@Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
[[Abstract]]
[[Attachments]]
Long sequence [[Time Series Forecasting]] (LSTF)
LSTF 中使用 [[Transformer]] 需要解决的问题 #card
- self-attention 计算复杂度 $O(L^2)$
- 多层 encoder/decoder 结构内存增长
- dynamic decoding 方式预测耗时长
网络结构
ProbSparse self-attention
- 替换 inner product self-attention
- [[Sparse Transformer]] 结合行输入和列输出
- [[LogSparse Transformer]] cyclical pattern
- [[Reformer]] locally-sensitive hashing(LSH) self-attention
- [[Linformer]]
- [[Transformer-XL]] [[Compressive Transformer]] use auxiliary hidden states to capture long-range dependency
- [[Longformer]]
- 其他优化 self-attention 工作存在的问题
- 缺少理论分析
- 对于 multi-head self-attention 每个 head 都采用相同的优化策略
- self-attention 点积结果服从 long tail distribution
- 较少点积对贡献绝大部分的注意力得分
- 现实含义:序列中某个元素一般只会和少数几个元素具有较高的相似性/关联性
- 第 i 个 query 用 $q_i$ 表示
- $\mathcal{A}\left(q_i, K, V\right)=\sum_j \frac{f\left(q_i, k_j\right)}{\sum_l f\left(q_i, k_l\right)} v_j=\mathbb{E}_{p\left(k_j \mid q_i\right)}\left[v_j\right]$
- $p\left(k_j \mid q_i\right)=\frac{k\left(q_i, k_j\right)}{\sum_l f\left(q_i, k_l\right)}$
- $k\left(q_i, k_j\right)=\exp \left(\frac{q_i k_j^T}{\sqrt{d}}\right)$
- query 稀疏性判断方法
- $p(k_j|q_j)$ 和[[均匀分布]] q 的 [[KL Divergence]]
- q 是均分分布,相等于每个 key 的概率都是 $\frac{1}{L}$
- 如果 query 得到的分布类似于均匀分布,每个概率值都趋近于 $\frac{1}{L}$,值很小,这样的 query 不会提供什么价值。
- p 和 q 分布差异越大的结果越是我们需要的 query
- p 和 q 的顺序和论文中的不同 ((9bc63e03-0f2f-4639-b481-5d7925ba8858))
- $K L(q | p)=\ln \sum_{l=1}^{L_k} e^{q_i k_l^T / \sqrt{d}}-\frac{1}{L_k} \sum_{j=1}^L q_i k_j^T / \sqrt{d}-\ln L_k$
- 把公式代入,然后化解
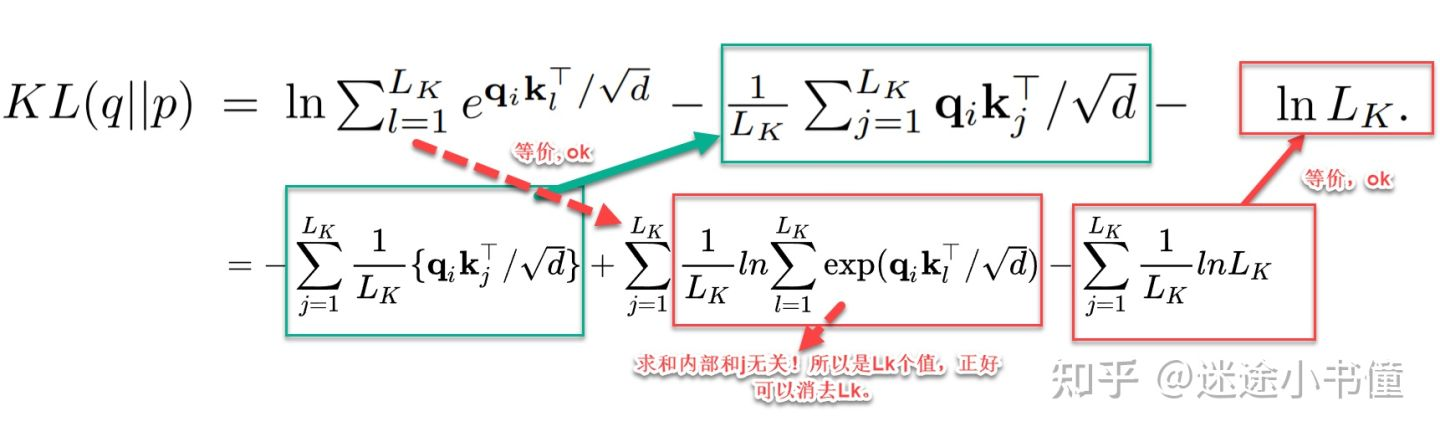
- 把公式代入,然后化解
- $M\left(q_i, K\right)=\ln \sum_{l=1}^{L_k} e^{q_i k_l^T / \sqrt{d}}-\frac{1}{L_k} \sum_{j=1}^{L_k} q_i k_j^T / \sqrt{d}$
- 第一项是经典难题 log-sum-exp(LSE) 问题
- 稀疏性度量 $M\left(q_i, K\right)$
- $\ln L \leq M\left(q_i, K\right) \leq \max j\left{\frac{q_i k_j^T}{\sqrt{d}}\right}-\frac{1}{L} \sum{j=1}^L\left{\frac{q_i k_j^T}{\sqrt{d}}\right}+\ln L$
