相关性
相关性计算可以看作是query和item的匹配分计算
结构化信息匹配
电商搜索往往有比较完备的类目、属性体系,细致准确的类目和属性匹配(结构化信息匹配)可以简单有效提升query和item的相关性。#card
而结构化信息匹配依赖于query和item的结构化信息提取,如识别出query和item的类目和属性pv(如:property: 性别, value:女)。
query侧,类目预测一般使用统计或分类的方法来完成,属性pv的预测则可看作是序列标注任务。
对于item侧的结构化信息提取,除了使用和query理解类似的算法方法解决,更多的则是依靠商家或运营的维护。
在得到query和item的结构化信息后,在线可以进行结构化信息的匹配,并得到相应的相关性匹配分。#card
- 由于计算复杂度低,结构化信息的匹配特征往往被用在召回或海选阶段进行相关性过滤,作为最基本的相关性保障。
文本匹配特征
query和item
term匹配数、
query term的匹配率 = matched_term_num/query_term_num
item term匹配率 = matched_term_num/item_term=-num
带weighting的query term匹配率和item term匹配率
考虑了term权重和文档长度的BM25、考虑了term共现信息的紧密度和点互信息(PMI)特征、考虑用户行为的文本语义拓展
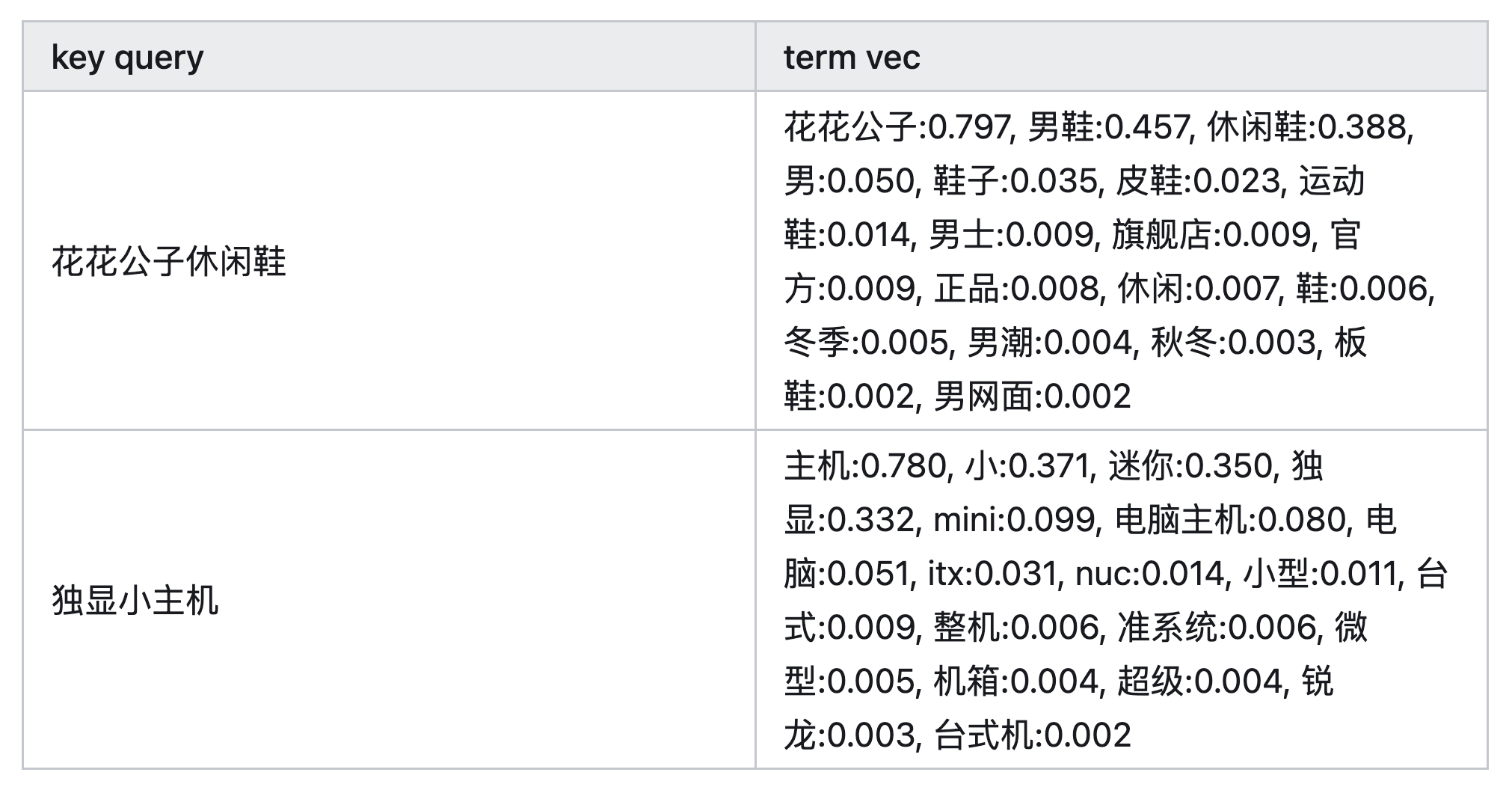
可以通过用户行为来拓展文本匹配特征,如:对于<query, item>点击pair对,通过协同过滤等方式,可以得到query2query的列表。聚合key query的所有相似query,并对query进行分词,对所有的term进行加权求和(权重可以为频次或q2q分数),归一化后得到query的表示: #card
语义匹配特征
解决问题 #card
- 基于文本的匹配特征虽然简单,但需要严格的term匹配,而对于同一个语义的多种表述,即使引入同义词信息有时也无法很好的解决。
隐语义匹配
- 隐语义匹配的核心思想是将文本表示成隐语义向量,并通过向量距离来度量文本之间的相似度。#card
