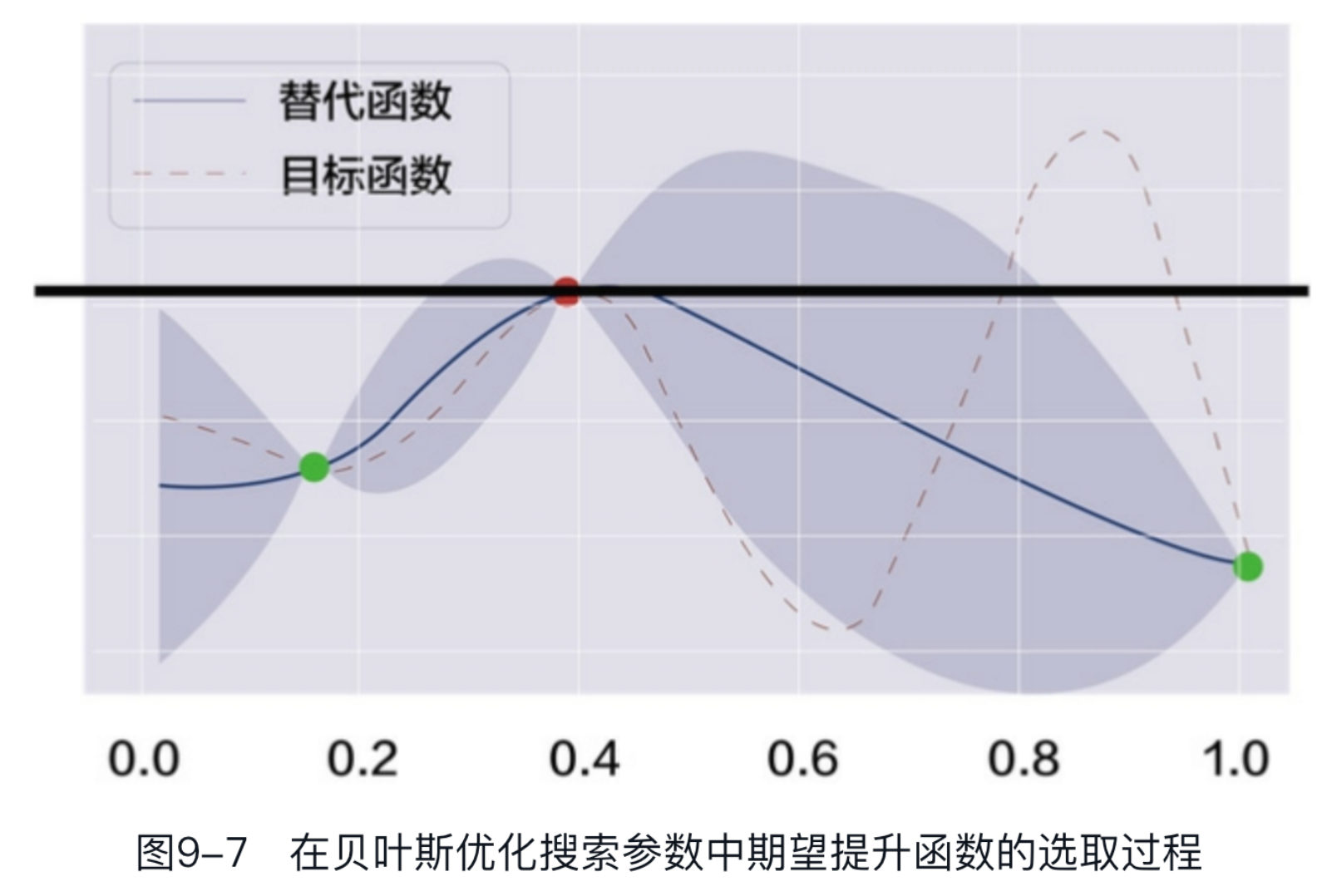
- 期望提升函数 ${E\left{\max \left[f(x)-f\left(x^*\right)\right] \cdot 0\right}}$ #card
- X* 表示之前性能最好的点,也就是哪个点比上一次有最大的性能提升就选择的那个点。
- 以第三次迭代的结果为例,当前最优的点是下图中的红点,在贝叶斯优化搜索参数中期望提升函数的选取过程如图9-7所示。#card
- 选取下一个点时就是把红点所在的直线(图9-7中的黑线)上面的部分取出来积分,看谁最大。
- 除了期望提升函数,还可以有更简单的做法,如按照均值+一倍方差的最大值来选,那么采集函数就等于图中的 → 阴影上边界。
- 期望提升函数 ${E\left{\max \left[f(x)-f\left(x^*\right)\right] \cdot 0\right}}$ #card
@9.3 探微参数与性能的关系,把点连成面