@A Consumer Compensation System in Ride-hailing Service
[[Attachments]]
- A Consumer Compensation System in Ride-hailing Service_2023_Yu.pdf {{zotero-linked-file “A Consumer Compensation System in Ride-hailing Service_2023_Yu.pdf”}}
代驾和货运的补贴系统
- 价格弹性建模 ((65b1f955-417a-4457-95ef-8d223ce14b4c))
- 预算分配 ((65b1f965-af6d-4b32-b1f0-96d4151f5f01))
系统目标:在预算范围内,通过补贴最大化平台收入。
- ((65b1fbc2-5d19-4684-b5c7-b2424fecf57a))
难点
- 如何用历史数据建模用户弹性 ((65b1fd34-d738-4f68-b90b-60efb3a9aca9))
- 个保法下公平原则(不同用户相同 odt 补贴相同) ((65b1fd3d-cae0-4efa-a2d2-08d4b8919709))
- 如何建模线上随机的发单请求 ((65b1fd6a-db88-47e3-808d-a686f6586589))
((65b1fe34-8525-479e-abd4-155b544d3fa4))
- 常规训练 uplift 模型需要大量随机补贴下的响应数据(成本高),本文方法使用大量线上观测数据(有偏,受线上策略影响)和少量随机补贴数据训练模型。
- DNN + GBDT:解决 ((65b2028e-75cb-4f40-8e06-22a2166cbfba))
- 超过 90% 特征是 dense numerical feature ,需要用 GBDT建模,但是 GBDT 不好 fine-tuning 新数据以及处理稀疏特征。
- 训练 s-learner model
- ((65b2024f-eaa7-462c-bc11-cae352aabdfb))
- 两个 XGB 模型分别用观测数据 observational data 和随机数据 RCT data 训练,目标是二分类(用户是否下单)。
- 数据过两个 XGB 模型得到叶子信息,再过 embedding 层,concat 两个 embedding 过 inner 层。
- 先用 observational data 训练整个网络 ((65b20626-d8aa-4430-83b7-7ba54215f50d))
- RCT data 用另外一个输出层训练 ((65b20652-6366-414d-ab84-74a0d87bfed7))
- fine-tuning 时使用 early stopping
((65b206dd-3a99-40c4-a661-54965bfd83bc))
- 订单聚类成 OD 网格
- 网格内历史订单平均弹性作为网格弹性 ((65b20798-d159-405c-a66e-54723386a698))
- ((65b20804-56df-425f-a48e-5def2d17e48b)) 建模成最优化问题求解分配方案
线上系统:离线生成补贴词典供线上使用
- ((65b20b39-aa4c-488c-8507-ec4b07edf866))
离线实验
- Uplift 模型
- 特征
- ((65b20c51-20cd-44fe-b015-3ca64e225bf4))
- 模型细节
- ob data xgb,35 棵树,1120 个叶子节点
- rct xgb,51 棵树,1314 叶子节点
- embedding size 8
- ((65b20ce2-4edc-46f4-8e7d-a1c3ee5085be))
- 结果分析
- T-XGB+DNN AUUC 效果比 S-XGB+DNN 效果好,说明需要两棵树去提取特征?
- S-XGB+DNN:a single GBDT distiller DNN
- T-XGB+DNN:two-distiller GBDT distiller DNN
- ((65b249cb-8907-4f44-ba1d-f8ee50052f8d))
- T-XGB+DNN AUUC 效果比 S-XGB+DNN 效果好,说明需要两棵树去提取特征?
- 特征
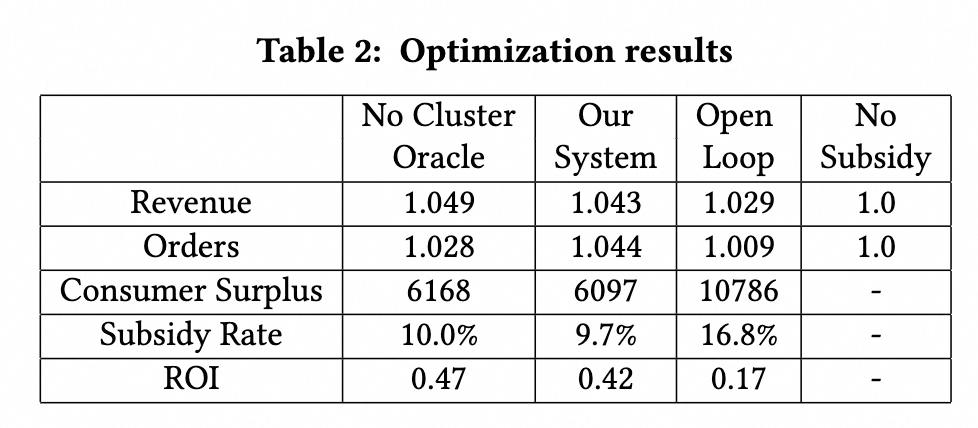
- 优化结果评估
- 假设 uplift 模型结果是真值,评估不同分配策略的影响。
- ((65b253c2-2d6f-4184-8011-b8fc5c18bb53)) 不对订单聚类,考虑用户特征。
- Open Loop 用前 14 天数据预测后 7 天
- 新系统补贴率低但是更高利润 ((65b25475-6a4d-4878-9e0b-d3f2588ed8ef))
一些问题?
- 为什么不是常规构建 uplift 模型的方法(实验组 + 空白对照组)?
- T-XGB 和 S-XGB 具体怎么训练?
- 为什么 rct 树的数量比 ob 树多?从样本角度 ob 树样本更多
- uplift 没有给纯 xgb 的
@A Consumer Compensation System in Ride-hailing Service