与上述基于词袋模型的稀疏向量表示不同,隐语义向量是对文本主题或语义的隐式稠密表示。
经典的隐语义表示算法包括基于奇异值分解的潜在语义分析算法(LSA)、主题模型PLAS、LDA等。
而在Word2vec算法流行开来之后,基于词向量的隐语义文本表示(如:词向量的avg/max pooling作为文本向量、Doc2vec等)也取得了比较好的效果。
- 隐语义匹配的核心思想是将文本表示成隐语义向量,并通过向量距离来度量文本之间的相似度。#card
深度语义匹配
深度语义匹配通过神经网络方法进行文本的隐语义表示匹配,进一步又可分为表示型语义匹配和交互型语义匹配
#card 表示型语义匹配方法将query和item内容通过encoder网络分别表示成隐语义向量,并通过向量距离度量二者之间相似度。
表示行语义匹配网络多种多样,在训练方式上,可以使用pointwise方式或pairwise 方式,相应的在loss选择上一般有关注判别的MSE和CrossEntropy或者关注排序的TripleLoss等。
在网络结构上,主要在于encoder网络的不同如经典的DSSM、CNN、RNN以及近几点的BERT网络等。
交互型语义匹配则通过query和item的early fusion(query-item特征交互融合)来实现细粒度语义的匹配,提升匹配准确率。#card
- 经典的方法有ARC-II、MatchPyramid、ESIM、BERT等。
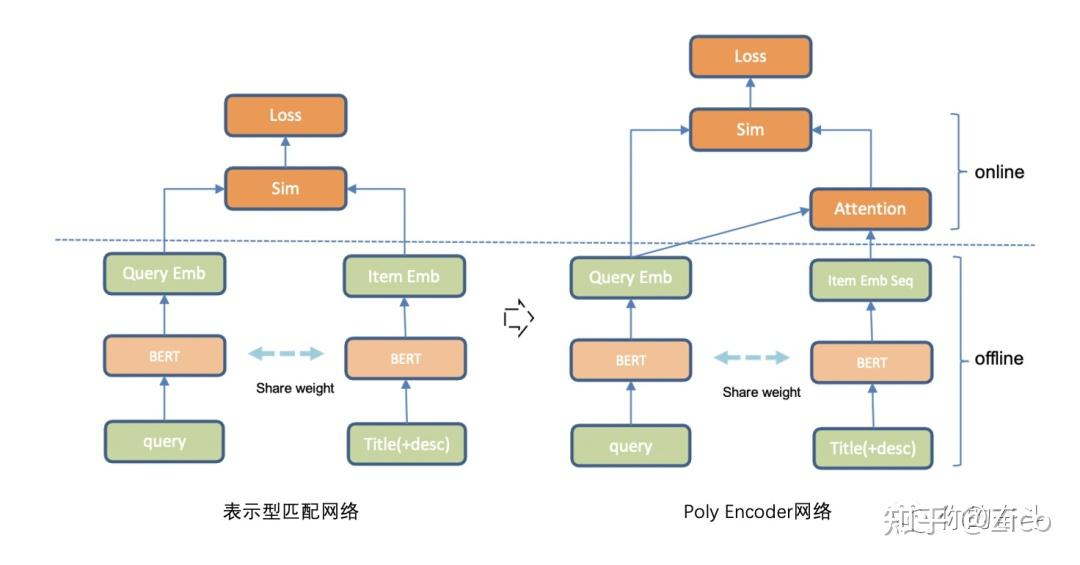
不同方法对比 #card
表示型语义匹配方法的优势在于离线和在线的分离,复杂模块离线计算,线上只需算向量距离,但相对交互型方法缺少细粒度语义信息的建模,准确率相对低;
同样,交互型方法虽然匹配准确率相对高,但也伴随着线上开销大的不足,尤其复杂的BERT模型。
而为了兼顾效率和准确率,也有很多折衷的方法,如:PolyEncoder、DeFormer等后融合(later fusion)方法,另一种常用策略则是模型蒸馏,如对BERT模型瘦身的DistillBert、TinyBert等。#card
多模态语义匹配