- LSE 项用最大值来替代,即用和当前 qi 最近的 kj,所以才有下面取 top N 操作
- $\bar{M}\left(\mathbf{q}_i, \mathbf{K}\right)=\max _j\left{\frac{\mathbf{q}_i \mathbf{k}j^{\top}}{\sqrt{d}}\right}-\frac{1}{L_K} \sum{j=1}^{L_K} \frac{\mathbf{q}_i \mathbf{k}_j^{\top}}{\sqrt{d}}$
- $\mathcal{A}(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\operatorname{Softmax}\left(\frac{\overline{\mathbf{Q}} \mathbf{K}^{\top}}{\sqrt{d}}\right) \mathbf{V}$
- $\bar{Q}$ 是稀疏矩阵,前 u 个有值
- 具体流程
- 为每个 query 都随机采样 N 个 key,默认值是 5lnL
- 利用点积结果服从长尾分布的假设,计算每个 query 稀疏性得分时,只需要和采样出的部分 key 计算
- 计算每个 query 的稀疏性得分
- 选择稀疏性分数最高的 N 个 query,N 默认值是 5lnL
- 只计算 N 个 query 和所有 key 的点积结果,进而得到 attention 结果
- 其余 L-N 个 query 不计算,直接将 self-attention 层输入取均值(mean(V))作为输出
- 除了选中的 N 个query index 对应位置上的输出不同,其他 L-N 个 embedding 都是相同的。所以新的结果存在一部分冗余信息,也是下一步可以使用 maxpooling 的原因
- 保证每个 ProbSparse self-attention 层的输入和输出序列长度都是 L
- 为每个 query 都随机采样 N 个 key,默认值是 5lnL
- 将时间和空间复杂度降为 $$O(L_K \log L_Q)$$
- 如何解决 ((6326d1c6-fce8-42c5-a1db-57f7ce74e6ca)) 现象?
- 每个 query 随机采样 key 这一步每个 head 的采样结果是相同的
- 每一层 self-attention 都会先对 QKV 做线性转换,序列中同一个位置不同 head 对应的 query、key 向量不同
- 最终每个 head 中得到的 N 个稀疏性最高的 query 也是不同的,相当于每个 head 都采取不同的优化策略
- $p(k_j|q_j)$ 和[[均匀分布]] q 的 [[KL Divergence]]
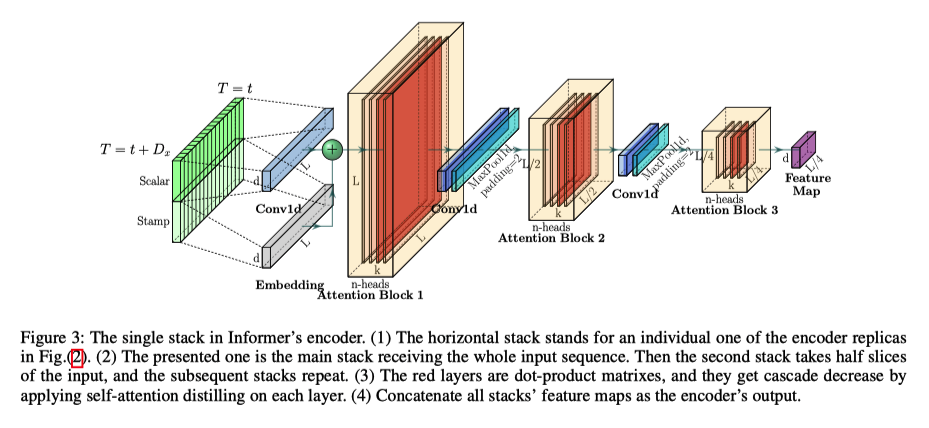
Self-attention distilling
- 突出 dominating score,缩短每一层输入的长度,降低空间复杂度到 $\mathcal{O}((2-\epsilon) L \log L)$
- encoder 层数加深,序列中每个位置的输出已经包含序列中其他元素的信息,所以可以缩短输入序列的长度
- 过 attention 层后,大部分位置值相同
- 激活函数 [[ELU]]
- 通过 Conv1d + max-pooling layer 缩短序列长度
1 | class ConvLayer(nn.Module): |
Generative style decoder
- 预测阶段通过一次前向得到全部预测结果,避免 dynamic decoding
- 不论训练还是预测,Decoder 的输入序列分成两部分 $X_{feed dcoder} = concat(X_{token}, X_{placeholder})$
- 预测时间点前一段已知序列作为 start token
- 待预测序列的 placeholder 序列
- 经过 deocder 后,每个 placeholder 都有一个向量,然后输入到一个全链接层得到预测结果
- 为什么用 generative style decoder #card
- 解码器能捕捉任意位置输出和长序列依赖关系
- 避免累积误差
Experiment
Input representation
See Also
Ref
@Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting