Life Long Learning
为什么需要持续学习?
- [[Catastrophic Forgetting]] #card
- 举的例子中提到模型依次学习不同任务,任务学习过后就会遗忘。将不同任务混合训练,在不同任务上都有比较好的表现。
- [[Multi-Task Learning]] 可以解决遗忘,但是每次新增加任务都需要从头训练。
- LLL 不希望保留之前任务的 数据
- Life Long Learning 的 upper bound
- 可塑性和稳定性 train a model for each task #card
- 存储多个模型
- 不同任务间的知识迁移
- 和 finetune 有什么区别? [[Transfer Learning]] #card
- 关注其他任务的学习能不能提高目标任务的表现,侧重训练后新任务表现怎么样。
- LLL 关注训练新任务后,旧任务表现怎么样。
- [[不同学习场景对比]]
分类
- 任务增量型持续学习(Task-Incremental CL)
- 类增量型持续学习(Class-Incremental CL)
- 域增量型CL(Domain-Incremental CL)
- 任务不可知型持续学习(Task-Agnostic CL)
- 模型在测试过程中可能会应对任意位置的任务
- 需要模型学到的特征能够容易地泛化到任意新场景
如何评估效果?
- a sequence of task
- $R_{i,j}$: 训练 task i 后 task j 的效果
i > jj 是否被遗忘?i < j任务 i 能否被迁移到任务 j
- 指标
- Accuracy $=\frac{1}{T} \sum_{i=1}^{T} R_{T, i}$
- Backward Transfer $=\frac{1}{T-1} \sum_{i=1}^{T-1} R_{T, i}-R_{i, i}$
- 评估遗忘程度(下降程度)
- 一般结果小于 0
- Forward Transfer $=\frac{1}{T-1} \sum_{i=2}^{T} R_{i-1, i}-R_{0, i}$
为什么会发生 ((62e4df4a-77aa-4401-915e-99aab440ec43))?
- 不同任务损失最小的参数空间可能不同
解决方法
Selective Synaptic Plasticity
- Regularization-based Approach
