图1-1:DeepSeek-R1生成的完整流程
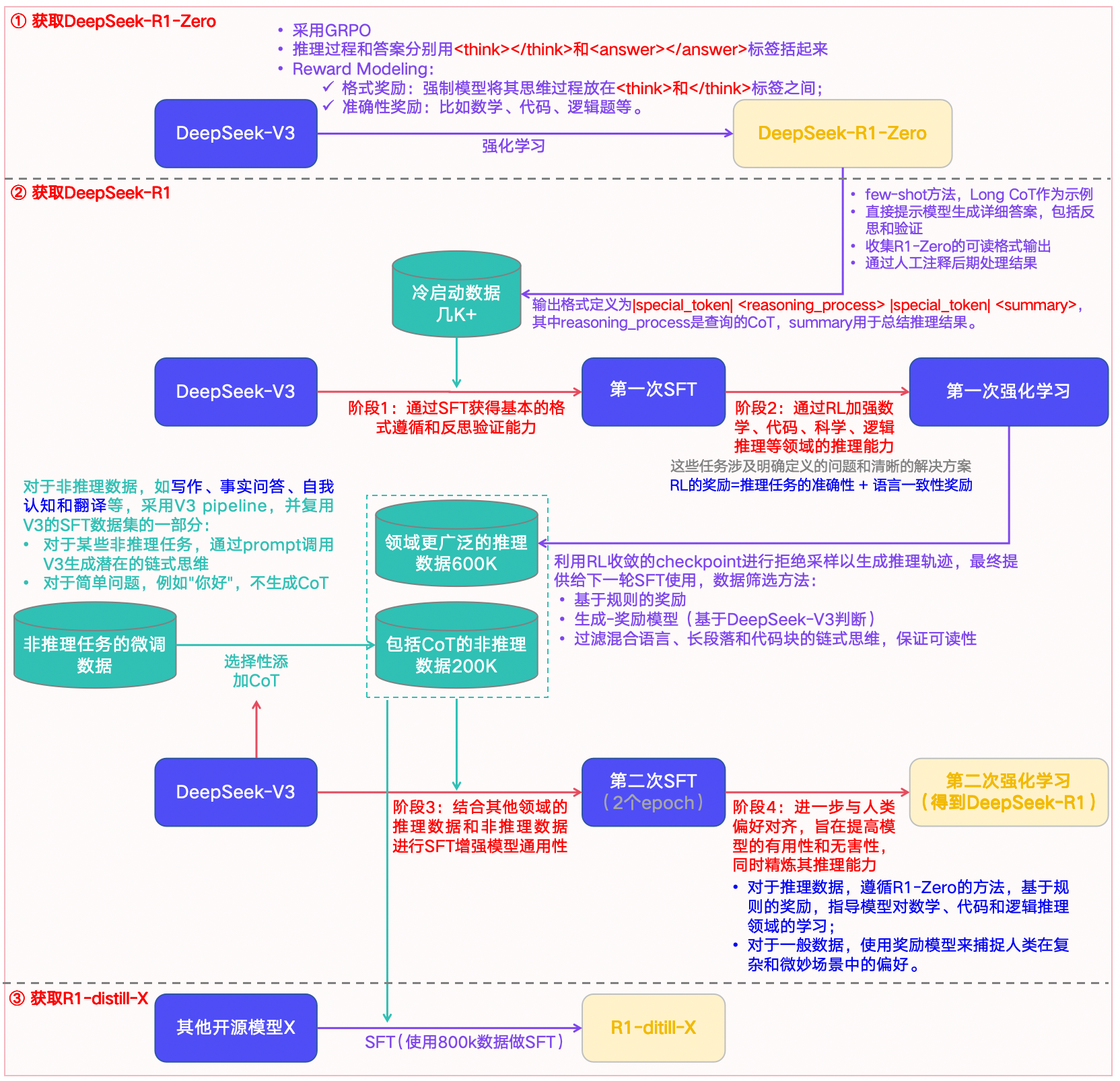
1)获取DeepSeek-R1-Zero:#card
- 通过”纯”强化学习(无任何监督数据)去生成一个新模型,即R1-Zero,然后用它生产几千+带CoT的冷启动数据,作为后续R1模型的燃料之一。
2)获取DeepSeek-R1:主要包括四个核心训练阶段(阶段1、2、3、4)和2个数据准备阶段(阶段0、2.5):
- 阶段0 → 即获取DeepSeek-R1-Zero。
- 阶段1 → 基于R1-Zero的几千+数据,在V3-Base上执行第一次SFT,获得基本的格式遵循和反思验证的能力。
- 阶段2 → 然后执行第一次强化学习,加强模型在数学、代码、科学、逻辑推理等领域的推理能力。
- 阶段2.5 → 基于阶段2的模型,获取领域更广泛的600K数据;基于V3-Base,获取包括CoT的非推理数据200K。
- 阶段3 → 基于阶段2.5获取的800K数据,在V3-Base上执行第二次SFT,增强模型的通用性。
- 阶段4 → 执行第二次强化学习,进一步对齐人类偏好,提升模型的可用性和无害性,并精炼推理能力。
获取R1-Distill-X的流程,#card
- X是指任何”其他模型”,比如qwen。在800K数据的微调后,将大幅提升原模型的效果。
图1-1:DeepSeek-R1生成的完整流程