Contrastive Learning
一个完整的分类模型可以分为特征编码(Encoding)与分类(Classification)两个阶段
- 特征编码阶段 #card

- 分类阶段。#card
- 前一阶段提取出来的有效特征经过简单映射,就成为最终分类
常规机器学习中,特征编码与分类是由一个模型通过端到端学习来完成的。但是由于现在标注稀疏,我们只好将特征编码与分类在物理上拆分成两个独立的模型。
- 特征编码模型。#card
- 通过自监督学习方式来学习。所谓自监督学习,是指不依赖人工标注,通过挖掘未标注样本内部存在的结构、关联,将特征编码这个模型训练出来。
- 传统的降噪自编码器(Denoising AutoEncoder)(Word2Vec和Transformer通过句子的一部分预测另一部分)和这里要讲的对比学习,都属于自监督学习的范畴。
- 分类模型。#card
- 还是需要通过监督方式来学习。
- 但是由于特征编码阶段提取出来的有效特征的长度已经大大缩短,因此分类模型只需要少量标注数据就能被充分训练,从而缓解了标注稀疏的问题。
对比学习示意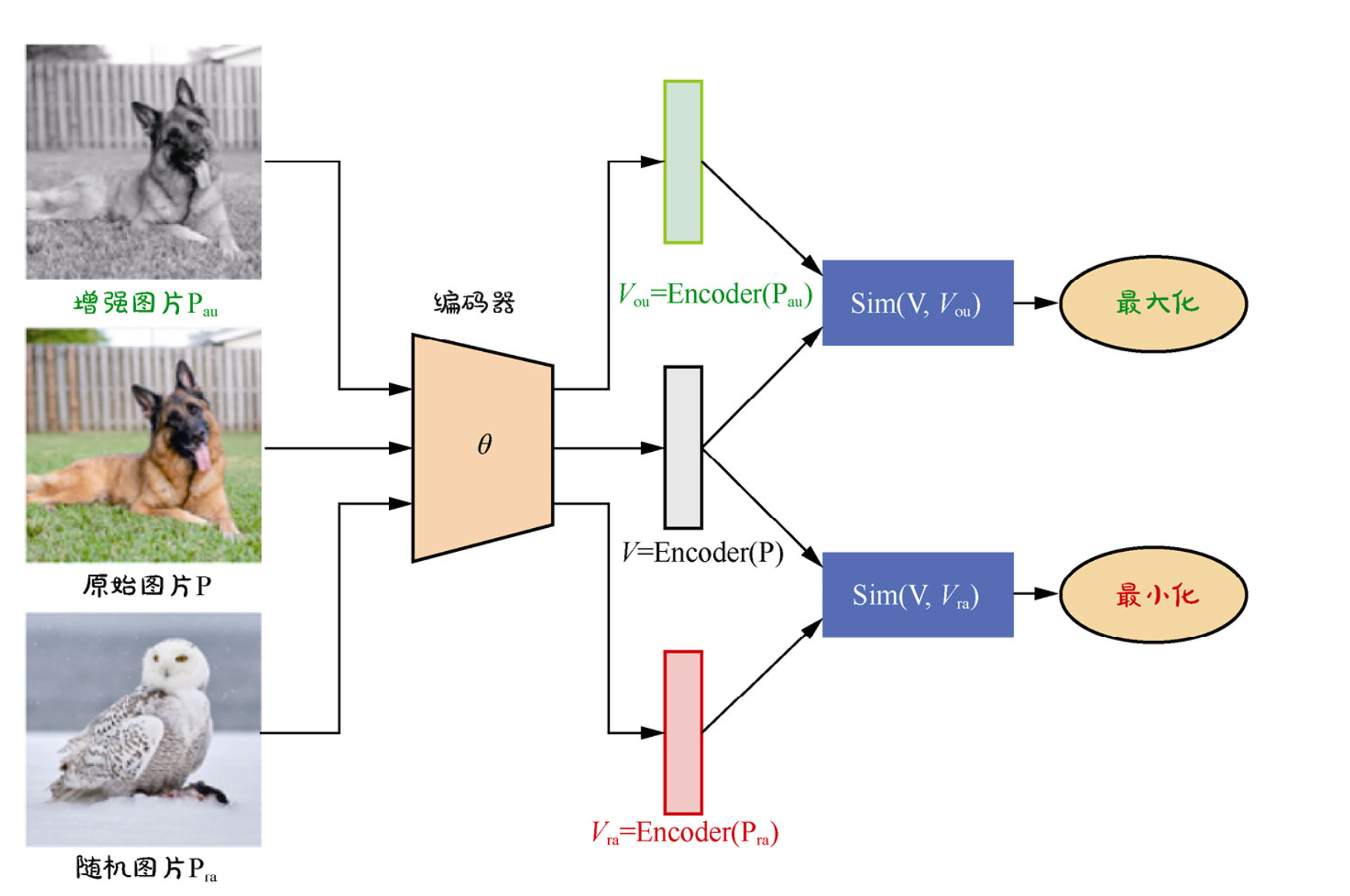
- 如何定义负样本
- CV
- 同一张图片进行裁剪和翻转成为两张正样本,其它图片是负样本
- CV
- 基于负例对比学习:[[MoCo]] MocoV2 MocoV3 SimCLR SimCLRV2
- 基于聚类的对比学习:以SwAV为代表,也是上下分支对称结构。
- 使用正例:其中一个代表模型BYOL,上分枝被称为Online,下分枝被称为Target,结构不对称;
- 更换了一个损失函数:代表模型是Barlow Twins,使用正例,结构对称,更换了损失函数,这个很有意思,可以看一下。
相关参考
Contrastive Learning