多模态的语义匹配框架和基于文本的深度语义匹配基本一致,不同点在于对多模态信息的编码方式,以图文匹配为例:#card
- 在表示型匹配架构下,通过经典的图像特征提取网络(如ResNet、Inception等)将图像提取为向量,再通过预训练或端到端的方式同文本Encoder模块表示一起进行语义匹配任务的训练。
在交互型匹配方式下,常用方法是将图像信息转换为向量序列,进而像处理文本匹配一样进行图文的语义匹配。#card
- 如经典的方案SCAN、VSRN等方法,通过Faster-Rnn等目标检测模型将图像提取为固定数量的region,region的特征向量序列作为图像的Embedding表示,进而作为多模态匹配网络的输入。
基于此,近两年多模态BERT的方法也同样有不错的效果(如VL-BERT、LXMERT、UNITER等)。#card
特征融合
在上述相关性特征基础之上,对众多特征进行融合往往可以进一步提升相关性指标,融合模型则采用经典的LR/GBDT/NN模型即可。
此外特征融合模型的训练一般使用人工标注的训练数据,同时为了标注方便可将相关性目标分为不同档位。#card
如四档模式下,在训练阶段,四个档位可映射到1、0.75、0.25和0四个分位,模型则通过回归或分类的方式对分位进行拟合。
由于该部分策略是对子特征的Ensemble,因此并不需要非常多训练数据,万级别基本可以满足需求。
其他
相关性优化任务方法
- 接到一个搜索场景的相关性优化任务后,首先要做的往往不是训练前沿的深度模型,而是进行系统现状分析,包括:技术现状分析和问题现状分析。#card
前者需要确定现有系统在相关性上已经有了哪些策略,相应策略的准确性和影响面有多大;
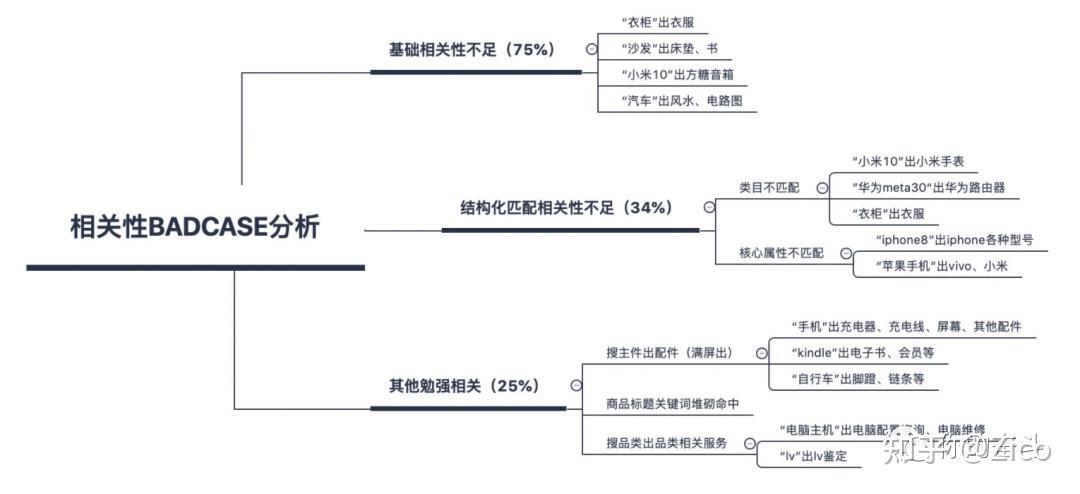
后者则需要通过badcase占比分析来定位头部问题,并进行优先解决。
如在项目启动阶段,如果发现大部分的问题case为明显的基础相关性不足和类目不匹配,应优先建立和优化基础的匹配策略。
通过简单高效的方式建立强baseline,同时保证阶段性效果提升,为后续优化奠定基础。而上述过程也往往是在效果优化的过程中不断循环往复的。