- 思路:保留模型先前学习到的重要参数,只改变不重要的参数学习新任务。
- $L^{\prime}(\boldsymbol{\theta})=L(\boldsymbol{\theta})+\lambda \sum_{i} b_{i}\left(\theta_{i}-\theta_{i}^{b}\right)^{2}$
- $\theta ^b_i$ 之前学习到的参数
- $b_i$ 评估 $\theta ^b_i$ 对前面模型的重要性
- $b_i = 0$ 会出现 [[Catastrophic Forgetting]]
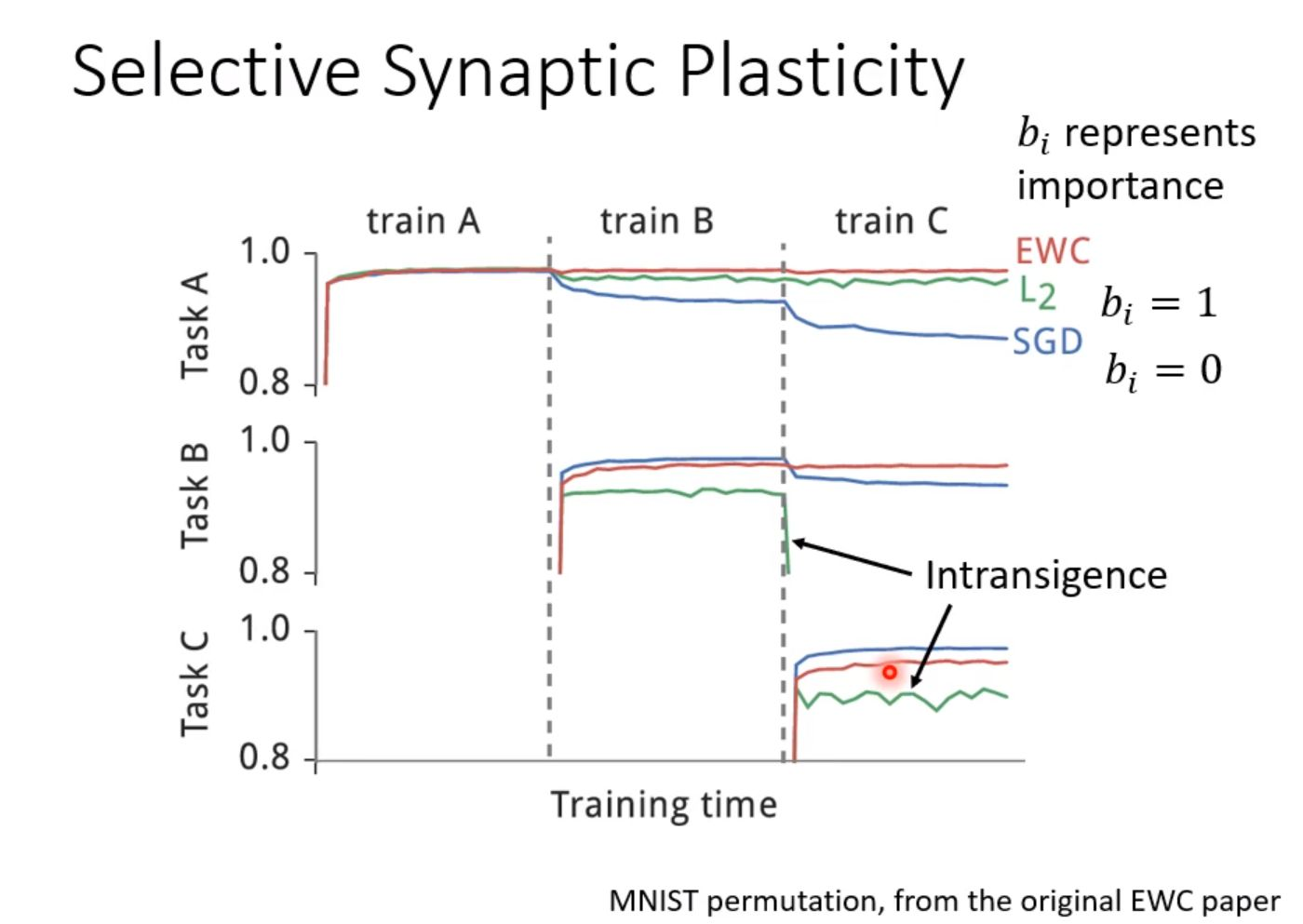
- bi 过大会出现新任务学习不好 intransigence
- bi 由人为设定,如果由模型学习,bi=0 后一项损失最小。
- 如何选择?
- 训练完模型后,如果改变某个参数对模型影响大,设置 bi 很小。反之,设置 bi 很大
- 例子
- SGD 代表之前的方法,学习 B 和 C 后,A 的效果明显下降。
- L2 代表 $b_i = 1$,B 和 C 很难学习
+ 研究如何计算不同的 bi 值
+ Elastic Weight Consolidation (EWC)
