Spark Shuffle
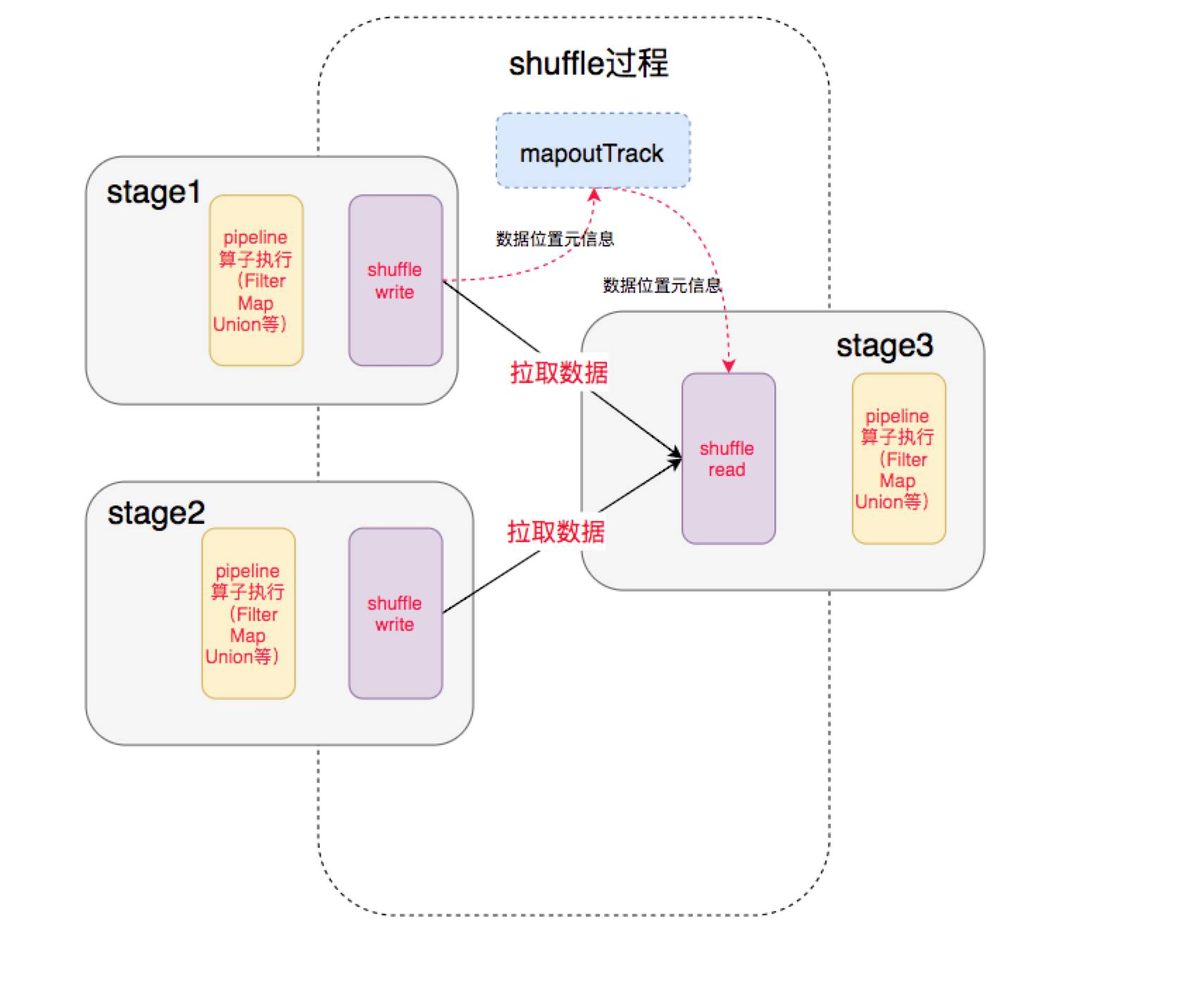
shuffle 过程发生在不同 stage 之间
- 前一个 stage 的 ShuffleMapTask 进行 shuffle write,把数据存储在 blockManager 上,把数据位置元信息上报到 driver 的 mapOutTrack 中
- 后一个 stage 根据数据位置元信息,进行 shuffle read,拉取上个 stage 的输出数据
shuffle 操作必须要落盘,所以操作性能低
分布在多个节点的同一个 key,拉取到同一个节点上,进行聚合或 join 操作。
- 相同的 key 会写到本地磁盘,然后其他节点通过网络传输拉取各个节点磁盘上相同的 key
- 处理key过多,导致内存不够存放,进而溢写到磁盘文件中。
- 大量磁盘文件读写 IO 以及数据网络传输
不同 ShuffleWriter
- BypassMergeSortShuffleWriter
- SortShuffleWriter
- 聚合算子:边聚合边写入内存
- 普通算子:直接写内存
- UnsafeShuffleWriter
- 序列化器KryoSerializer
- 直接在 serialized binary data 上 sort 而不是 java objects,减少了 memory 的开销和 GC 的 overhead
触发 Shuffle 的操作
- repartition 相关
- repartition
- coalesce
- ByKey
- groupByKey
- reduceByKey
- combineByKey
- groupByKey 和 reduceByKey 的底层实现
- 大概实现逻辑
- 遇到新 key 执行 createCombiner
- 遇到已有 key 执行 mergeValue
- 对所有分区执行 mergeCombiners
- aggregateByKey
- join 相关
- cogroup
- join
[[Spark 调优]]
- 减少 shuffle 次数
- 必要时主动 shuffle 改变并行度
- 使用 treeReduce & treeAggregate 替换 reduce & aggregate
[[Spark 数据倾斜]]
- shuffle 默认使用 [[HashPartitioner]] 对数据进行分片,可能造成不同的 key 分配到一个 task 上
spark.default,parallelism指定默认并行度
Spark Shuffle