- 接到一个搜索场景的相关性优化任务后,首先要做的往往不是训练前沿的深度模型,而是进行系统现状分析,包括:技术现状分析和问题现状分析。#card
训练数据
数据往往决定模型的上限,相比于模型结构的选择和设计,深度匹配模型往往更加依赖大量的训练数据。而在缺少人工标注数据的积累的情况下,训练样本的构造也就变得十分重要。相应的训练数据的构造主要会面临两个问题:#card
高置信样本挖掘,避免搜索点击行为日志“点击但不相关”的问题。
定制化的负样本构造,避免模型收敛过快,只能判断简单语义相关性,对难样本无法很好的区分。
针对以上问题,常用的方法也很多,如:#card
正样本:充足曝光下高点击ctr样本(如:ctr大于同query下商品点击率平均值)
负样本:
- 同父类目的邻居子类目负采样。
高曝光低点击类目样本:同一个query搜索下,根据全局点击商品的类目分布,取相对超低频类目样本作为负样本。
充足曝光情况下,低于相应query平均曝光点击率一定百分比的样本做负样本。
基于query核心term替换构造负样本:如,对于“品牌A+品类”结构的Query,使用“品牌B+品类”结构的query做其负样本。
随机构造负样本:为增加随机性,该部分实现可在训练时使用同batch中其他样本做负样本,同时也可以引入经典的Hard Sample机制。
多因子融合
搜索算法最终的item排序往往是考虑多因子,而在电商搜索中比较重要的因子除了相关性因子,还有和业务直接相关的成交效率因子以及其他业务规则。
简化来说,对于相关性和成交效率因子,而二者的融合方式大致有三种:
相关性分数做档位分,下游根据相关性分层排序。#card
- 分档的方式可以做到分层排序,进而多因子解耦,调试方便高效;
相关性连续值score和效率score加权得到最终排序分。#card
- 相关性和效率分加权方法相对于分层排序,则可以更加综合地考虑相关性因子和效率因子,但确定合理的权重往往耗时耗力。
相关性和效率目标联合多目标优化。#card
- 多目标联合优化的方式在点击-成交模型中融入相关性因子,由数据和模型决定最终的商品排序,不需要人工干预,但可解释性差,且对相关性进行干预相对不够灵活。
相关性定义 #card