@Applying Deep Learning To Airbnb Search
[[Abstract]]
- The application to search ranking is one of the biggest machine learning success stories at Airbnb. Much of the initial gains were driven by a gradient boosted decision tree model. The gains, however, plateaued over time. This paper discusses the work done in applying neural networks in an attempt to break out of that plateau. We present our perspective not with the intention of pushing the frontier of new modeling techniques. Instead, ours is a story of the elements we found useful in applying neural networks to a real life product. Deep learning was steep learning for us. To other teams embarking on similar journeys, we hope an account of our struggles and triumphs will provide some useful pointers. Bon voyage!
[[Attachments]]
- Applying Deep Learning To Airbnb Search_2018_Haldar.pdf {{zotero-linked-file “attachments:Applying Deep Learning To Airbnb Search_2018_Haldar2.pdf”}}
记录 Airbnb 深度模型探索历程。
业务:顾客查询后返回一个有序的列表(Listing,对应房间)。
深度模型之前使用 GBDT 对房子进行打分。
Model Evolution
- 评价指标 [[NDCG]]
- Simple NN
- 32 层 NN + Relu,特征和优化目标和 GBDT 效果相同
- 打通深度模型训练和线上预测的 pipeline。
- LambdaRank NN
- [[LambdaRank]] 直接优化 NDCG
- 采用 pairwise 的训练方式,构造 <被预定的房间,未被预定的房间> 的训练样本
- pairwise loss 乘上 item 对调顺序带来的指标变化 NDCG,关注列表中靠前位置的样本
- 比如 booked listing 从 2 到 1 的价值比 books listing 从 10 到 9 的意义大。
- Decision Tree/Factorization Machine NN
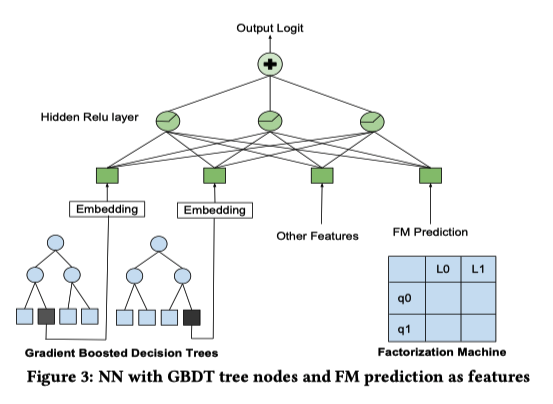
- GBDT 叶子节点位置(类别特征) + FM 预测结果放到 NN 中。
- Deep NN
- 10 倍训练数据,195 个特征(离散特征 embedding 化),两层神经网络:127 fc + relu 以及 83 fc + relu。
- 部分 dnn 的特征是来自其他模型,之间在 [[@Real-time Personalization using Embeddings for Search Ranking at Airbnb]] 里面提到的特征也有使用。
- 在训练样本达到 17 亿后,ndcg 在测试集和训练集的表现一致,这样一来可以使用线下的效果来评估线上的效果?
- 深度模型在图像分类任务上已经超过人类的表现,但是很难判断是否在搜索任务上也超过人类。一个关键是很难定义搜索任务中的人类能力。
Failed Models
- Listing ID
- listing id 进行 embedding,但是出现过拟合。
- embedding 需要每个物品拥有大量数据进行训练,来挖掘他们的价值
- 部分 Listing 有一些独特的属性,需要一定量的数据进行训练。
- listing id 进行 embedding,但是出现过拟合。
- Multi-task learning
- booking 比 view 更加稀疏,long view 和 booking 是有相关的。
- 两个任务 Booking Logit 和 Long View Logit,共享网络结构。两个指标在数量级上有差异,为了更加关注 booking 的指标,long view label 乘上 log(view_duration)。
- 线上实验中,页面浏览的时间提高,但是 booking 指标基本不变。
- 作者分析长时间浏览一个页面可能是高档房源或页面描述比较长。
- [[Feature Engineering]]
- GBDT 常用的特征工程方法:计算比值,滑动窗口平均以及特征组合。
- NN 可以通过隐层自动进行特征交叉,对特征进行一定程度上的处理可以让 NN 更加有效。
- Feature [[Normalization]]
- NN 对数值特征敏感,如果输入的特征过大,反向传播时梯度会很大。
- 正态分布
- $$(feature_val - \mu)/\rho$$
- power law distribution
- $$\log \frac{1+feature_val}{1+median}$$
- Feature distribution
- 特征分布平滑
- 是否存在异常值?
- 更容易泛化,保证高层输出有良好的分布
- [[Hyperparameters]]
- [[Dropout]] 看成是一种数据增强的方法,模拟了数据中会出现随机缺失值的情况。drop 之后可能会导致样本不再成立,分散模型注意力的无效场景。
- 替代方案,根据特征分布人工产生噪音加入训练样本,线下有效果,线上没有效果。
- [[神经网络参数全部初始化为0]] 没有效果,[[Xavier Initialization]] 初始化参数,Embedding 使用 -1 到 1 的随机分布。
- Learning rate 默认参数 [[Adam]] 效果不太好,使用 [[LazyAdam]] 在较大 embedding 场景下训练速度更快
- [[Dropout]] 看成是一种数据增强的方法,模拟了数据中会出现随机缺失值的情况。drop 之后可能会导致样本不再成立,分散模型注意力的无效场景。
- Feature Importance [[可解释性]]
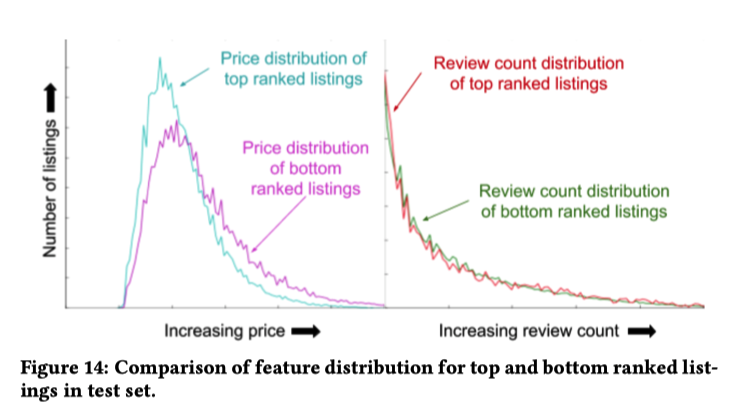
Score Decomposition将 NN 的分数分解到特征上。[[GBDT]] 可以这样做。Ablation Test每次训练一个模型删除一个特征。问题是模型可以从剩余的特征中弥补出缺失的特征。Permutation Test选定一个特征,随机生成值。[[Random Forests]] 中常用的方法。新生成的样本可能和现实世界中的分布不同。一个特征可能和其他特征共同作用产生效果。TopBot Analysis分析排序结果 top 和 bot 的单独特征分布- 左边代表房子价格的分布,top 和 bot 的分布存在明显不同,代表模型对价格敏感。
- 右边代表页面浏览量的分布,top 和 bot 的分布接近,说明模型没有很好利用这个特征。
 {:height 415, :width 716}
{:height 415, :width 716}
奇怪的东西
- 论文中一直在引用 [[Andrej Karpathy]] 的建议:don’t be a hero