Bayesian Bandit
假定第 i 根手柄的平均收益遵循先验概率 $p(\bar{R}(i))$ ,经过若干次实验,第 $i$ 根手柄收到一批反馈 $D_i=\left{r_1, r_2, \cdots, r_n\right}$ 。根据Bayes公式,第 $i$ 根手柄的平均收益的后验概率 $p\left(\bar{R}(i) \mid D_i\right) \propto$ $p\left(D_i \mid \bar{R}(i)\right) p(\bar{R}(i))$ 。此时我们选择手柄时,只需要从各手柄平均收益的后验概率中随机采样一个数,然后选择数值最大的那根手柄去拉动。#card
- 当各手柄的平均收益非0即1(这一点非常适用于推荐场景,比如点击与否)时,我们可以用伯努利分布来描述。
- 而这个伯努利分布的均值(即每根手柄的平均收益)可以用伯努利分布的共轭分布Beta分布来描述,好处是先验分布与后验分布都遵循同样的形式,方便贝叶斯公式的计算。
- 这种贝叶斯Bandit算法称为[[Thompson sampling]](汤普森采样),可用于试探新用户的兴趣分布,如代码8-3所示。
[[Thompson sampling]]伪代码 #card

[[Thompson sampling]]示意 #card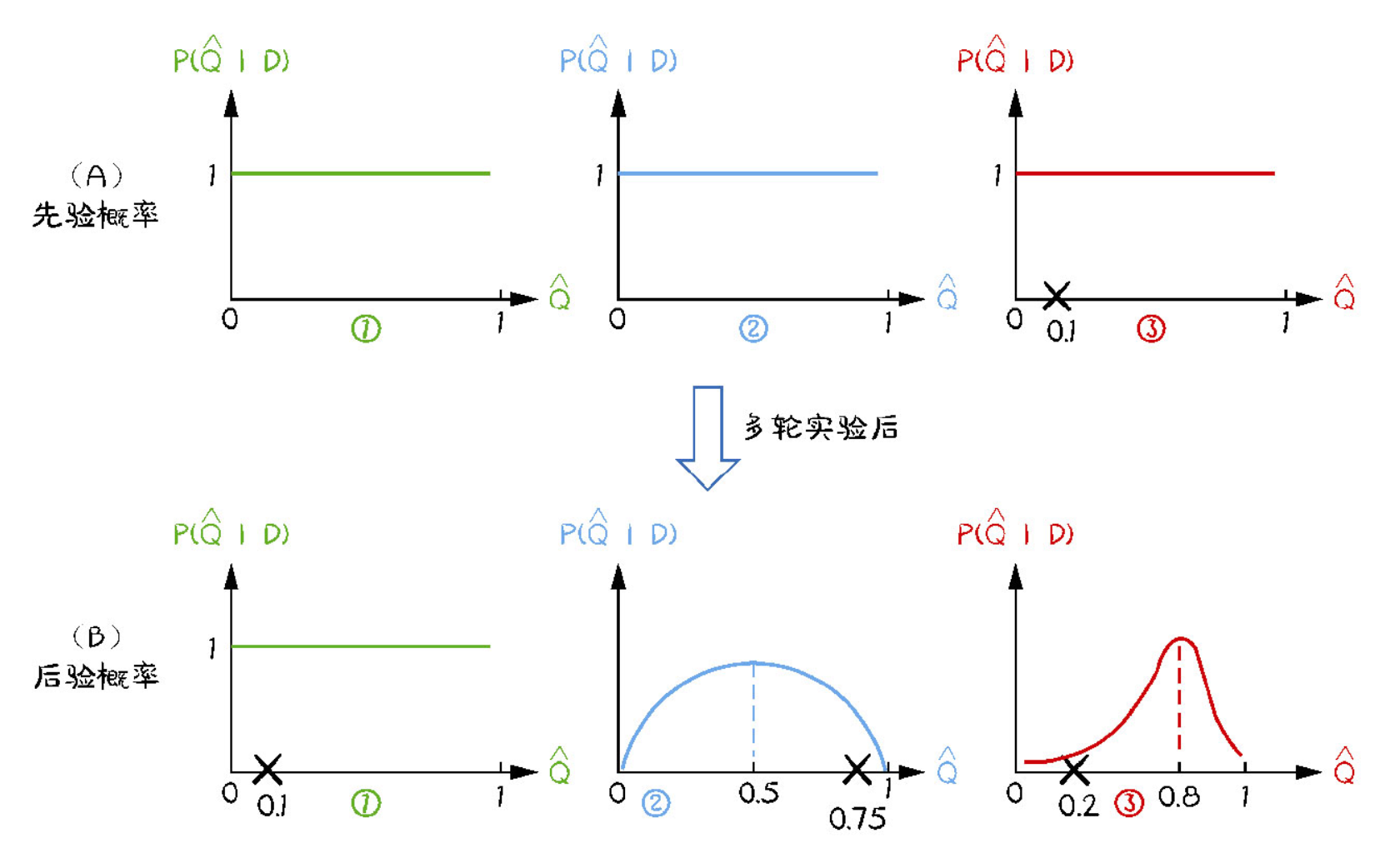
Bayesian Bandit