+ [[Synaptic Intelligence]] (SI) 参数改变对损失函数的影响
+ Memory Aware Synapses (MAS) 参数改变对模型输出的影响
+ RWalk
+ Sliced Cramer Preservation (SCP)
+ gradient episodic memory
+ 对梯度更新方向做出限制
+ task 1 和 task 2 的梯度做点积大于 0,让两个任务的梯度更新方向尽可能相同。
+ 需要记录过去 task 的梯度信息 (远小于过去task的数据量)
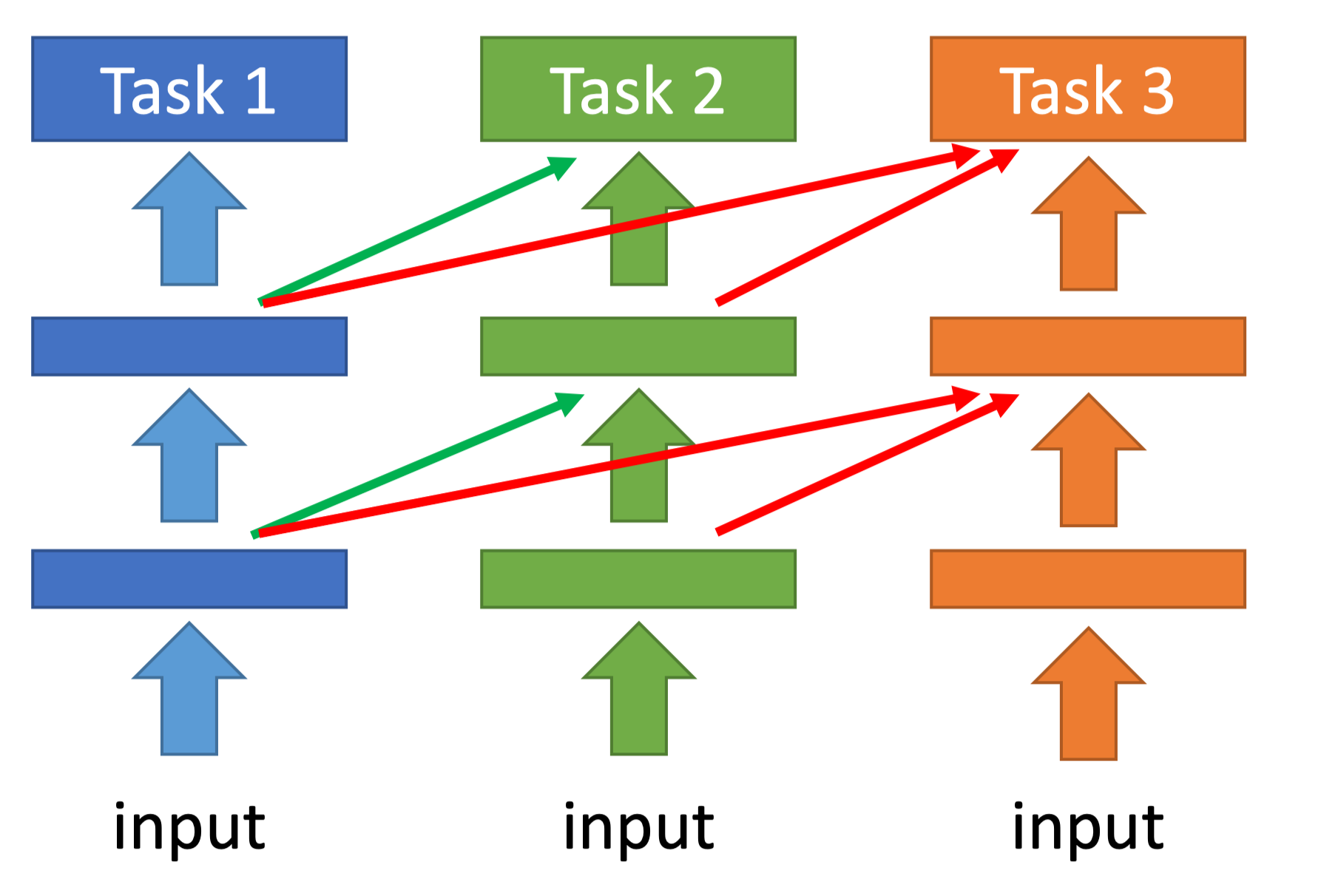
+ 不动已经训练好的模型参数,将它做为下一个模型某些层的输入,再增加模型学习新任务的参数。
+ PackNet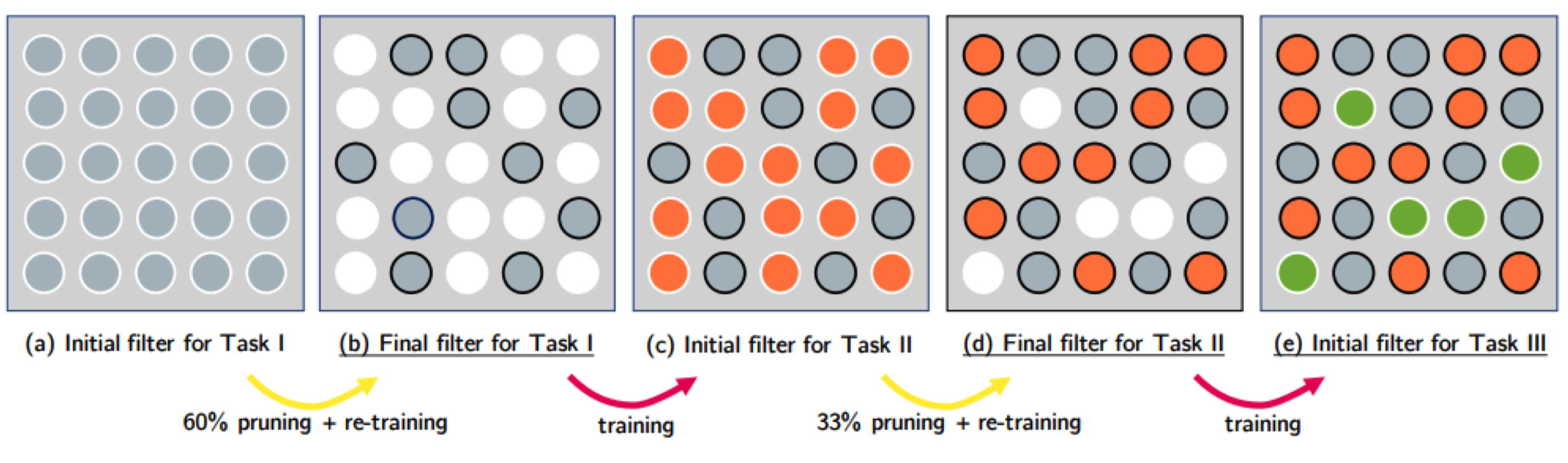
+ 不增加神经元数量,每个任务只使用部分模型参数
+ Compacting, Picking, and Growing (CPG)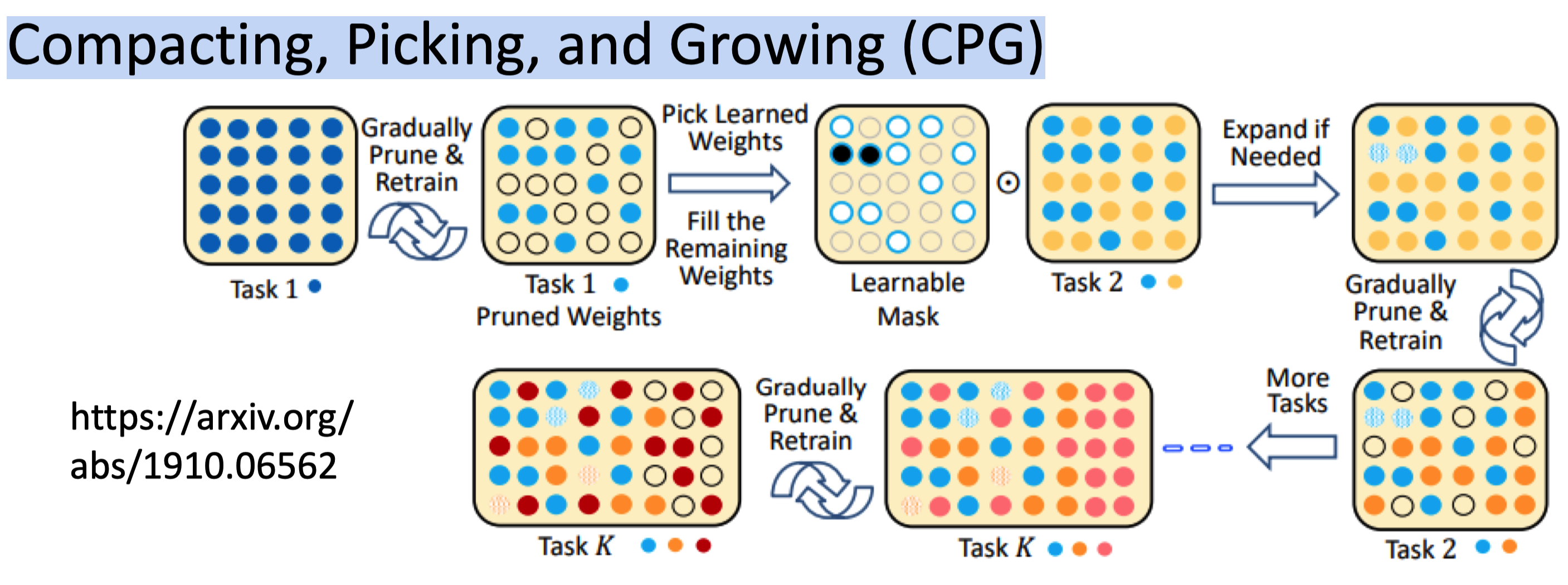
+ 上面两种方法结合
Ref
Life Long Learning