R-Learner
论文出处:Quasi-Oracle Estimation of Heterogeneous Treatment Effects
适用情形:随机干预实验的数据
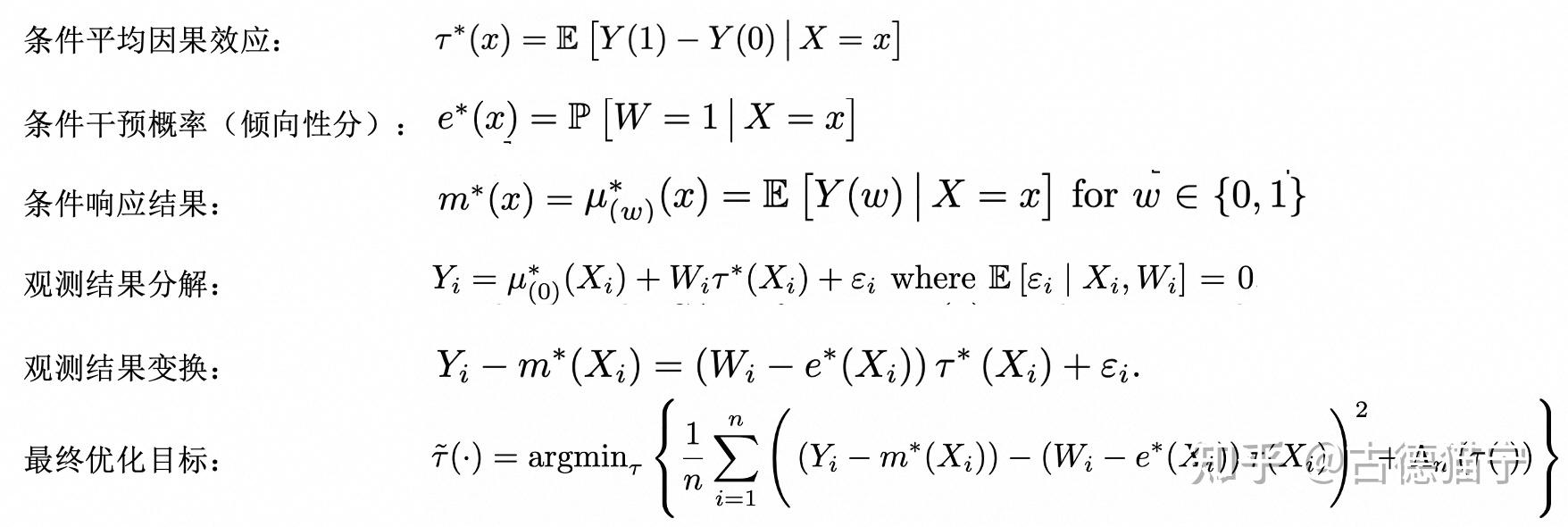
- ex → 特征 x 对干预 w 的影响,也是 [[倾向性得分]]
- $m^*(x)=E(Y \mid X=x)$ → 基于特征 x 对目标 y 的影响 conditional mean outcome
- $m^(x)=E(Y \mid X=x)=\mu_{(0)}^(x)+e^(x) \tau^(x)$ 拆解逻辑 #card
- 条件期望响应结果 $E(Y \mid X=x)$ 可以表示为
- 不施加干预时的条件期望响应结果 $\mu_{(0)}^*(x)$
- 倾向性得分 $e^(x)$(即条件干预概率)与干预效应 $\tau^(x)$ (即 CATE)的乘积。
- 条件期望响应结果 $E(Y \mid X=x)$ 可以表示为
- 观测结果 $Y_i=\mu_{(0)}^\left(X_i\right)+W_i \tau^\left(X_i\right)+\varepsilon_i$ 分解为 #card
- 无干预时的条件响应结果 $\mu_0^*(X_i)$
- 是否施加干预 $W_i$ 与因果效应 $\tau^*(X_i)$ 的乘积
- 残差 $\varepsilon_i$
- 观测结果变换 Robinson’s transfomation #card
- 两边分别减去条件响应结果 $m^*(X_i)$
- 通过上述转化,我们会发现,假定我们已经有了 $m^(x)$ 以及 $e^(x)$ 的表达式,我们就可以通过最小化残差来估计得到 treatment effect $\tau^*(x)$ ,即我们前面提到的通过一个 loss 优化问题来估计得到因果效应。
- 最终训练一个模型 $\tau(X_i)$ 最小化损失函数 $\tau^(\cdot)=\arg \min _\tau\left{\frac{1}{n} \sum_1^n\left(\left(Y_i-m^\left(X_i\right)\right)-\left(W_i-e^*\left(X_i\right)\right) \tau\left(X_i\right)\right)^2+\Lambda(\tau(\cdot))\right}$ #card
- 用权重为 $\left(W_i-e^\left(X_i\right)\right)^2$ 的样本 X 去拟合 $\tau\left(X_i\right)=\frac{Y_i-m^\left(X_i\right)}{W_i-e^*\left(X_i\right)}$
- 其中 $\Lambda$ 是模型$\tau(X_i)$ 参数的正则项,
- $e^(X_i)$ 和 $m^(X_i)$ 是事先训练好的模型,
- 此时 $\tau(X_i)$ 的输出结果就是我们想要的 CATE。
优点
- 将因果效应的估计问题转化为 {{c1 损失函数的优化}} 问题,提供了一种一般性的因果效应的预测框架。
缺点:#card
- 1)预测效果非常依赖模型 $e^(X_i)$ 和 $m^(X_i)$ ,但是这两个模型不一定能预测得准确。
- 2)假设了潜在结果 $Y_i$ 的分解是一种线性关系,限制了模型对复杂数据的拟合能力。