Learning to Rank
[[Point Wise]]
- 全局相关性
- 没有对先后顺序的优劣做惩罚
- 将 Ranking 算法转化成回归、分类或序列回归
[[Pair Wise]] 二分类
- 多个 pair 排序问题,比较不同文章的先后顺序
- 目标
- 减少误分类 doc pair 的比例
- 问题
- 考虑出现的相对位置,但是没有考虑文档在搜索列表中的位置。
- 排在搜索结果前面的文章更为重要,如果排在靠前的文章出现判断错误,代价明显高于排在后面的文档
- 不同查询相关文档数量差异大
- 考虑出现的相对位置,但是没有考虑文档在搜索列表中的位置。
- 方法
- RankNet
- [[GBRank]]
- $L\left(f ; x_{u}, x_{v}, y_{u, v}\right)=\frac{1}{2}\left(\max \left{0, y_{u, v}\left(f\left(x_{v}\right)-f\left(x_{u}\right)\right)\right}\right)^{2}$
- 关注逆序部分
- 逆序 loss 为正,正序 loss 为零
- $L\left(f ; x_{u}, x_{v}, y_{u, v}\right)=\frac{1}{2}\left(\max \left{0, y_{u, v}\left(f\left(x_{v}\right)-f\left(x_{u}\right)\right)\right}\right)^{2}$
[[List Wise]]
- 考虑整体序列,针对 Ranking 评价指标进行优化
- 方法
- AdaRank
- SoftRank
- [[LambdaMART]]
- LambdaRank
- 蓝色表示相关文档,右侧的图片中,虽然指标下降,但是从直觉上来说并不好。
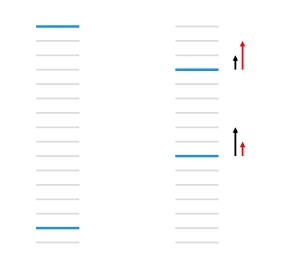
- 蓝色表示相关文档,右侧的图片中,虽然指标下降,但是从直觉上来说并不好。
指标
- MAP(Mean Average Precision)
- $$A P=\frac{\sum_{j=1}^{n_{i}} P(j) \cdot y_{i, j}}{\sum_{j=1}^{n_{i}} y_{i, j}}$$
- $$P(j)=\frac{\sum_{k: \pi_{i}(k)} \leqslant y_{i, k}}{\pi_{i}(j)}$$
- $$MAP=\frac{\sum_{q=1}^{Q} \operatorname{AveP}(q)}{Q}$$
- 所有 query 的 ap 值取平均
- 例子
- 假设query_1有4个相关的document,分别被模型排在1,2,5,7位,那么query_1的AP就是(1/1+2/2+3/5+4/7) / 4;
- query_2有5个相关的document,分别被模型排在2,3,6,29,58位那么query_2的MAP就是(1/2+2/3+3/6+4/29+5/58) / 5,但通常情况下,我们的
不会取到58,只会关注排名靠前的document,因此排在29与58的document可以视为没有被模型检索出来,假设取m
,则query_2的AP是(1/2+2/3+0+0+3/6+0+0)/5。
- 对以上两个query取平均即可得出MAP。
- [[NDCG]]
Ref
- Learning to Rank for Information Retrieval
- FM模型在LTR类问题中的应用 [[杨镒铭]]
- $$L=-\log \left(\tilde{y}{i j}\right)=\log \left(1+\exp \left(-\left(\tilde{y}\left(x{i}\right)-\tilde{y}\left(x_{j}\right)\right)\right)\right.$$
Learning to Rank